AI時代において、GPUは欠かすことのできない重要なインフラです。しかし、GPUは高価で供給が不足しており、活用方法によって運用効率が大きく左右されます。本ホワイトペーパーでは、GPUを安定的かつ効果的に活用するためのモニタリングの必要性、運用の差別化要素、リソース管理戦略、モニタリング手法、そしてWhaTapでのアプローチを提示します。
Chapter 1. AIインフラとGPUの戦略的価値
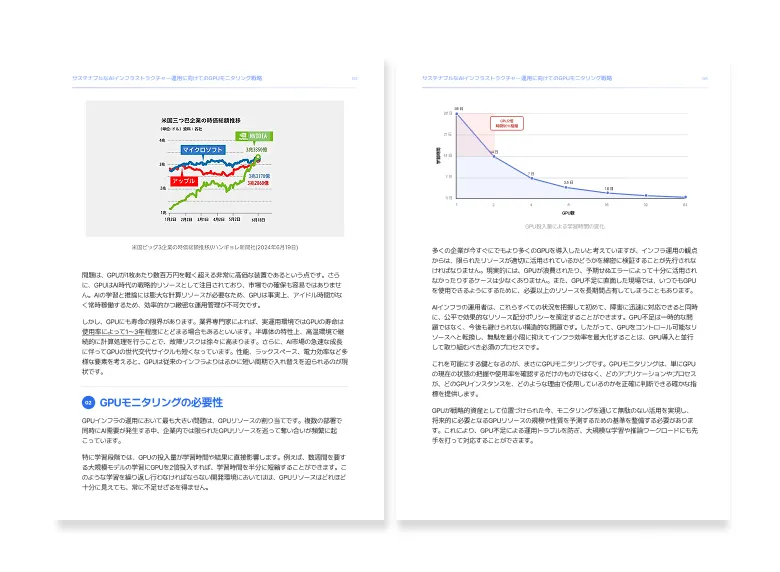
- AI時代におけるGPUの戦略的意義
- 爆発的に増加するGPU需要
- 高コスト/希少リソースがもたらす運用課題
Chapter 2. GPUモニタリングの必要性
- GPUリソース配分の問題と使用の不均衡
- 無駄を減らし効率を高めるモニタリング
- 事例:NERSC Perlmutterスーパーコンピュータ
Chapter 3. GPUモニタリングは何が違うのか
- GPUと従来インフラ管理方式の違い
- クラウド/ベアメタル方式の限界
- AIワークロード特化型モニタリングの必要性
Chapter 4. GPUリソース管理戦略
- 高性能GPU導入の効果と限界
- vGPU/MIGなどのリソース分割方式
- MIGによる物理的分離と安定性の確保
Chapter 5. GPUモニタリング手法
- ジョブスケジューラベースの管理と予測
- コンテナベースのオブザーバビリティアプローチ
- メトリクス/トレース/ログの統合分析
Chapter 6. WhaTapにおけるGPUモニタリングのアプローチ
- MIG/Kubernetes環境の統合モニタリング
- GPUトレンドおよびインベントリベースの管理
- Pod単位の追跡とリアルタイム異常検知
Chapter 7. GPUモニタリング、AIガバナンスの出発点
- 生成AIの拡大と不確実性の管理
- GPU運用戦略とコスト最適化
- ガバナンス構築における出発点
.svg)






%201.svg)






