.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
高価なのに短命なGPU。 だからこそ、必要なGPUモニタリング。

こんにちは、ワタップ・ジャパンです。 今回の記事では、最近のテック業界で最も注目されているキーワードであるGPU(Graphics Processing Unit、画像処理装置)とGPUモニタリングについて取り上げます。 GPUに関するニュースは、テクノロジー分野に限らず政治の分野でも頻繁に取り上げられており、各所で話題を呼んでいます。 例えば、2025年3月にChatGPTによるスタジオジブリ風の画像生成が世界中で話題になった際、OpenAIのCEOサム・アルトマン氏はX(旧Twitter)にこう投稿しました。
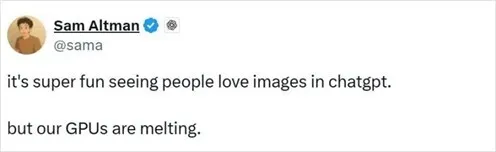
短い文ですが、AIとGPUの密接な関係を一瞬で理解できる表現でした。この投稿は、OpenAIのCEOであるサム・アルトマン氏が冗談っぽく言ったコメントです。ChatGPTで生成された画像が世界中で人気を集めていて、その負荷でGPUが“溶けるほど”使われている、という比喩的な表現です。 実際には物理的に溶けるわけではなく、「処理が追いつかないくらい忙しい」といったユーモアのこもった言い方です。
2025年5月14日、韓国政府は年内に1万枚のGPUを確保する計画を発表しました。さらに、2030年までに5万枚のGPUを確保するという選挙公約も掲げています。 こうした計画からも明らかなように、GPUはもはや特定の産業や一部のテック企業だけが扱う機器ではなく、国の競争力を左右する「戦略的資産」として位置づけられつつあります。 GPUインフラの確保と効率的な運用は、企業にとって重要な課題であるだけでなく、国としての未来の競争力を左右するカギにもなっています。 この記事では、GPUとは何なのか、そしてなぜこれほどまでに重要視されるようになったのかについて、一つずつ紐解いていきます。
GPUは、もともと3Dグラフィックスの高速処理に特化したハードウェアです。しかし近年では、その役割が大きく広がり、高性能コンピューティングの分野で不可欠な存在となっています。
GPUの構造には、数千もの演算ユニットを同時に活用できる並列処理能力があります。この特性によって、複雑な演算を迅速に処理することが可能となり、AI、機械学習、自動運転、映像レンダリング、シミュレーション、科学技術計算など、大規模なデータをリアルタイムで分析・学習する用途に広く活用されています。
CPUとGPUの違いについて疑問を持つ方も多いでしょう。CPUは汎用的な計算処理を担う「マルチタスクの専門家」といえます。一方GPUは、大量の演算を同時並行で高速に実行できる「並列処理の専門家」として位置づけられます。
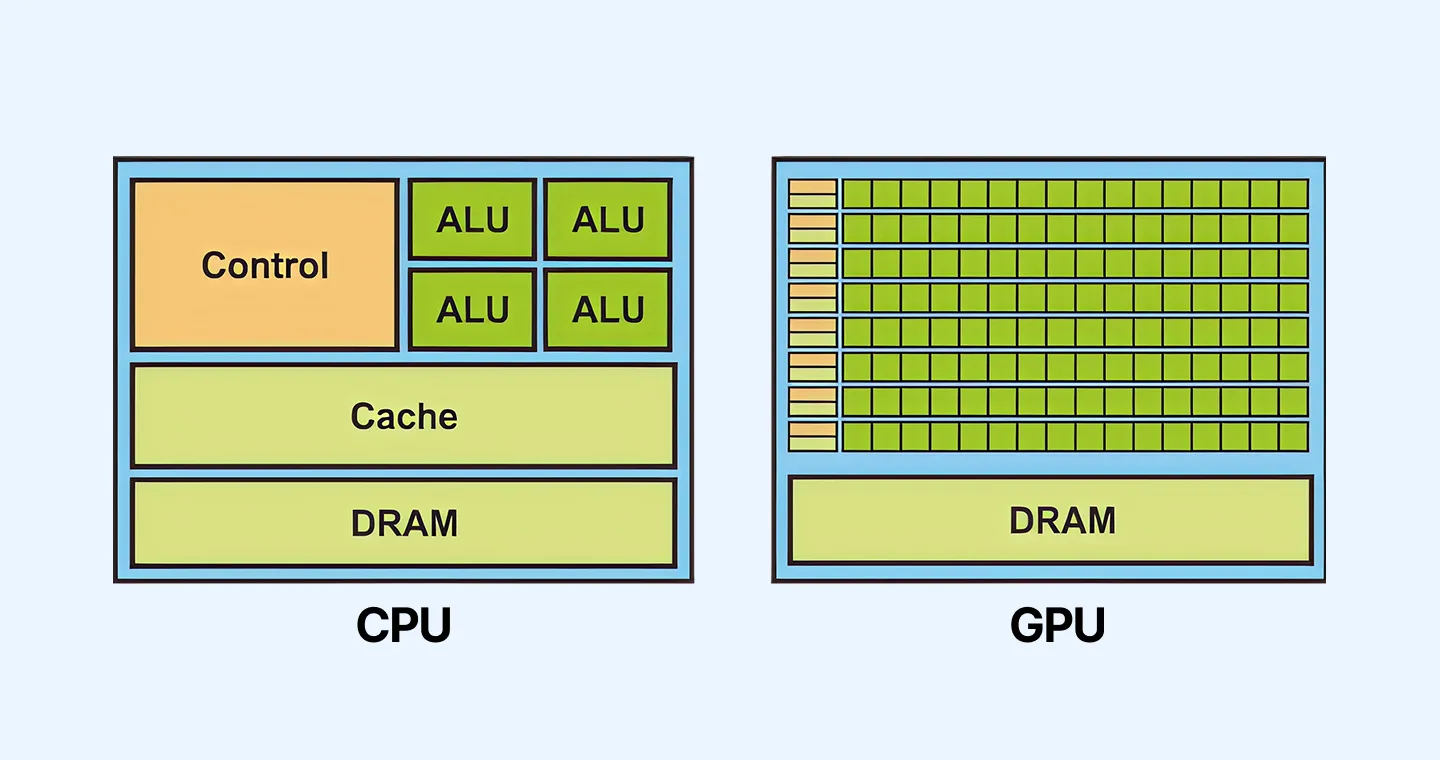
なぜ今、すべての視線がGPUに集中しているのか?
GPUへの関心が爆発的に高まっている背景には、人工知能、とりわけ生成型AIの急速な普及があります。 ChatGPT、Claude、Perplexityなど多くのAIサービスでは、数億から数千億のパラメータをリアルタイムで処理する必要があり、その膨大な計算量はもはやCPUでは対応できない領域です。 この複雑な演算を可能にするのが、まさにGPUの並列処理能力なのです。
さらに、扱うデータの量自体も急増しています。 最新のグローバルリサーチによると、2025年には1日に生成されるデータ量は約402エクサバイト(EB)に達すると予測されており、これは128GBのスマートフォンに換算すると約31億4000万台分に相当します。 こうした環境では、効率的で高速な演算処理を実現するGPUの存在がますます不可欠となっています。

急速に増え続けるデータを処理するために、高性能な計算リソースへの需要が急激に高まっています。そのなかで、GPUは最も有力な選択肢として注目を集めています。
さらに、クラウドサービスの発展がGPUの普及を後押ししています。 AWS、GCP、Azureといった主要なパブリッククラウドプラットフォームでは、GPUを「GPU as a Service」の形で提供しており、企業は物理デバイスを購入することなく、必要に応じて高性能GPUを利用できるようになりました。
このような環境変化により、GPUは一部のテック企業専用の装置ではなく、誰もが手軽にアクセスできる「戦略的資産」へと進化しました。現在も進行中の産業構造の変化は、GPUを単なるデバイスではなく、AI時代を支える重要なインフラへと位置づける流れを加速させています。
「高コスト、短寿命」:効率的なGPU運用の必要性
GPUは、一般的に非常に高価なデバイスです。たとえば、サーバー1台に搭載されるGPU1枚だけでも、数十万円から数百万円におよぶケースがあります。 クラウド環境においては、GPU使用料が時間単位で課金されるため、運用効率の差がそのままコストに直結します。
加えて、GPUは高温・高負荷の環境で稼働することが多いため、CPUに比べて寿命が短く、状態の変化にも敏感です。 そのため、安定した運用とコスト管理の両立には、GPUの適切なモニタリングとメンテナンスが不可欠です。
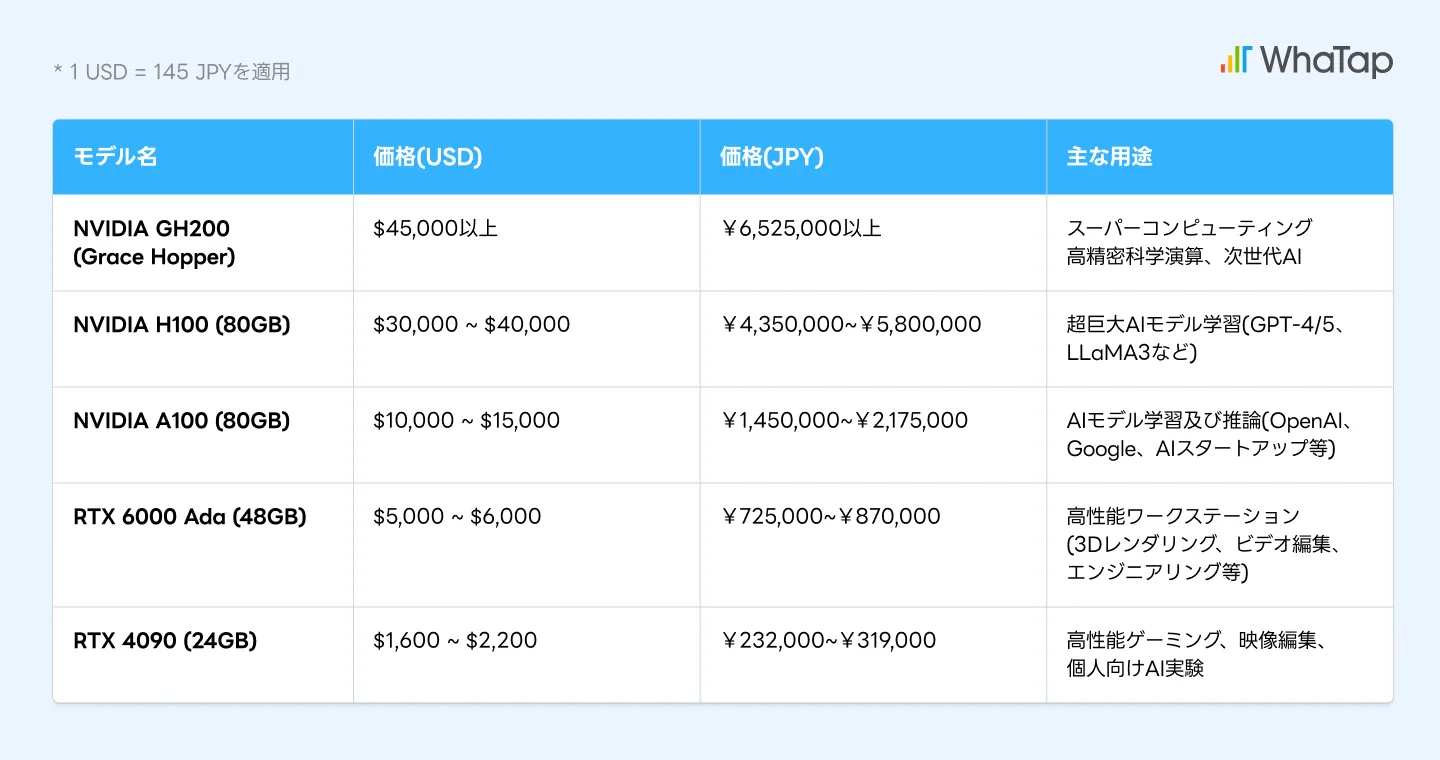
多くの組織では、高価なリソースを業務でどれだけ効率的に活用できているかを、正確に把握できていないという課題があります。 たとえば、GPUが「稼働中」と表示されていても、実際には処理を行っておらず、数十分から数時間にわたってアイドル状態になっているケースも少なくありません。
特に複数の部門がGPUを共有する環境では、どの部門がどれだけ使用しているかをリアルタイムで把握しない限り、リソースの偏りやボトルネックが発生しやすくなります。
さらに、GPUは高温や高負荷の条件下で動作するため、CPUよりも寿命が短い傾向があります。一部の企業ではGPUの寿命を1〜3年と見積もっており、この限られた期間で最大限の運用効率を求められる状況です。このような背景から、GPUの使用状況と状態を正確に把握し、リソースの無駄やボトルネックを早期に発見するための「運用の観測性と可視性」の確保が、ますます重要な課題となっています。
GPUモニタリングが必要な5つの理由
GPUは高価でありながら寿命が短いという性質を持つため、その状態や稼働状況を精密に管理することが欠かせません。 にもかかわらず、多くの組織ではGPUの「導入」に注力する一方で、「どのように運用するか」についての準備が不十分なケースが多く見受けられます。
GPUは非効率な使い方によって、直接的なコスト損失を生みやすいデバイスです。 こうした特性を踏まえると、リアルタイムで状態を把握し、利用状況を的確に管理できるモニタリング体制の構築は不可欠です。
この記事では、GPUモニタリングがなぜ重要なのか、その理由を5つの視点から解説します。

(1) 高価な資産であり、無駄は損失に直結
GPUサーバーは1台あたり数百万円にも及ぶ高額な投資です。クラウド環境では、使用時間に応じて継続的に課金が発生するため、運用効率が極めて重要になります。
しかし、GPUがアイドル状態にある、あるいは利用率が低いまま運用されている場合、それ自体が大きなコスト損失につながります。このような無駄を防ぎ、GPUの稼働効率を最大化するには、モニタリングこそが最も現実的かつ効果的な対策です。
(2) 寿命が短く、高い故障の確率
GPUは高温・高負荷環境で稼働するため、CPUと比べて故障率が高く、寿命も短い傾向があります。 Metaの調査によれば、データセンターにおけるGPUの年間故障率は約9%、3年間の累積故障率は27%に達しています。さらに、Tom's Hardwareによると、クラスター障害の30%以上がGPUハードウェアの故障に起因しており、同期間中に発生したCPUの故障はわずか2件にとどまっています。
一部の企業は、GPUの実際の使用寿命をわずか1〜3年程度と報告しており、限られた期間内で最大のパフォーマンスを引き出す必要があります。 そのためには、温度・電力・メモリ使用量などの指標をリアルタイムで監視し、障害の予兆をいち早く検知して対応する体制が不可欠です。
(3) AIタスクごとに異なるGPU使用パターン
AIにおける学習(トレーニング)と推論(インフェレンス)は、GPUの使用方法が根本的に異なります。 トレーニングは長時間にわたる高負荷な演算処理を必要とするのに対し、インフェレンスは短時間かつ高頻度なリクエスト処理を繰り返すことでGPUリソースを消費します。
このように、タスクの特性に応じてGPUの使用パターンが大きく変化するため、メモリ占有率や演算コアの使用率などを詳細に追跡する必要があります。GPUモニタリングは、こうしたワークロード特性を正確に把握し、リソースの最適配分を行う出発点です。 ボトルネックを回避しつつ、効率的な運用を実現するためには不可欠なプロセスといえるでしょう。
(4) 基本的なKubernetesツールではGPUのボトルネックを把握困難
近年、Kubernetes環境でAIワークロードを運用する企業が増えています。しかし、標準的なKubernetes(K8s)モニタリングツールはCPUやメモリの監視を前提に設計されていることが多く、GPUに関する情報取得は限定的です。
たとえば、Pod単位でGPUリソースがどのように割り当てられているか、どのプロセスがボトルネックを生じさせているのか、GPUの使用率がどう推移しているのかといった情報をリアルタイムで把握できなければ、リソースの浪費は避けられず、障害対応の迅速性も損なわれます。
GPUメトリクスの収集と可視化を行う専用の監視システムなしにKubernetesベースのAIインフラを運用することは、まるで計器盤なしで飛行機を操縦するようなものです。
(5) GPUは保有よりも活用が重要
GPUモニタリングは、単に使用量を数値で確認するだけではありません。 資産寿命の予測や障害の早期検知、さらには部門間のリソース競合の回避など、インフラ運用全体に影響を与える重要な要素です。特に複数のチームがGPUを共有するような環境では、モニタリングデータに基づいて、公正なリソース配分や効率的な運用ポリシーの策定が可能になります。
今や、「どれだけ保有しているか」ではなく、「どう運用し、どう活用するか」がGPU活用の成否を分けるポイントです。 GPUの状況を的確に「観測する力」は、組織全体のインフラ運用における信頼性と効率性を左右する、極めて重要な能力です。
終わりに: GPUは「可観測な資産」であるべき
AI時代の競争力は、いかに迅速かつ効率的にデータを処理できるかにかかっています。GPUはその処理能力を支える中核的なリソースです。
しかし、いくら高性能で高価なGPUを導入していても、「可視化されていない状態」で運用されている場合、その実力を十分に引き出すことはできません。GPUを組織の「見える資産」として管理・活用することこそが、インフラの信頼性と経営効率を高める鍵となります。これまで多くの組織では、nvidia-smiのようなCLIベースのツールを用いてGPUの状態を確認してきました。 この方法は単一サーバーでの運用においては有効ですが、GPUを数十台規模で運用するような大規模環境では限界があります。
リアルタイムでのモニタリングやアラート通知、ユーザーごとの使用履歴の追跡、さらに長期的なトレンド分析などを行うには、より高度な監視体制が不可欠です。 CLIツールのみでは、複雑化する運用ニーズに対応しきれないのが現実です。WhaTapは2025年7月、新たに「Kubernetes環境におけるGPUモニタリング」機能をリリースしました。 この機能は、企業が高価なGPUリソースを無駄なく、より効率的に運用できるよう支援することを目的としています。
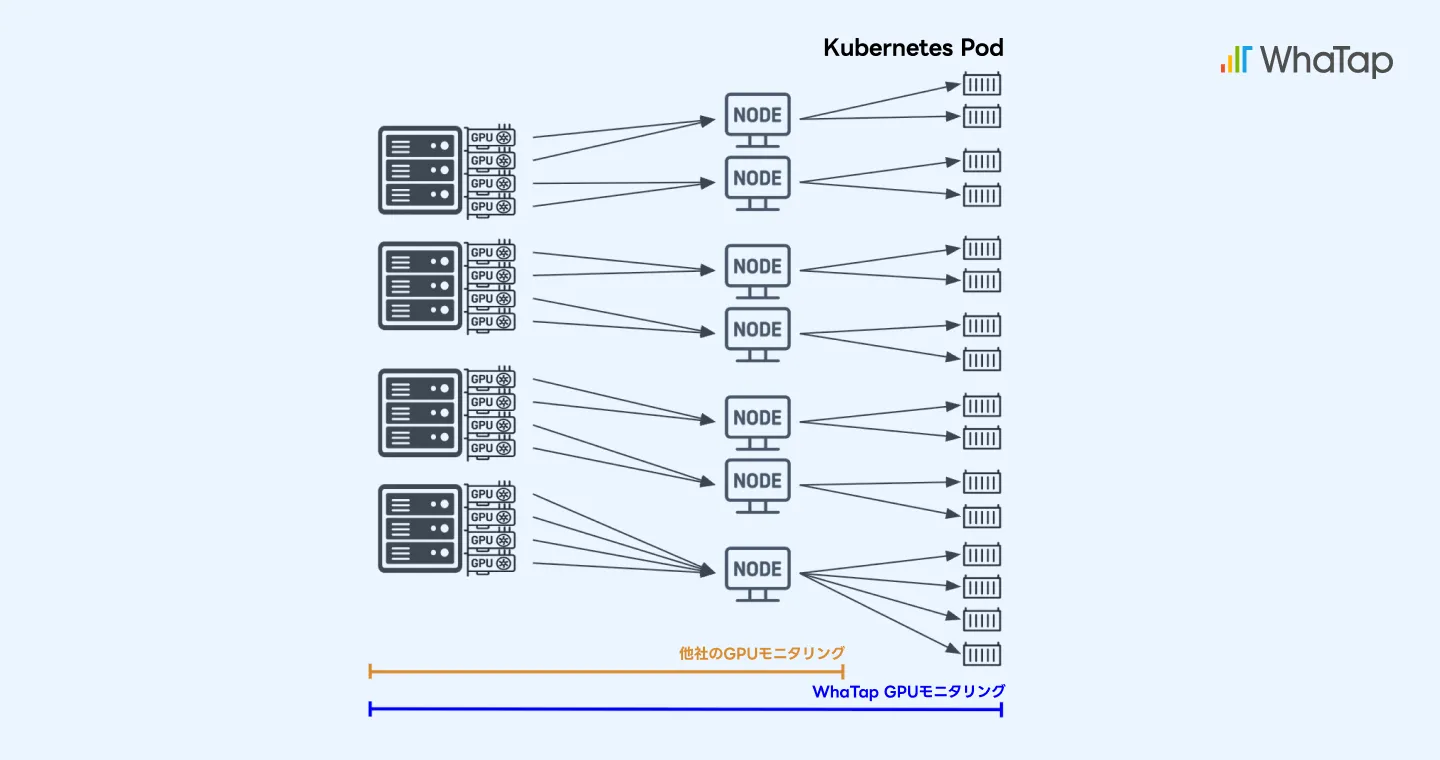
WhaTap GPUモニタリングの最大の強みは、GPUに関する単なる数値情報の提供にとどまらず、GPUからアプリケーションレベルまでの統合的なインサイトを提供できる点にあります。 これにより、実際のボトルネックの特定からリソースの最適化まで、一貫した運用管理が可能になります。
さらに、WhaTap GPUモニタリングは単なる状態確認を超えた価値を提供します。 コスト削減、パフォーマンス向上、障害の予防、チーム間のリソース調整といった多角的な面で、組織の競争力を高めるツールとして機能します。
GPUは「いつ、どのように、どれだけ効率的に使用されているか」が可視化されてこそ、戦略的資産としての真の価値を発揮します。WhaTapはその「見える化」により、GPU運用の新しいスタンダードを提示しています。
.png)

.png)




