.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
GPUモニタリングの際に、確認すべき主要指標とは?

こんにちは。AIネイティブ・オブザーバビリティ・プラットフォーム(AI-Native Observability Platform)、WhaTap(ワタップ)です。
2025年10月にKDDI、さくらインターネット、ハイレゾが日本におけるGPUコンピューティングリソースの安定供給体制の確立を目的とした「日本GPUアライアンス」を設立すると発表する等、GPUを中心とした日本国内におけるAIインフラストラクチャ市場は拡大しつつあります。IDC Japanの発表によると2029年の同市場規模は6,530億円で5年間のCAGRは5.7%にも上ります。
しかし、AIインフラの中心であるGPUは、単に保有量を増やすだけでは十分ではありません。GPUはとても高価で限られたリソースであるだけに、どのように運用・活用するかが企業競争力の鍵となります。
特に大規模なAIデータセンター環境では、GPUの過負荷や性能低下、非効率な利用といった問題を事前に検知し、最適化できる体系的なモニタリング体制が不可欠です。実際、GPU Monitoringを提供しているWhaTapにもGPUモニタリングに関するお問い合わせが去年と比べて大幅に増加しています。これは業界全体でGPU運用効率への関心が急速に高まっていることを示しています。
前回の記事では、GPUモニタリングの必要性について取り上げましたが、今回はさらに一歩進んで、以下の観点からGPUインフラ運用の新たな基準を提示します。
- GPUモニタリングツールに求められる6つの必須機能
- GPUモニタリングで注目すべき主要指標
- GPUモニタリングによって得られる期待効果
AIインフラストラクチャーにおけるGPUリソース最適化に向けて、ぜひご一読ください。
GPU、確保より「運用」がより大事!
今日のAI時代を支える核心インフラを一つだけ挙げるとすれば、それは間違いなくGPU(Graphic Processing Unit)です。
数千、あるいは数万を超えるコアで構成されるGPUは、単なるグラフィック処理装置を超え、さまざまな並列演算を実行する役割を担っています。特にこの並列処理の強みこそが、現在のAIモデルの学習と推論を可能にしている理由です。グローバル企業や通信キャリアが競うように大規模なGPUインフラを確保しているのも、このためです。
.webp)
しかし、GPUの確保はあくまで出発点に過ぎません。実際の導入・運用の過程では、次の3つの構造的な課題が伴います。
- 高価な設備:1台あたり数千万円に達するGPUも珍しくなく、クラウド上で利用する場合でもMIG対応GPUでは1時間あたり数千〜数万円のコストが発生します。
- 高い故障率と短い寿命:GPUはCPUに比べて障害発生率が高く、温度や負荷に敏感なため運用リスクが大きいです。
- 運用の複雑さ:GPUクラスタ間のネットワーク性能、Kubernetes環境でのワークロードスケジューリング、アイドルリソースの管理など、考慮すべき要素が多く管理難易度が非常に高いのが実情です。
したがって、企業がGPUへの投資を通じて競争力を高めるためには、高価な資産を安定的かつ効率的に運用できるGPUモニタリング体制が欠かせません。
モニタリングが欠如した状態では、高価なGPUが十分に活用されず、結果として大きなコストロスと競争力の低下につながります。
ここで自然と次の疑問が浮かびます。
- どのようなGPUモニタリングツールが必要なのか?
- そのツールを通じてどの指標を追跡・管理すればGPUの活用度を最大化できるのか?
次の章では、GPUモニタリングツールが備えるべき条件について詳しく見ていきましょう。
GPUモニタリングツールに求められる6つの必須機能
GPUを効果的に活用するためには、モニタリングツールが単にデータを収集するだけでなく、AIインフラ運用の基準を満たす6つの重要な要件を備えている必要があります。
① リアルタイムなデータ収集と可視化
GPUの状態と性能をリアルタイムで把握することは不可欠です。GPUは温度、使用率、VRAM使用量など、さまざまな指標を通じて稼働状態を示します。モニタリングツールはこれらのデータをリアルタイムで収集・可視化するだけでなく、過去の特定時点の分析や期間別パターンの追跡もサポートすべきです。これにより、運用担当者は問題を早急に特定し、即時対応が可能になります。
② Kubernetes環境との緊密な連携
GPUとKubernetesは切り離せない関係にあります。そのため、Pod、Container、Deployment、Job単位でGPUの利用状況が正確にマッピングされることが重要です。GPUの利用指標がKubernetes側のメトリクスやログと連携して分析されることで、ワークロード配置の効率化とリソース利用の最適化が実現します。
③ MIGの可視化と精密な測定
近年、多くの企業がMIG(Multi-Instance GPU)対応GPUを導入していますが、仮想化されたインスタンス内部の動きを把握することは容易ではありません。モニタリングツールはMIG単位まで詳細に追跡・測定し、実際の利用率と性能を正確に反映する必要があります。
.webp)
④ GPUリソース及びスペックの自動収集
組織が保有するGPUのスペック、利用目的、担当者をインベントリーとして一元化して管理することは基本です。モニタリングツールはGPUの構成情報と稼働状況を自動で収集し、管理データと連携できるようにする必要があります。特にMIGインスタンスごとに割り当てられた部門、担当者、用途を追跡することで、リソース管理の透明性を確保します。
⑤ 統計及びレポート機能
収集した詳細データと性能情報は、個々のGPU単位にとどまらず、組織の管理情報と紐づけて分析することで初めて意味を持ちます。これにより、効率性分析や短期、長期レポートの作成が可能となり、今後のGPU投資および運用戦略策定の根拠データとして活用できます。
⑥ アラート、レポート、ユーザー管理、セキュリティ機能の統合
GPUデータには企業の重要な資産情報が含まれるため、セキュリティ対策が必須です。また、GPU単体を監視するだけでなく、GPUを搭載したサーバー、ネットワーク、Kubernetesワークロード、アプリケーションログまでを包括的にカバーするモニタリングが求められます。
結局のところ、GPUモニタリングの本質は単に「見ること」ではありません。どのデータを、どのように解釈し、活用するかが鍵です。
次の章では、GPU運用担当者が特に注目すべき主要指標について詳しく見ていきます。
GPUモニタリングで注目すべき主要指標
GPUモニタリングによって得られるデータは非常に多様で、それらを総合的に分析することで、GPUインフラの健全性や効率性を多角的に把握することができます。特に以下の指標は、運用担当者が必ず確認すべき重要な領域であり、大きく3つのカテゴリに分類されます。
① 基本的な性能及び状態指標
GPUの安定性と性能を最も直接的に示す指標です。
- GPU使用率:GPUがどの程度活用されているかを示し、過負荷やアイドル状態の判断基準となります。
- GPU温度:過熱の有無を確認し、安定稼働を確保します。
- VRAM使用量:メモリ不足による性能低下を防止します。
- ログ情報:GPUおよびシステムで発生するイベントやエラーを追跡し、早期警告体制を構築します。
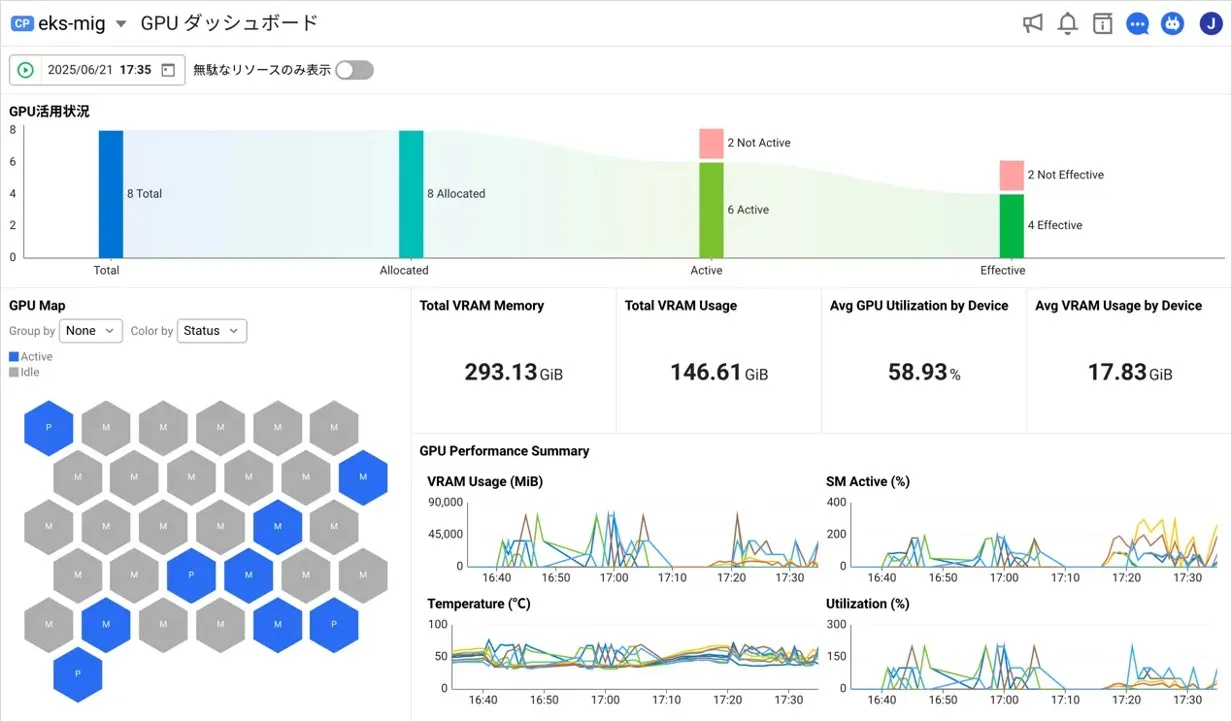
② Kubernetes連携指標
GPUインフラ運用において、ワークロード別の使用状況やリソース配置効率を把握するための指標です。
- コンテナ/Pod単位のGPU利用状況:ワークロードごとのGPU利用率を詳細に把握し、リソース配置の最適化に活用します。
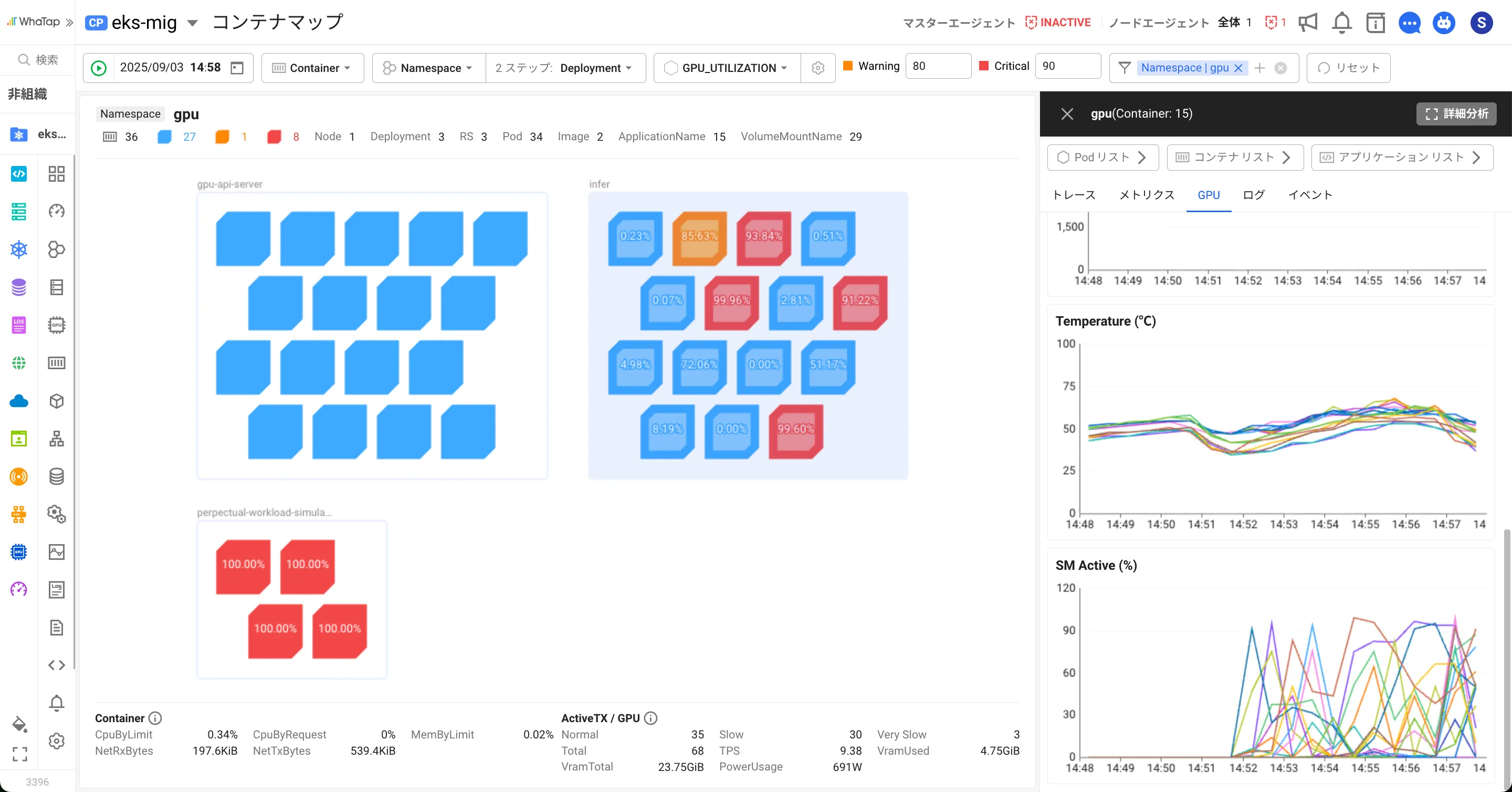
- アプリケーション内部データとの連携:Pod内のGPUアプリケーションのトランザクション、ログ、トレースデータを組み合わせ、実際のリソース利用状況を立体的に分析します。
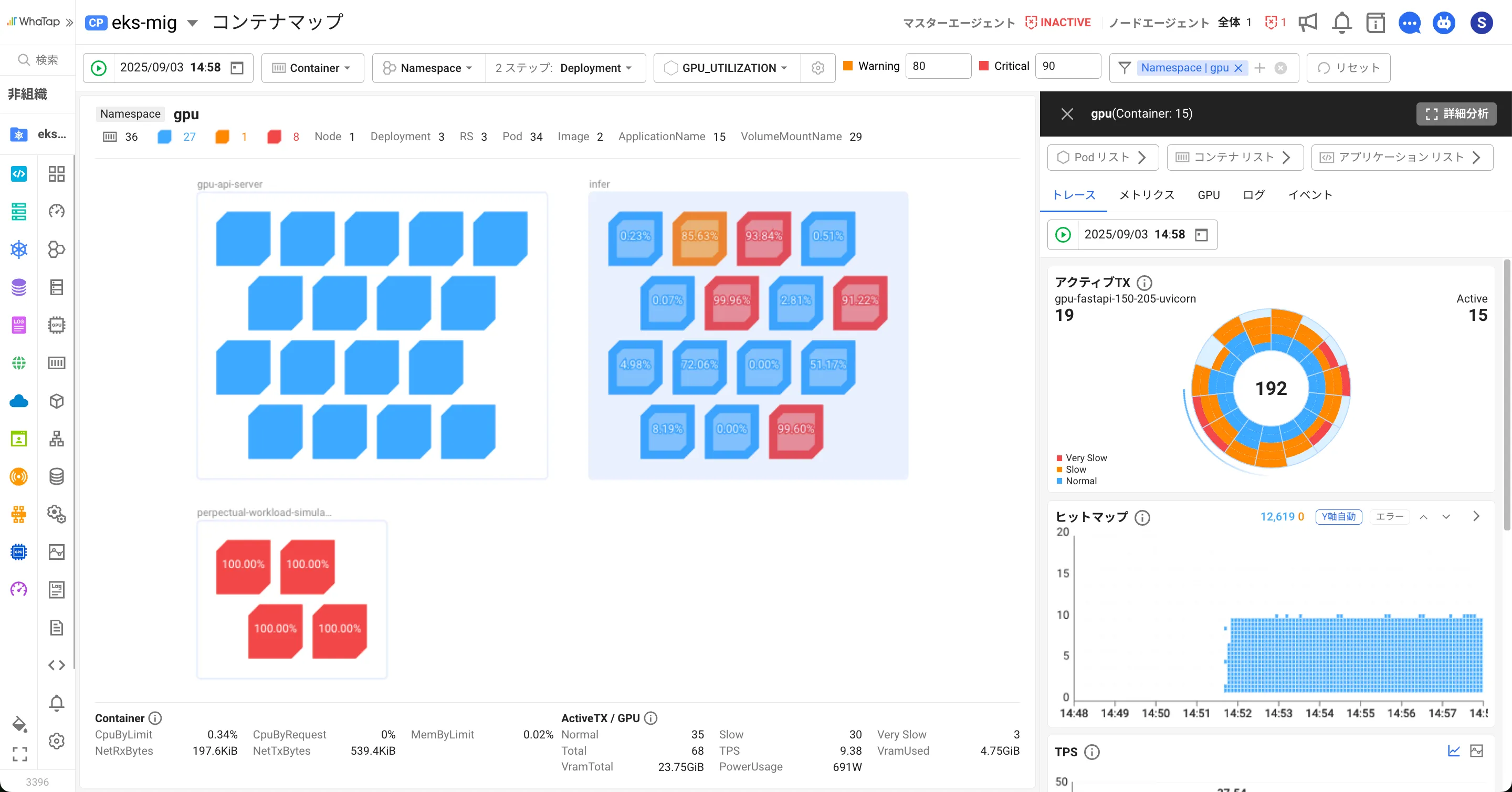
③ 統合分析及び効率性指標
GPU運用におけるコスト対効果や戦略的活用度を評価するための指標で、リソース配置や運用方針の最適化に役立ちます。
- 性能要約データ:主要な指標間の相関関係をチャートやグラフで可視化し、一目で全体状況を把握可能にします。
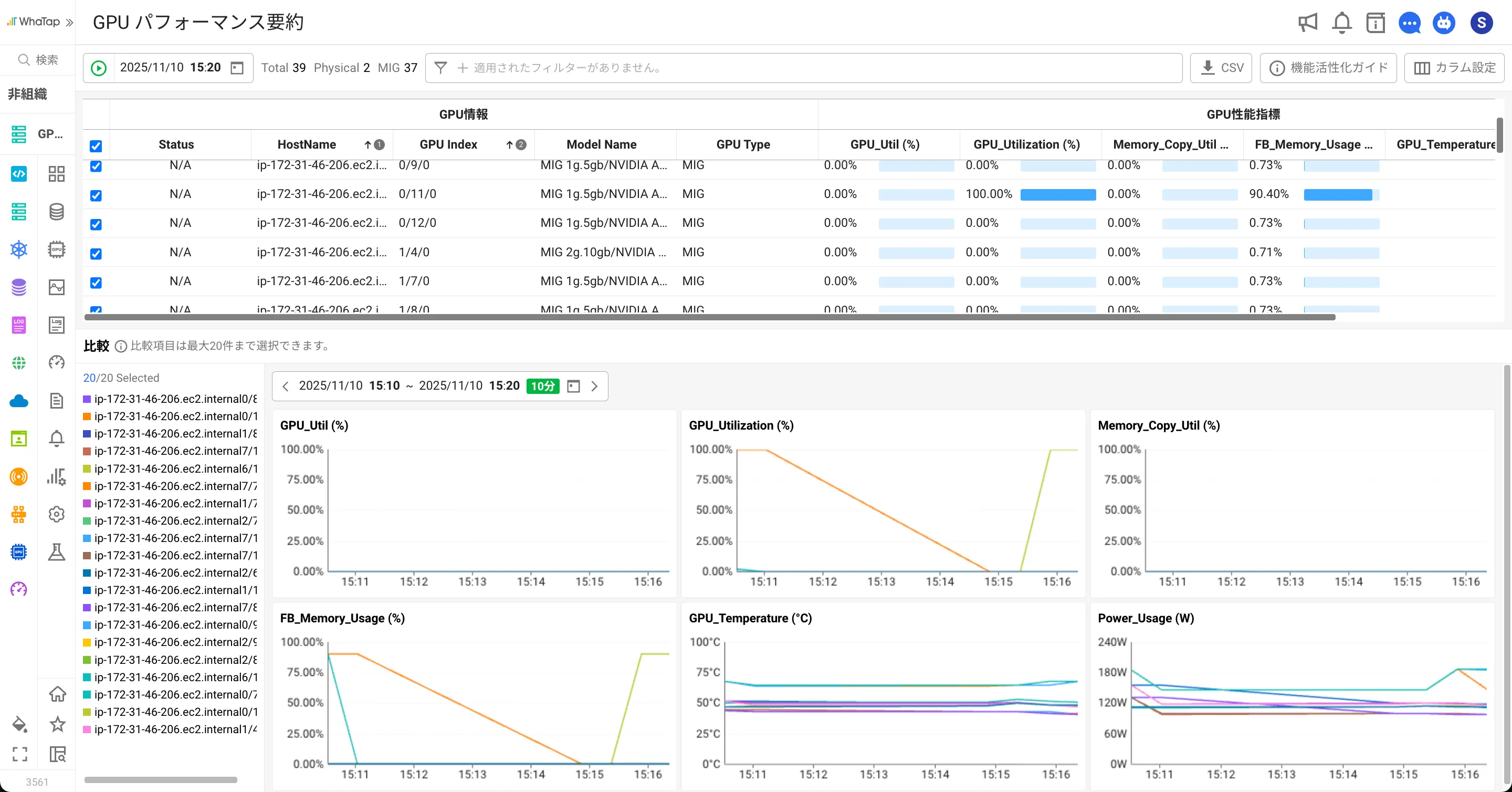
- GPUインベントリ情報:GPUごとのスペック、担当者、用途、所属部門などの管理データを自動収集及び連携し、資産単位での可視性を確保します。
- トレンド分析:時間帯、曜日、週ごとの利用パターンをヒットマップなどで可視化し、ピーク時やリソース利用の偏りを診断します。

- 低稼働GPUの追跡:ドリルダウン分析により利用率の低いGPUを特定し、コスト浪費を最小化します。
.webp)
- グルーピング及びフィルタリング:組織、担当者、使用率別の状況を分類し、カスタマイズされたインサイトを提供します。
- イベント及びアラート履歴:閾値超過や障害履歴を追跡し、再発防止および事後対応体制を整備します。
これらの主要指標を総合的に分析することで、GPUインフラの現状を正確に診断できるだけでなく、将来的な投資計画、運用ポリシー、リソース最適化戦略を策定するための根拠データを得ることができます。
GPUモニタリングはもはや運用補助のための手段ではなく、AIインフラ戦略の中核的な推進力となるのです。
GPUモニタリングによって得られる期待効果
体系的なGPUモニタリング体制を構築することで、企業は単なる運用の利便性を超えた戦略的な成果を得ることができます。
① コスト最適化と投資効果の最大化
GPUは1台あたり数千万円にも及ぶ高価な資産です。モニタリングによりアイドル状態のGPUを放置せず、利用率のトレンドを分析してスケジューリング戦略を最適化することで、リソース活用効率を最大化できます。これにより、投資効果の最大化と不要なコストの削減を同時に実現します。
② 安定したサービス運用の実現
GPUは障害発生率が高く、負荷に敏感な特性を持っています。モニタリングを通じてしきい値検知や定期的な指標チェックを行い、異常の兆候を早期に見つけることが可能です。さらに、イベント履歴を基に障害パターンを分析及び予防することで、GPUアプリケーションレベルまで追跡可能な運用の安定性を確保します。
③ 資産管理と合理的な意思決定
モニタリングシステムのインベントリ機能により、GPUのスペック、用途、担当者、部門といった情報を自動的に収集及び連携できます。これにより、企業はGPUの現状を正確に把握し、利用率の低いGPUを再配置したり、追加導入の是非を合理的に判断することができます。条件別のグループ化やフィルタリングを通じて、組織の視点に基づいたカスタマイズされたインサイトも得られます。
④ Kubernetes環境の最適化
GPUとKubernetesワークロードの連携はますます重要になっています。Pod、コンテナ単位でのGPU使用状況に加え、アプリケーション内部のトランザクションやログを統合的に分析することで、リソースの実際の割り当て状況を正確に把握できます。これによりボトルネックの解消が可能となり、複雑なAIインフラ全体の性能最適化を支える基盤となります。
まとめると、GPUモニタリングによって企業はAIインフラ投資の効果を最大化し、安定性と拡張性を同時に確保し、運用効率を戦略的資産へと転換する成果を得ることができます。
既存GPUモニタリングの限界とWhaTapのソリューション
GPUモニタリングの重要性は、誰もが認めるところです。しかし、実際の導入や運用の現場では、多くの企業がさまざまな課題に直面しています。一般的に検討されるGPUモニタリング手法には、次のような構造的な限界があります。
① メーカー提供ツールの限界
GPUメーカーが提供するユーティリティやCLI(Command Line Interface)は、特定時点のスナップショットデータしか取得できません。過去データの追跡や長期的なトレンド分析ができず、GPUの台数が増えるほどデータの集約及び管理負担が急増します。さらに、サーバー、Kubernetes、GPUアプリケーションを横断した統合的な可視化は難しくなります。
② オープンソース活用の複雑さ
オープンソースを利用すれば柔軟性は確保できますが、データ収集、保存、可視化、レポート、アラートなど、各領域ごとに個別のソフトウェアをインストール及び運用する必要があります。GPU管理者が本来の業務に加え、モニタリング環境全体を維持する負担を負うことになり、データ処理方式の不一致により総合的な分析や管理情報との連携が困難になります。
③ 汎用GPUモニタリングツールの限界
市販のGPUモニタリングツールの中にはユーザビリティに優れたものもありますが、多くはGPUそのものにしか焦点を当てていません。GPUが搭載されたサーバー、ネットワーク、Kubernetes、アプリケーションログまで含めたフルスタックモニタリングを実現できるかどうか、慎重に見極める必要があります。
こうした課題を解決するために、WhaTapはGPUモニタリングの新しいスタンダードを提案します。
.webp)
WhaTap GPU Monitoringは、単なるメトリクスの一覧表示にとどまりません。GPUそのものに加え、インフラ、ネットワーク、Kubernetes、アプリケーションまでを包括するエンドツーエンドのフルカバレッジインサイトを提供します。さらに、ログや最適化データも統合することで、企業がGPUを最も安定的かつ効率的に運用できるよう支援します。
WhaTap GPU Monitoringの詳細はこちらからご覧ください。
今回の記事では、GPUモニタリングツールに求められる必須機能、運用担当者が注目すべき主要指標、そしてGPUモニタリングによって企業が得られる期待効果について説明しました。
結論として、GPUモニタリングはコスト最適化や安定稼働のためのツールにとどまらず、AIインフラストラクチャーの競争力を左右する中核戦略です。
自社のGPUインフラが真の競争優位へとつながるよう、今こそモニタリング体制を見直すタイミングです。
.png)

.png)




