.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
Kubernetes Pod의 메모리 사용량이 계속 증가한다면? Container 메트릭 완벽 가이드

이 글은 와탭이 외부 필진과 협력하여 제작한 콘텐츠로, 현업에서 활동하는 전문가의 경험과 인사이트를 독자 여러분께 전달하고자 합니다.
Kubernetes 환경에서 애플리케이션을 운영하다 보면 누구나 한 번쯤은 당황스러운 상황을 마주하게 됩니다. 분명 메모리 제한을 2GB로 넉넉하게 설정했고, 모니터링 대시보드는 80%의 사용률을 보여주는데, Pod가 OOMKilled로 재시작되는 것입니다. 이러한 문제는 단순히 메모리를 더 할당한다고 해결되지 않습니다. 근본 원인은 Container 환경의 메모리 메트릭을 정확히 이해하지 못했기 때문입니다.
이 글에서는 Container 메트릭의 기술적 배경부터 JVM 애플리케이션의 특수성, 그리고 실제 운영 환경에서 바로 적용할 수 있는 방법까지 다루고자 합니다.
Container 메트릭의 기술적 이해
Linux cgroup과 메모리 격리
Container 기술의 핵심은 Linux 커널의 cgroup(Control Group) 기능입니다. cgroup은 프로세스 그룹의 리소스 사용을 제한하고 격리하는 메커니즘으로, Container는 이를 통해 독립된 환경을 구성합니다.
Container 내부에서 전통적인 방식으로 메모리 정보를 확인하면 예상과 다른 결과를 보게 됩니다. /proc/meminfo는 여전히 Host 시스템의 전체 메모리를 보여주기 때문입니다. 이는 많은 애플리케이션, 특히 JVM이 잘못된 메모리 설정을 하게 만드는 주요 원인이 됩니다.
# Container 내부에서 확인 - 잘못된 접근
$ cat /proc/meminfo | grep MemTotal
MemTotal: 16777216 kB # Host의 16GB가 표시됨
# 올바른 Container 메모리 제한 확인
$ cat /sys/fs/cgroup/memory/memory.limit_in_bytes
2147483648 # 실제 설정된 2GB 제한실제 Container의 메모리 사용량과 제한은 cgroup 파일 시스템을 통해 확인해야 합니다. 이 차이를 이해하는 것이 Container 환경에서 안정적인 메모리 관리의 시작점입니다.
memory.usage_in_bytes vs memory.working_set_bytes
Kubernetes 환경에서 가장 혼란을 일으키는 부분은 이 두 메트릭의 차이입니다. 많은 개발자들이 memory.usage_in_bytes를 모니터링하다가 예상치 못한 OOMKilled를 경험하는 이유가 여기에 있습니다.
memory.usage_in_bytes는 Container가 사용하는 모든 메모리를 포함합니다. 여기에는 RSS(Resident Set Size), 페이지 캐시, 커널 메모리, 소켓 버퍼가 모두 포함됩니다. 반면 memory.working_set_bytes는 usage_in_bytes에서 비활성 파일 캐시(inactive_file)를 제외한 값입니다.
# Container 내부에서 메모리 상세 확인
$ cat /sys/fs/cgroup/memory/memory.stat | grep -E "(cache|rss|inactive_file)"
cache 314572800 # 300MB 페이지 캐시
rss 1717986816 # 1.6GB 실제 메모리
inactive_file 209715200 # 200MB 비활성 파일 캐시# 계산: working_set = 1.6GB + 300MB - 200MB = 1.7GBKubernetes가 OOM 판단에 working_set_bytes를 사용하는 이유는 명확합니다. 메모리 압박 상황에서 Linux 커널은 비활성 파일 캐시를 즉시 회수할 수 있기 때문입니다. 따라서 실제 '활성' 메모리를 나타내는 working_set_bytes가 더 정확한 지표가 되는 것입니다.
JVM 애플리케이션의 Container 메모리 관리
JVM 메모리 구조의 복잡성
JVM 애플리케이션을 Container 환경에서 운영할 때는 특별한 주의가 필요합니다. JVM의 메모리는 단순히 Heap만으로 구성되지 않습니다. Heap Memory 외에도 Metaspace(클래스 메타데이터), Code Cache(JIT 컴파일된 코드), Direct Memory(NIO 버퍼), Thread Stacks, 그리고 JVM 자체의 Native Memory가 있습니다.
많은 개발팀이 Container Limit을 설정할 때 Heap 메모리만 고려하는 실수를 합니다. Container Limit 2GB에 Heap 2GB를 할당하면, Non-Heap 영역을 위한 공간이 없어 즉시 OOMKilled가 발생합니다.
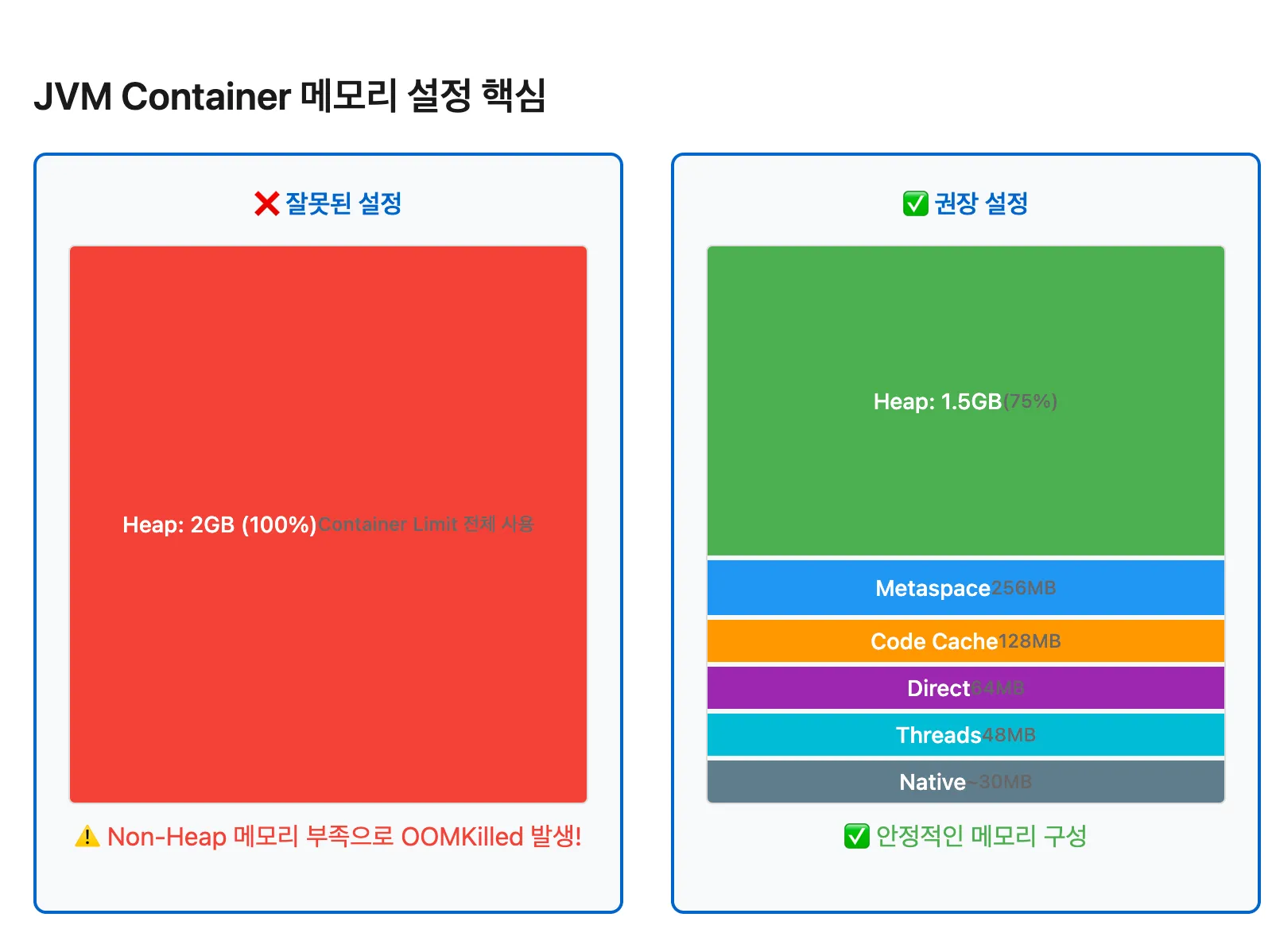
안전한 JVM 설정 전략
실제 운영 환경에서 검증된 설정 방법은 Container Limit의 70-75%만 Heap에 할당하는 것입니다. 나머지 25-30%는 Non-Heap 영역과 OS 오버헤드를 위해 예약됩니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: java-application
spec:
template:
spec:
containers:
- name: app
resources:
limits:
memory: "2Gi"
requests:
memory: "2Gi"
env:
- name: JAVA_OPTS
value: >-
-XX:MaxRAMPercentage=75.0
-XX:InitialRAMPercentage=75.0
-XX:+UseContainerSupport
-XX:MaxMetaspaceSize=256m
-XX:ReservedCodeCacheSize=128m
-XX:+UseG1GC
MaxRAMPercentage 옵션은 Container의 메모리 제한을 인식하고 지정된 비율만큼을 Heap에 할당합니다. UseContainerSupport 옵션은 Java 8u191 이상에서 Container 환경을 올바르게 인식하도록 합니다. 이 옵션이 없으면 JVM은 Host의 전체 메모리를 기준으로 Heap 크기를 계산하여 문제가 발생합니다.
Native Memory Tracking을 활성화하면 JVM의 실제 메모리 사용량을 정확히 파악할 수 있습니다.
# Native Memory Tracking 활성화
-XX:NativeMemoryTracking=summary
# 실행 중인 JVM의 메모리 분석
kubectl exec -it $POD_NAME -- jcmd 1 VM.native_memory summary
Kubernetes Resource 설정의 최적화
QoS Class와 Pod 생존 전략
Kubernetes는 Request와 Limit 설정에 따라 Pod를 세 가지 QoS(Quality of Service) 클래스로 분류합니다. 이 분류는 Node에 메모리 압박이 발생했을 때 어떤 Pod를 먼저 제거할지 결정하는 중요한 기준이 됩니다.
Guaranteed QoS는 Request와 Limit이 같을 때 부여되며, 가장 높은 우선순위를 가집니다. Production 환경의 중요한 서비스는 반드시 이 클래스로 설정해야 합니다. Burstable QoS는 Request가 Limit보다 작을 때 부여되며, 개발이나 스테이징 환경에 적합합니다. BestEffort QoS는 리소스 설정을 하지 않은 경우로, 실제 운영 환경에서는 절대 사용하지 말아야 합니다.
VPA를 활용한 최적값 도출
적절한 Request와 Limit 값을 찾는 것은 지속적인 모니터링과 조정이 필요한 과정입니다. VPA(Vertical Pod Autoscaler)는 실제 사용 패턴을 분석하여 최적의 값을 제안합니다:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
updatePolicy:
updateMode: "Off" # 권장값만 확인, 자동 적용 안함
VPA는 일정 기간 동안의 실제 사용량을 분석하여 Lower Bound, Target, Upper Bound 값을 제시합니다. Production 환경에서는 일반적으로 Upper Bound에 10-20%의 여유를 더한 값을 사용하는 것이 안전합니다.
프로덕션 환경을 위한 모니터링 체계
핵심 메트릭과 알림 전략
효과적인 메모리 모니터링을 위해서는 올바른 메트릭 선택이 필수입니다. 가장 중요한 메트릭은 container_memory_working_set_bytes를 container_spec_memory_limit_bytes로 나눈 메모리 사용률입니다. 추가로 메모리 증가 추세를 파악하기 위한 rate 함수를 활용한 모니터링도 필요합니다.
# 메모리 사용률 모니터링
(container_memory_working_set_bytes{namespace="production", container!=""}
/ container_spec_memory_limit_bytes{namespace="production", container!=""}) * 100
# 메모리 누수 감지 (30분간 지속적 증가)
rate(container_memory_working_set_bytes{namespace="production"}[30m]) > 0
알림은 단계별로 설정하는 것이 효과적입니다. 80% 사용 시 경고 알림으로 모니터링을 강화하고, 90% 도달 시 즉각적인 대응이 필요한 위험 알림을 발생시킵니다.
모니터링 도구의 선택
Prometheus와 Grafana는 강력한 오픈소스 모니터링 스택이지만, PromQL 쿼리 작성, 데이터 보존 정책 설정, 고가용성 구성 등 상당한 운영 부담이 있습니다. 특히 JVM 애플리케이션의 경우, Heap 내부 구조 분석이나 GC 로그 분석 같은 심층적인 분석이 필요한데, 이를 Prometheus만으로 구현하기는 어렵습니다.
이러한 운영 복잡도를 줄이면서도 Container와 JVM 메트릭을 통합적으로 관리하고자 한다면, 와탭(WhaTap)과 같은 SaaS 기반 APM 플랫폼을 고려할 수 있습니다. 에이전트 설치만으로 즉시 사용 가능한 대시보드, 자동화된 이상 징후 감지, 코드 레벨 프로파일링 등의 기능이 문제 해결 시간을 크게 단축시킬 수 있습니다. 많은 조직에서는 기본적인 인프라 메트릭은 Prometheus로, 애플리케이션 성능과 심층 분석은 APM 솔루션으로 보완하는 하이브리드 전략을 채택하고 있습니다.
OOMKilled 예방을 위한 실전 체크리스트
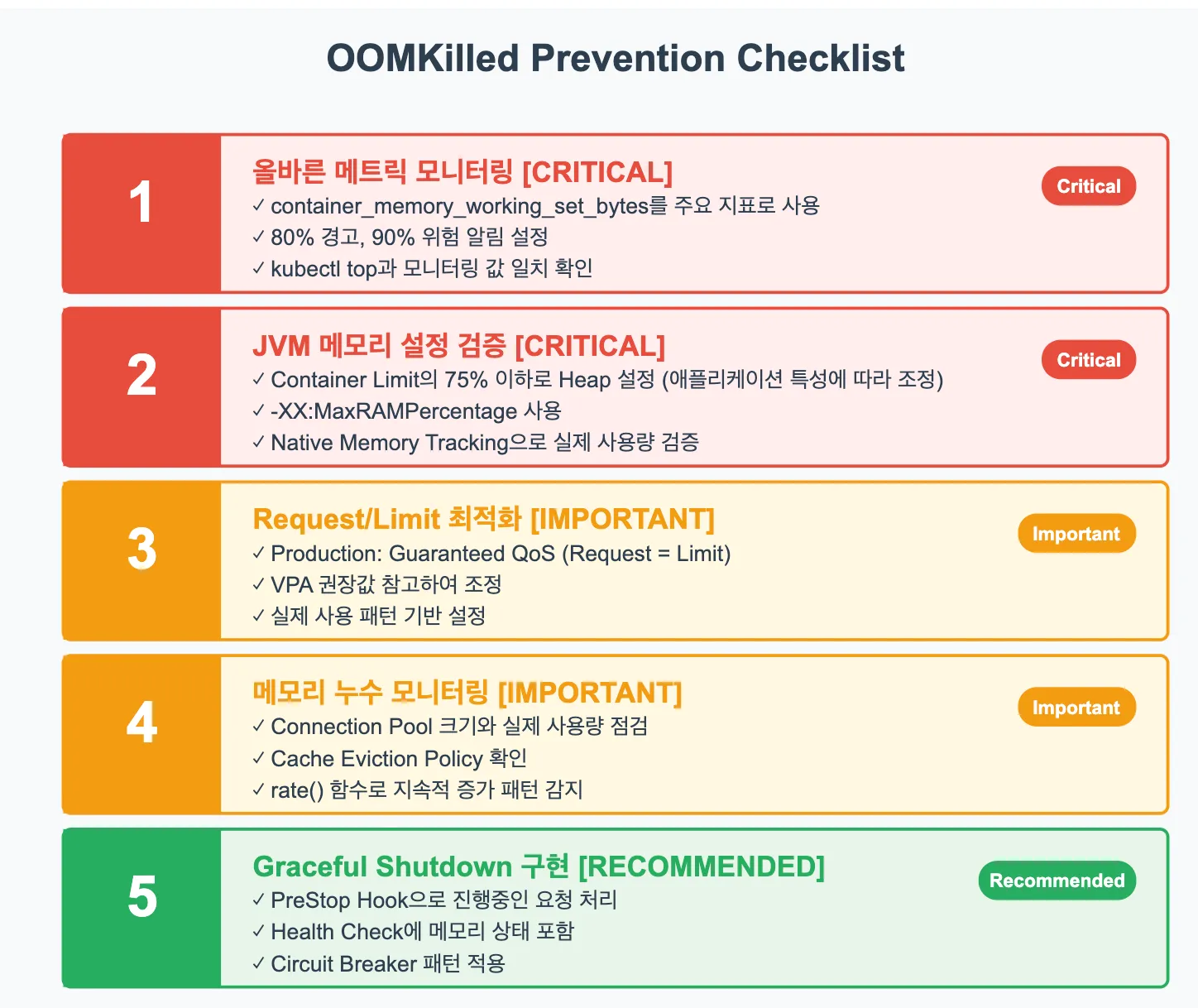
정기 점검 항목
- 올바른 메트릭을 모니터링하고 있는지 확인해야 합니다. container_memory_working_set_bytes를 주요 지표로 사용하고, 이를 기준으로 알림을 설정했는지 점검합니다. kubectl top 명령어가 보여주는 값과 모니터링 시스템의 값이 일치하는지도 확인이 필요합니다.
- JVM 애플리케이션의 경우 Native Memory Tracking을 통해 실제 메모리 사용량을 검증합니다. Total committed memory가 Container Limit의 85%를 넘지 않는지, Heap이 Container Limit의 75%를 넘지 않는지 확인합니다.
- Request와 Limit 설정이 실제 사용 패턴과 일치하는지 검토합니다. Production 환경에서는 Guaranteed QoS를 위해 Request와 Limit을 동일하게 설정하는 것이 권장됩니다.
- 메모리 누수 징후를 모니터링합니다. 시간이 지날수록 메모리가 지속적으로 증가한다면, Connection Pool 크기, Cache Eviction Policy, Event Listener 관리 등을 점검해야 합니다.
- 마지막으로, Graceful Shutdown과 적절한 Health Check가 구현되어 있는지 확인합니다. PreStop Hook으로 진행 중인 요청을 안전하게 처리하고, Liveness Probe에 메모리 상태 체크를 포함시키는 것이 좋습니다.
마무리하며
Kubernetes 환경에서의 메모리 관리는 단순히 리소스를 많이 할당한다고 해결되는 문제가 아닙니다. Container 메트릭의 정확한 이해, JVM의 특수성 고려, 적절한 모니터링 체계 구축이 모두 필요합니다.
핵심은 memory.working_set_bytes를 기준으로 모니터링하고, JVM Heap은 Container Limit의 75% 이하로 설정하며, Production 환경에서는 Guaranteed QoS를 사용하는 겁니다.
이런 원칙을 지키고 정기적인 점검을 수행한다면, 더 이상 예상치 못한 OOMKilled로 인한 서비스 중단을 걱정하지 않아도 됩니다.
메모리 관리는 일회성 작업이 아닌 지속적인 프로세스입니다. 이 가이드에서 제시한 방법론을 기반으로, 각자의 환경에 맞는 최적의 전략을 수립하고 꾸준히 개선해 나가시면 좋겠습니다. 감사합니다.
.png)









