.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
クラウド環境のDBモニタリング、 このように監視してみませんか!

こんにちは。IT統合モニタリングのWhaTap(ワタップ)です。
「決済エラーで困っています!」
このようなコンプレインがユーザーから届いた瞬間、IT運用担当者の緊張は一気に高まります。 しかし、原因の特定はそう簡単ではありません。アプリケーションログ、DBログ、クラウドコンソールのメトリクス等、複数のシステムを行き来して確認しますが、原因がDBロックなのか、非効率なクエリなのか、それともインフラのリソース不足なのかを判別は容易ではありません。

クラウドへの移行後、こうした状況はますます頻繁に発生しています。 かつては、1つの統合DBを管理すれば十分でした。しかし今では、サービスごとに異なるデータベースが使われ、クラウドDBとオンプレミスDBを並行するのも一般的です。管理対象は増える一方で、問題を解決するための時間は依然として限られています。
ここで、重要なのは、オンプレミスとクラウドを横断して、分散されたメトリクスやDBログがひと目で把握できることです。
今回の記事では、クラウド環境で複雑化したDBモニタリングの課題がどのように解決できるのか。そして、IT運用者が複数のコンソールやツールを行き来することなく、問題を迅速に特定し、解決する手法について紹介します。
クラウド以前と以後、変化したDB運用環境
かつては、システムの構造がシンプルでした。複数のサービスが1つの統合DBを共有しており、障害が発生するとシステム全体にその影響が及びました。 そのため、運用の重点は統合DBがいかに安定稼働できるようにモニタリングするべきかにありました。従来の3階層アーキテクチャではWEB/WAS/DBが明確に分離されており、モニタリングもサーバー監視/APM(アプリケーション監視)/DPM(データベース監視)のようにサイロごとに分けて管理することが可能でした。 インフラ環境が静的だったからこそ、この手法が成り立っていたのです。
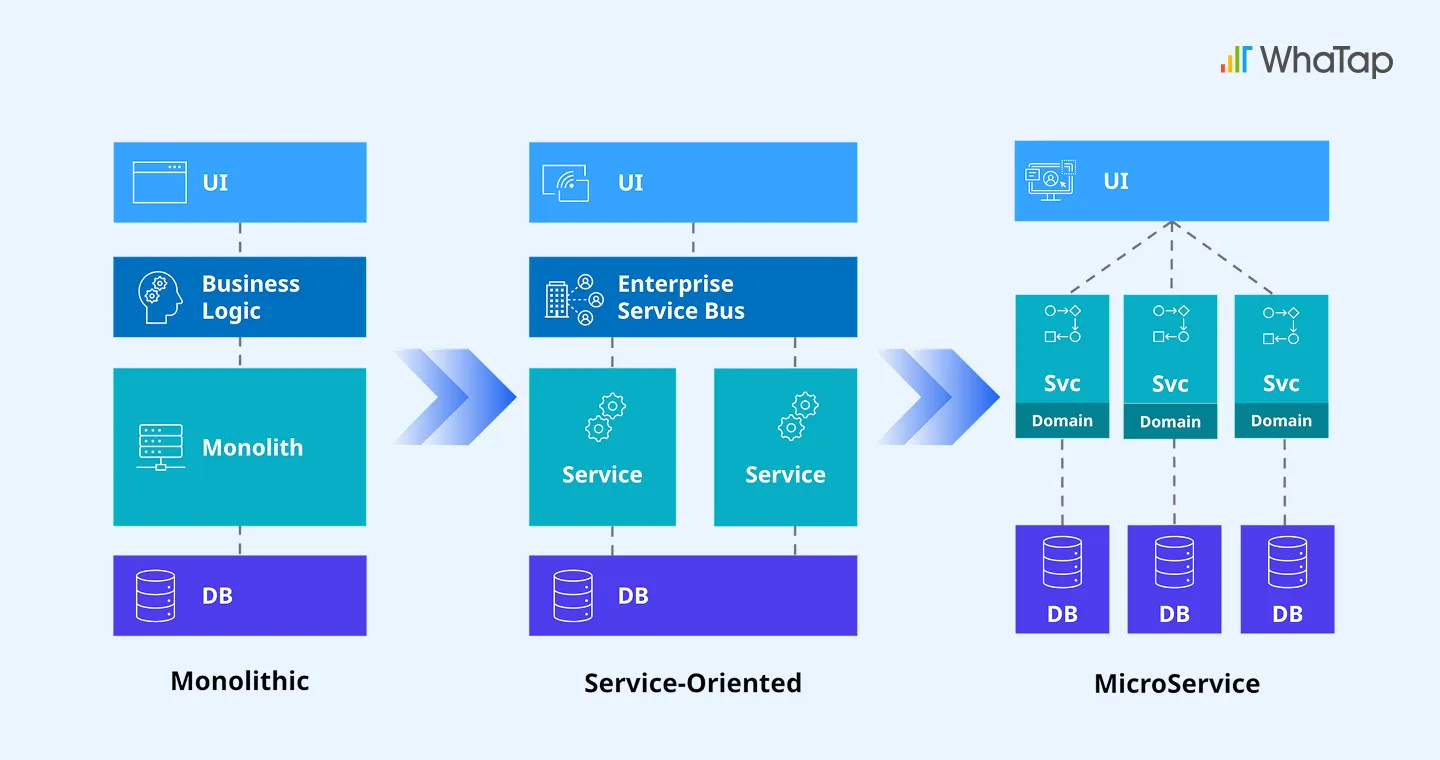
しかし、DX(デジタルトランスフォーメーション)とクラウドの拡大により状況は一変しました。MSA(マイクロサービスアーキテクチャ)が普及し、DB構造も小規模で多様になり、サービスごとに異なるDBやクラウドDBを利用するケースが増えつつあります。 今では、1人の運用者が複数のDBを同時に管理したり、開発者がDBAなしで自らDBを運用することも珍しくありません。
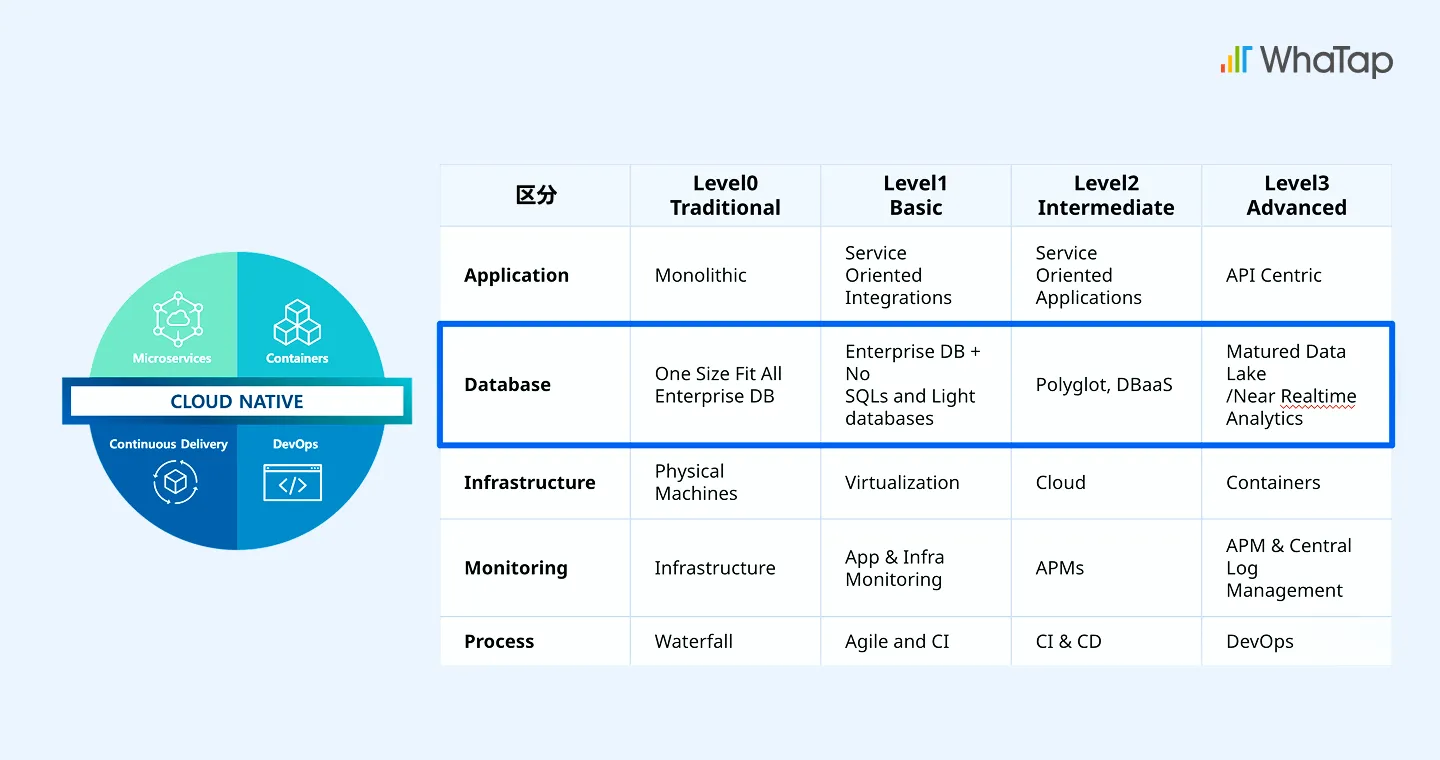
マイクロサービス化やクラウド移行が進む昨今の複雑な環境では、アプリケーション単体のモニタリングでは不十分です。実際に稼働するDBのフローや障害の有無まで追跡することで、ようやくシステム全体の因果関係が正しく把握できます。
すべてのアプリケーションがそれぞれ独立したDBを所有し、個別に追跡できるのであれば、APMだけでも十分かも知りません。 しかし現実はそうではなく、依然として複数のアプリケーションが1つのDBをシェアする場合が多く、特定のアプリケーションから実行された重いクエリ1つがサービス全体の障害につながることもあります。 だからこそ、アプリケーションとDBをそれぞれ独立した観点で監視と追跡することが、障害予防と迅速な復旧の観点から重要になってきています。
そこで問題なのは、APMとDPMを別々のツールで運用した場合、原因分析のために複数のコンソールを行き来しなければならず、対応が遅れる点です。 そのため最近では、アプリケーションとDBを1つのプラットフォームで統合モニタリングしようとする試みが注目されています。 これにより、システム全体が1つのつながった図として俯瞰し、原因特定の時間を大幅に短縮できます。
サイロ型モニタリングの限界と統合モニタリング
従来は、アプリケーションやインフラを個別に監視するサイロ型(区間ごと)モニタリングで十分だと考えられていました。しかしこうした分断されたモニタリング方式では、データ間の関連性を把握することが難しく、問題の根本原因を分析するにも限界があります。 システム内部で実際に何が起きているのかを正しく理解するためには、アプリケーションからDB、インフラまでを一貫して可視化する統合モニタリングが不可欠です。
監視対象ごとの監視に強み持ったモニタリングツールは多くあります。 しかし、アプリケーション/DB/インフラなどが区間ごとに別々として監視されており、複雑に絡み合った問題の根本原因を迅速に特定と解決するのは困難です。 そのため最近のトレンドとしては、アプリケーションを中心に因果関係を可視化し、複数のレイヤーを1つのフローとして統合的に監視するモニタリング手法への移行が加速しています。
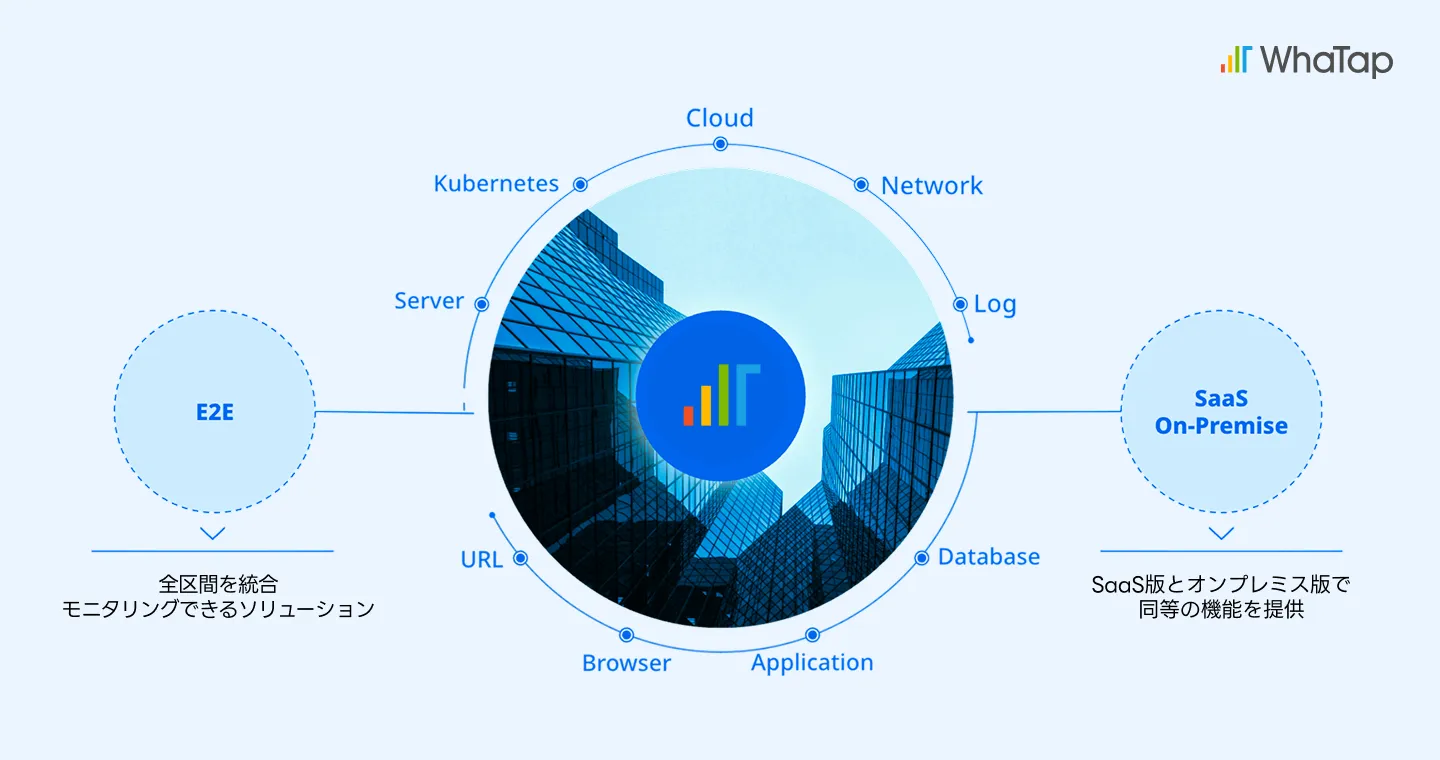
統合モニタリングを実現するために重要なのは、まず、①強力なデータ収集基盤の構築にあります。 サービスが生成するデータ量は指数関数的に増加しており、これを迅速かつ安定的に収集、保存、照会できる能力がモニタリングの信頼性を支える土台となります。 大規模データを扱うには、重複したデータは除去し、タスクの並列処理、スケールアウトといった技術的構造が不可欠です。更にクラウド環境に対しSaaS版として提供する場合には、数百テラバイト規模のデータでも支障なく処理しなくてはなりません。
次に重要なのは、②対応範囲の拡大です。 RDBMSはもちろん、NoSQL、AWS RDS、Azure Database、GCP Cloud SQL等といったクラウドDBまでをカバーできるモニタリングが必要です。 さらには、CloudWatchやAzure Monitor等からのクラウドメトリクスや、OpenTelemetry、Prometheusといったオープンソース環境から収集されたデータまで統合ビュー上で一元化して可視化する必要があります。 これにより、次々と登場する様々なDB環境にも柔軟に対応でき、将来的な技術変化にも耐えうるモニタリング基盤が構築できます。
もう一つの重要な要素は、③SaaSベースのモニタリング形式です。従来のオンプレミス方式では、リソース割り当てやストレージ管理など、運用負担が大きくなりがちでした。 一方、SaaS方式であれば、監視対象へエージェントを入れたりクエリーを投げたりするだけでデータ収集が可能となり、サーバーの管理やデータ保存はすべてSaaS側で行うため、運用担当者は収集されたデータの分析や対応といった本質的な業務だけに集中できます。 また、SaaSなら必要な期間だけサブスクとして利用できる柔軟性があり、小規模環境でPoC(概念実証)を行ってから本番環境へ拡大するというスモールスタート事例も増えています。
昨今のクラウド環境において求められるのは、単なるメトリクス収集を超えた 「オブザーバビリティ(Observability)」です。 オブザーバビリティとはシステム内部の状態を深く理解し、障害の原因を正確に特定できるようにすることです。オブザーバビリティによって、サイロ化したモニタリング環境から脱皮して、システム状況を横断的に観察することが可能になります。オブザーバビリティは、複雑化したクラウド環境において安定した運用を実現するためには欠かせない要素であり、今後のモニタリングの進化における重要な指針となります。
APMとDPMを横断する問題解決シナリオ
統合モニタリングとオブザーバビリティの重要性は理論的にも広く認識されていますが、実際の運用現場ではその価値をより深く実感できます。複雑に絡み合ったシステム環境では、単純なメトリクスだけでは問題の本質が見えづらく、アプリケーション・データベース・インフラを横断的に結び付けて可視化することで、初めて正確な原因特定が可能になります。
それでは実際の運用過程においてWhaTapモニタリングはどのように問題を把握し、解決を支援するのでしょうか。 代表的なシナリオをご紹介します。
[ケース①] 「決済が止まった!」 – インスタンスマップによる根本原因の追跡

コールセンターから「決済が進まない」という苦情が寄せられたら、IT運用担当は即座に状況の確認と原因分析に入ります。この際に、 WhaTap Database Monitoringが提供する「インスタンスマップ」は状況を迅速に把握できる出発点となります。アプリケーション、データベース、外部APIなどの構成要素が視覚的に整理されているため、通信経路や依存関係をひと目で確認でき、問題個所をスピーディに特定することが可能です。
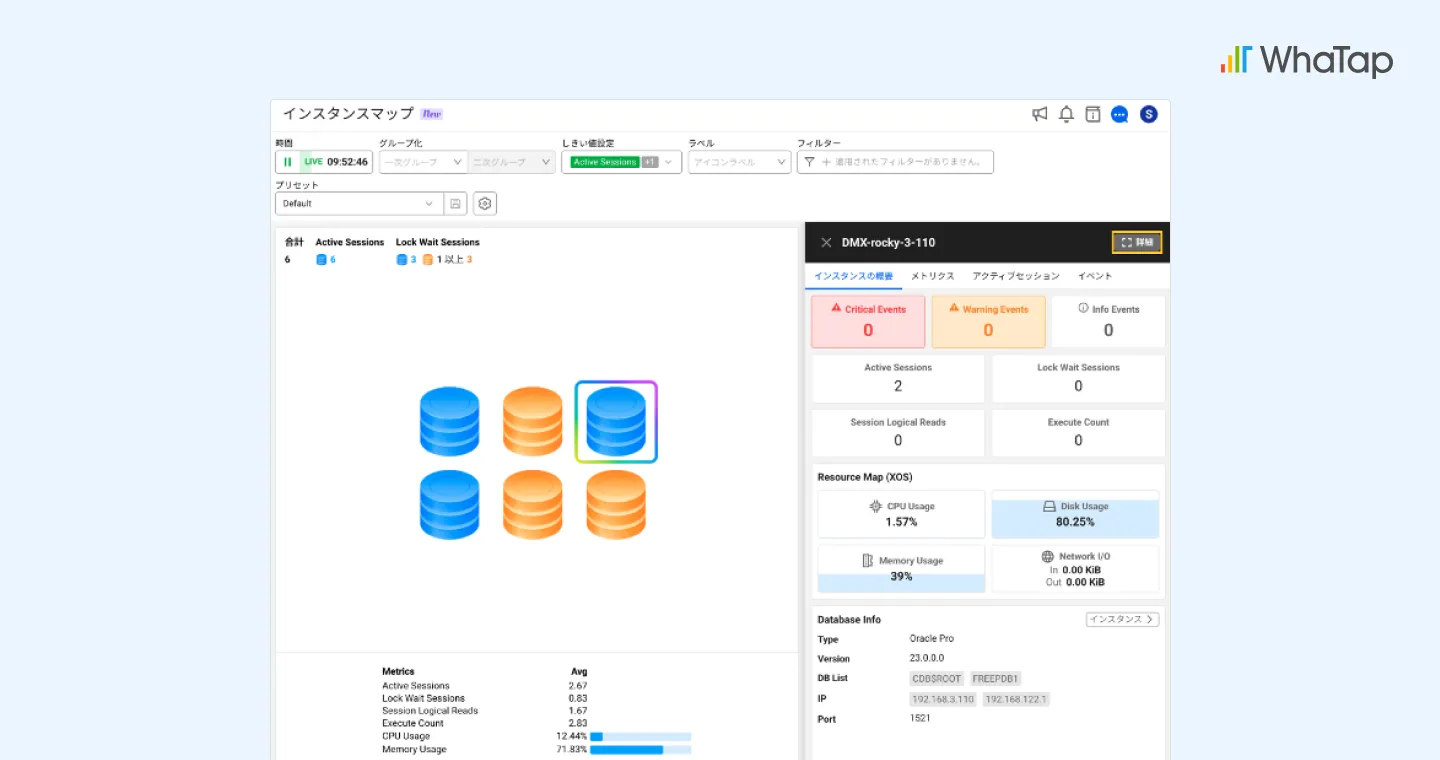
インスタンスマップでは、問題が発生したインスタンスが色で識別でき、クリックするだけで、その詳細が確認できます。 ロックツリーやSQL詳細、SQL統計、Wait別トップSQLなどの機能を通じて、どのクエリがボトルネックを引き起こしたのか、原因がフルスキャンなのか...といった情報を容易につかめます。さらに、システムが提供するプランガイドやチューニング向けのコメントにより、運用者が問題を解決するまでの時間を大幅に短縮できます。
[ケース②] 画面が遅い理由は? – アプリケーションとDBの連携

今度は少し複雑なケースです。 特定のイベントでトラフィックが集中し、画面のレスポンスタイムが急に遅くなった場合です。 WhaTap Monitoringではこの問題をAPMとDPMの連携分析で解決します。まず、APMダッシュボードから遅いトランザクションが特定できます。
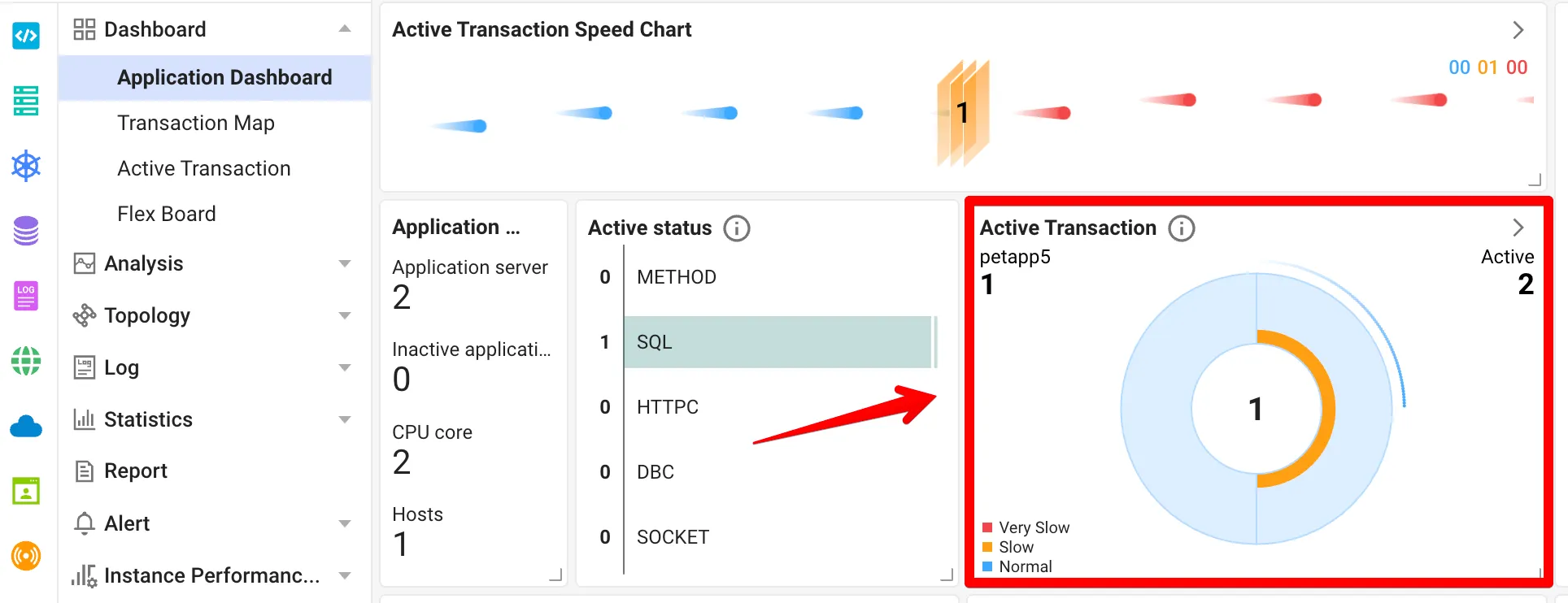
問題のクエリが見つかったら、「連携DBセッション」ボタンをクリックしてそのままDPM画面へ移動します。
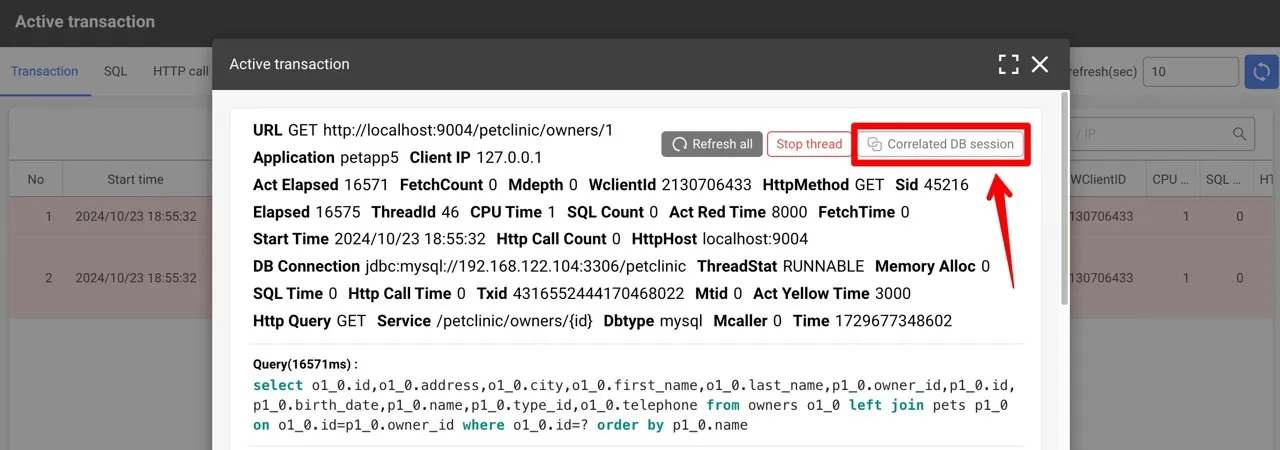
DPM画面では、DB内部でのロックやフルスキャンなど詳細な情報が確認できます。
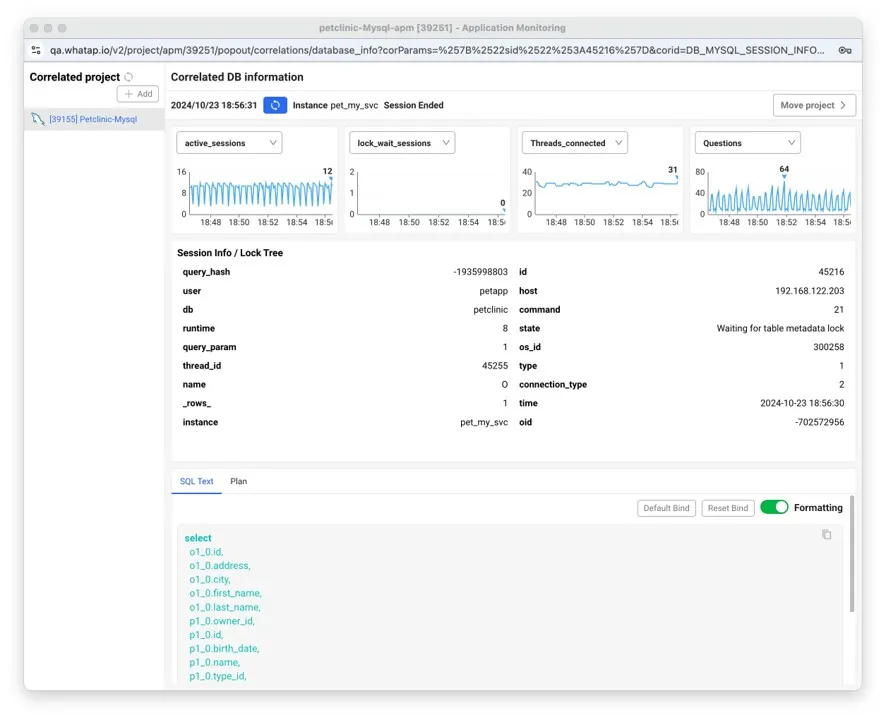
これは、特定のデータベースがどのアプリケーションと接続されているかを把握しづらいAP - DB環境においては大きく役に立ちます。 何よりアプリケーション担当とDB担当が互いに責任を押し付け合うのではなく、同じデータを1つの画面で共有することで、迅速かつ協力的な対応が可能になります。
この記事で紹介した2つの事例からのインサイトは明確です。統合モニタリングとは単にDBメトリクスを並べるツールではなく、問題の原因をデータに基づいて正確に特定し、迅速に診断できる体系であることです。 複雑なクラウド環境においてWhaTap Monitoringが提供する統合モニタリングは、運用する側に「全体が俯瞰できる視点」を提供。迅速かつ正確な問題解決を可能にします。
クラウドDBモニタリング、もう難しくない!
かつては、多様なDBMSとクラウド環境を同時に管理することは、運用者にとってハードルの高い課題でした。 オンプレミス、クラウド、そしてサービスごとに分散されたDBまでをカバーするには、多大なリソースと専門人材が必要だったからです。しかし今では状況が大きく変わりつつあります。
サービスが複雑化するほど、単にDBメトリクスを分析するだけでは不十分です。アプリケーション、データベース、クラウドリソースが密接に連携しており、一方の小さな障害が他の領域へ瞬時に波及します。 そのため、昨今の運用者に求められるのは「エンドツーエンド(End-to-End)可視性」、つまりシステム全体をひと目で貫く能力です。 これによって、問題の原因を正確に突き止め、迅速に解決することが可能になります。
WhaTap Database Monitoringは、こうした複雑な環境下でも運用者が試行錯誤を減らし、核心業務に集中できるよう実装されています。 オンプレミスとクラウドを網羅する多様なDBMSをサポートします。また、SaaS版とオンプレミス版のどちらも提供していますので、組織の環境やポリシーに合わせ柔軟に導入できます。
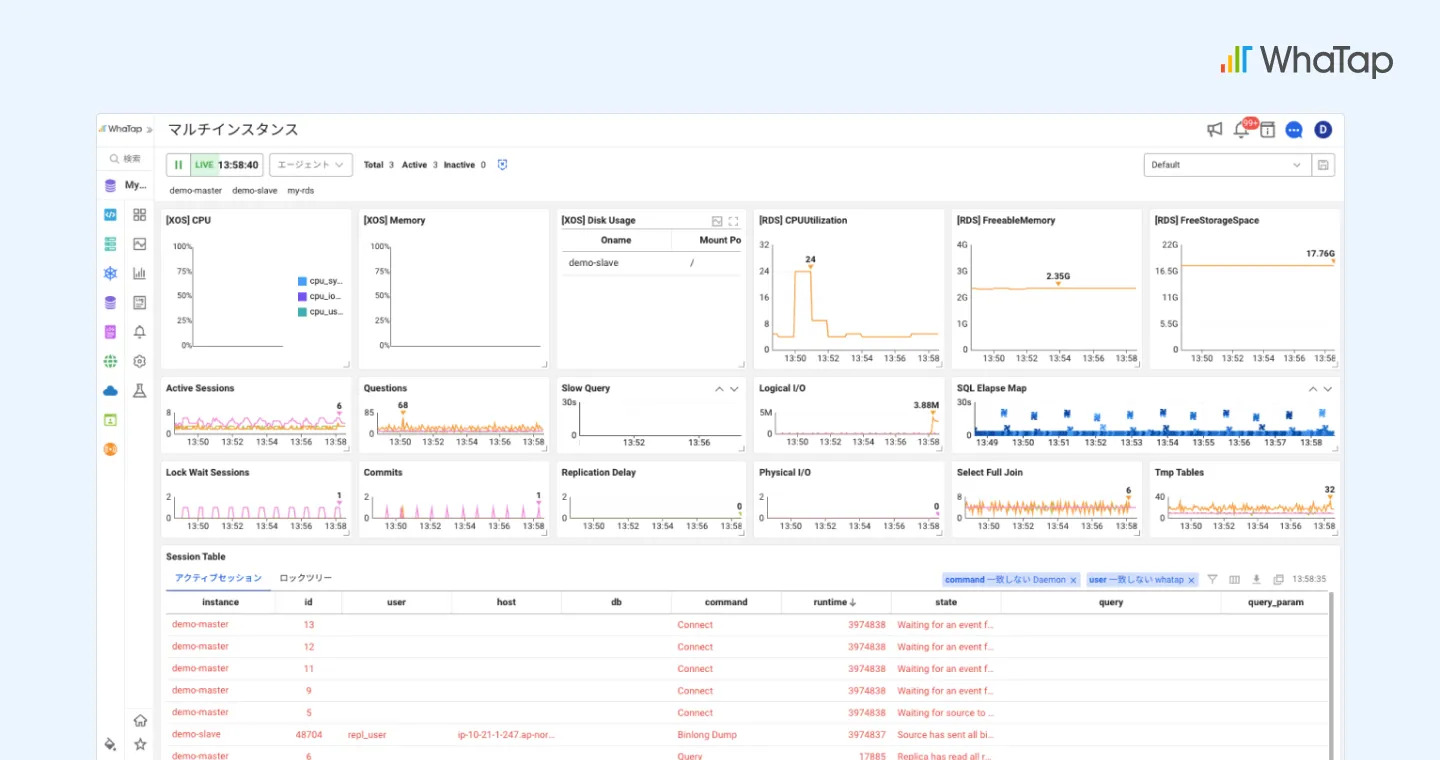
リアルタイム分析やSQLチューニングといった基本機能にとどまらず、アプリケーション ‐ DB ‐ インフラを連携した統合モニタリングを提供します。これにより、単なる問題対応を超えて、運用全体を俯瞰できる深いインサイトを獲得できます。クラウド時代の統合モニタリング、WhaTap Database Monitoringでその価値が今すぐ体験できます。
.png)

.png)




