.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
Qdrant 벡터 DB 배치 검색 성능 최대 57% 향상 – 대량 검색 최적화 가이드

이 글은 와탭이 외부 필진과 협력하여 제작한 콘텐츠로, 현업에서 활동하는 전문가의 경험과 인사이트를 독자 여러분께 전달하고자 합니다.
대량의 쿼리가 유입되는 환경에서는 벡터 검색에서의 속도 저하가 시스템 전반의 병목 현상으로 이어질 수 있습니다.
추천 시스템이나 검색 기반 RAG와 같은 AI 서비스, 또는 Negative Mining이나 RAFT와 같은 모델 학습 과정에서는 벡터 유사도 기반의 대규모 검색 작업이 요구되는 경우가 많습니다. 이러한 환경에서는 수백에서 많게는 수천 개까지의 쿼리를 동시에 처리하기도 합니다.
하지만 기존의 방식처럼 하나씩 순차적으로 검색하면, 응답 시간이 늘어나고 시스템 병목이 발생하며, 사용자 경험까지 저하되는 문제가 발생합니다. 이러한 문제를 해결하는 효과적인 방법이 바로 "배치 검색(Batch Search)"입니다.
배치 검색이란? 대량으로 검색하기
Batch Search는 여러 개의 쿼리를 한 번에 묶어 병렬로 처리함으로써, 검색 속도와 효율성을 동시에 높일 수 있는 기법입니다. Qdrant는 이 배치 검색 기능을 기본 제공하며, 최근 업데이트에서는 이를 더욱 고속으로 실행할 수 있도록 내부 구조가 대폭 개선되었습니다.
Qdrant 소개: 고성능 오픈소스 벡터 검색 DB
Qdrant는 Rust 기반으로 구현된 오픈소스 벡터 DB로, 다음과 같은 강점을 가집니다
- 멀티스레드 최적화로 CPU 환경에서도 빠른 검색 성능 제공합니다.
- 배치 검색, 클러스터 모드, 고급 필터링 등 다양한 기능 지원합니다.
- 효율적인 HNSW 인덱싱 알고리즘이 적용되어 있습니다.
특히, 최근 발표된 v1.14 업데이트에서는 대규모 검색 처리 성능을 개선한 Batch Search 최적화 기능이 포함되었습니다.
업데이트 핵심: v1.14에서 개선된 주요 기능
1. Incremental HNSW Indexing
1.14 버젼에서는 Incremental Indexing을 지원합니다. 즉, 새로운 데이터 추가시 HNSW 그래프를 처음부터 다시 만들지 않고 기존의 그래프 구조를 확장하는 방식을 통해 새로운 벡터만 삽입하도록 합니다. 이는 인덱싱과 임베딩 비용을 매우 크게 절감시킬 수 있습니다.
2. Batch Search 병렬 처리 구조 개선
Qdrant는 세그먼트(segment) 단위로 검색 작업을 병렬 처리합니다. 예를 들어 10개의 세그먼트가 있다면, 10개의 스레드가 동시에 각 세그먼트에서 검색을 수행합니다. 하지만, 이전 버전에서는 세그먼트마다 단 1개의 스레드만 사용하도록 고정되어 있었습니다. 이 때문에, 세그먼트가 1개뿐인 경우 (단일 세그먼트 환경) 모든 쿼리가 1개의 세그먼트에서만 처리되게 되어 순차적으로 처리되었습니다. 그리고 이는 병목을 발생시켰습니다.
v1.14부터는 병렬 스레드로 다수 쿼리를 처리할 수 있습니다.이를 통해 단일 세그먼트에서의 검색 속도가 대폭 향상되었으며, 다중 세그먼트에서의 검색 속도도 개선되었습니다. (아래 성능 표 참고)
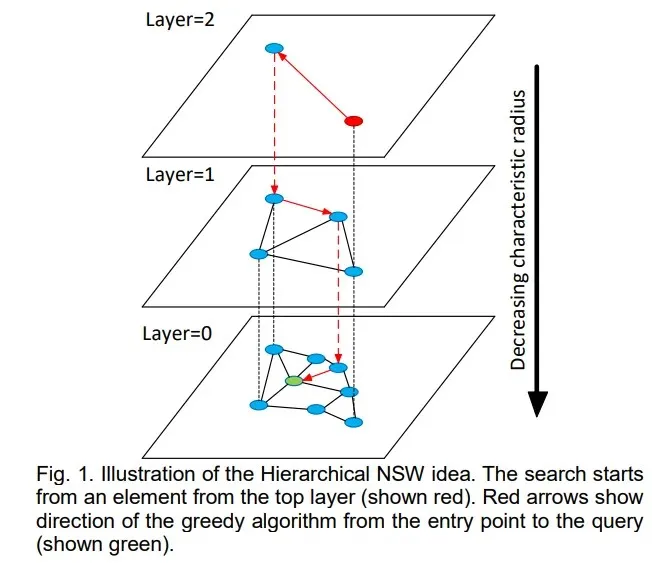
💡 HNSW란?
계층화한 그래프 구조를 통해 최상위 계층에서부터 시작하여 하위 계층까지 반복적으로 local minimum을 찾아, 빠르게 수렴하도록 하는 대표적인 ANN 알고리즘입니다.
💡 Segment란?
Qdrant의 Collection 내부에서 나뉘는 논리적 단위입니다. 각 Segment는 별도의 HNSW 그래프 구조를 갖으며, 여러 개의 Segment가 모여 하나의 Collection을 구성하게 됩니다.
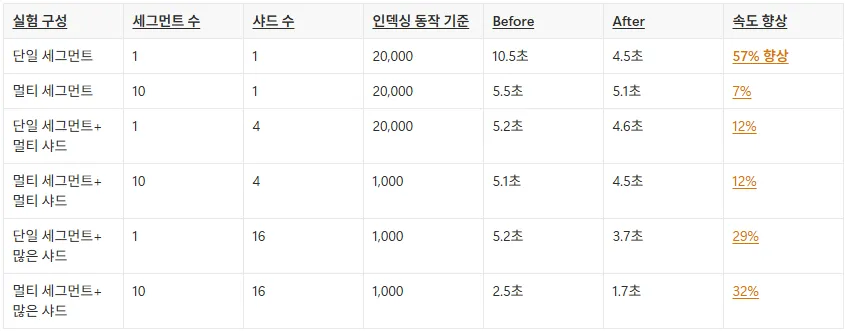
Batch Search 성능 향상 - 수치로 확인하기
아래는 v1.14 기준 배치 검색 성능 개선 실험 결과입니다. 가장 문제가 되었던 단일 세그먼트 환경에서 57%의 속도 향상을 보였습니다. 그 외 멀티 세그먼트 / 샤드의 환경에서도 속도가 향상됨을 확인할 수 있습니다.
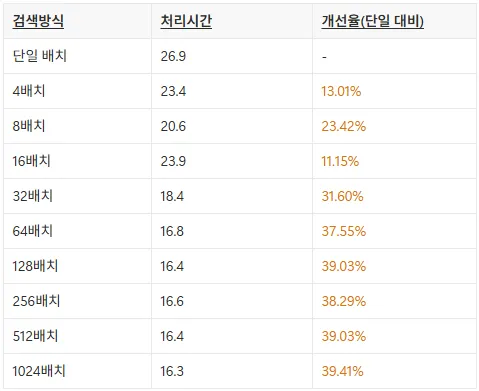
순차 검색 vs. Batch 검색 - 수치로 비교하기
그렇다면, Batch 검색을 사용할때 순차 검색에 비해 얼마나 속도가 개선될까요? 아래는 동일 조건에서의 배치 크기별 성능 비교입니다. 비선형적이지만, 배치 크기에 따라 속도가 개선됨이 확인됩니다. 특히 512, 1024 배치 검색에서는 순차 검색 대비 최대 39% 수준의 속도 개선 수준을 보였습니다.
📦 실험 데이터: 임의의 벡터 샘플, query 4096개, docs 10000건 (기타 payload 없음)
⚙️ 실험 환경: Windows10, AMD Ryzen 5 3600 CPU, snowflake-arctic-embed-l-v2.0 모델, 8-segment, no-shard, Qdrant 1.14
Batch Search 적용 방법 및 활용팁
Qdrant의 배치 검색은 아래 코드처럼 function 하나로 쉽게 적용하실 수 있습니다.
client.query_batch_points(collection_name="{collection_name}", requests={query_requests})아래는 실제 코드 예시입니다.
from qdrant_client import QdrantClient
from qdrant_client.models import models
from sentence_transformers import SentenceTransformer
client = QdrantClient(host = 'localhost', port = 6333)
model = SentenceTransformer("Snowflake/snowflake-arctic-embed-l-v2.0")
## 임베딩 및 쿼리 input 생성 ##
vector_queries = model.encode(query_list) ## 임베딩
query_requests = [models.QeuryRequest(query = vector_query,
using = 'snowflake' ## collection에서 upload시 지정된 명칭
with_payload = False,
) for vector_query in vector_queries]
## 배치 쿼리 수행 ##
search_results = []
batch_size = 512
for i in range(0, len(query_requests), batch_size):
search_results.append(client.query_batch_points(
collection_name = 'test_batch_query',
requests = search_queries[i:i+batch_size],
)
)이처럼 배치 검색은 쉽게 적용할 수 있지만, 보다 최적화된 배치 검색을 위해 다음 사항을 권장드립니다.
1. 필터 기준 동일한 쿼리끼리 묶기
Qdrant는 내부에 Query Planner를 갖추고 있어 필터 중복을 감지해 최적화를 수행해주지만, 같은 필터를 갖는 쿼리를 한 배치로 묶음으로써 쿼리플래너가 보다 효율적으로 동작할 수 있게 합니다. 따라서, 같은 필터끼리 묶어주는 것을 권장합니다.
2. Payload Index 생성하기
필터 조건을 사용하는 필드에 대해 인덱스를 미리 생성해두지 않으면 검색 속도에 악영향을 줍니다. 이는 배치 검색에서 훨씬 두드러집니다. 필터 처리시, 아래와 같이 반드시 인덱스를 생성하기를 권장합니다.
client.create_payload_index(
collection_name="your_collection",
field_name="category", ## field 명칭
field_schema="type" ## bool, integer ...
)3. 최대 허용 Payload를 고려한 설계
Qdrant는 데이터를 업로드 하거나 반환할 때, payload 전체가 일정 수준(약 32MB)를 초과할 경우, 검색을 종료하고 에러를 발생시킵니다. 배치 사이즈 설정시에는 반환되는 문서의 Payload가 이를 초과하지 않도록 고려해야합니다.
4. 성능 변화와 인프라 상태 모니터링
앞선 실험에서 확인된 바와 같이 배치 크기, 필터 구성 변경, 인덱스 생성 여부 등 다양한 조건에 따라 성능은 달라지는데 반해, Qdrant에서 제공하는 로그 기능만으로는 이를 장기적으로 분석하기 어렵습니다. 그러나, WhaTap(와탭)과 같은 실시간 모니터링 도구를 함께 사용한다면 서버의 CPU, 메모리, 디스크 I/O, 네트워크 부하는 물론 API 응답 시간과 처리량 변화까지 추적할 수 있어 최적화 전·후 효과를 정량적으로 분석할 수 있습니다.
글을 마무리 하며
대규모 벡터 검색에서의 병목을 해결하고 싶다면, Qdrant의 Batch Search 기능은 매우 강력한 도구입니다. 최근 버전에서 구조적 개선을 통해 최대 57%의 처리 시간 단축이 가능해졌으며, 간단한 코드와 몇 가지 최적화 팁으로 대량 검색을 보다 효율적으로 처리할 수 있습니다.
또한 실시간 모니터링 도구를 결합하여, 성능 최적화 효과를 수치로 검증하고, Qdrant가 동작하는 인프라 전반의 안정성과 성능까지 함께 확보할 수 있습니다. 벡터 검색 성능에 고민이 있다면, 지금 Qdrant 도입을 검토해보시길 추천드립니다.

.webp)
.webp)