.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
웹서버 모니터링 핵심지표 10가지 [2025]
![웹서버 모니터링 핵심지표 10가지\ [2025]](https://cdn.prod.website-files.com/683542e0144e8b6bf7a76d7b/68f6f5b53b296cf8469e9c79_2508_blog_top_key_metric.webp)
이 글은 와탭이 외부 필진과 협력하여 제작한 콘텐츠로, 현업에서 활동하는 전문가의 경험과 인사이트를 독자 여러분께 전달하고자 합니다.
1. 개요 : 모니터링의 역할
모니터링은 안정적인 서비스 운영과 성능 최적화를 위해 필수적입니다. 장애를 감지하지 못하여 시스템 안정성이 떨어지면 신뢰성 하락및 사용률 급감하며, 이를 회복하는데에는 꽤나 큰 노력과 시간이 필요합니다.
개인적으로 조그마한 웹 서비스를 운영해보면서 개발만 하고, 모니터링을 제때 하지 못해 사용률 급감후 이를 회복하는데 꽤나 고생했던 적이 있습니다.
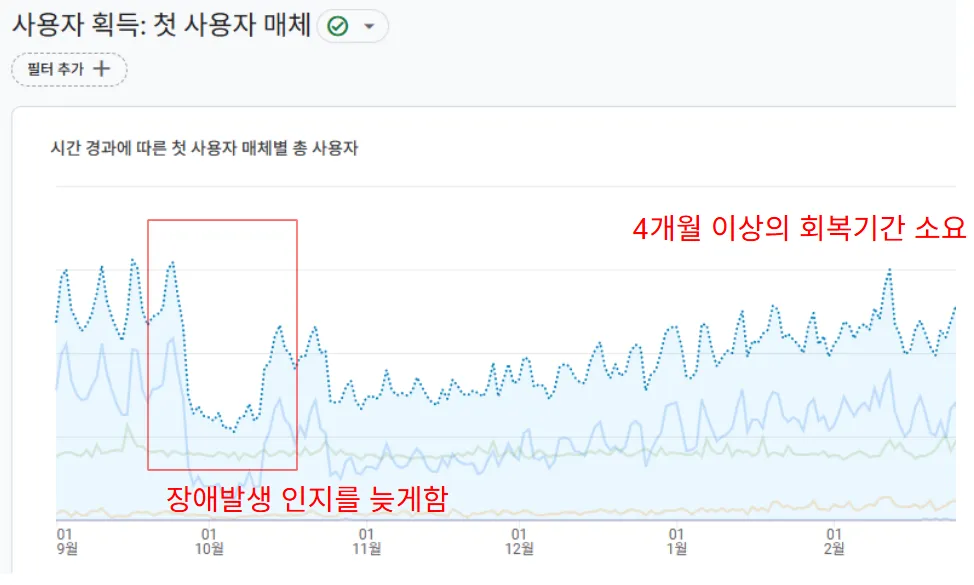
초기 비즈니스에서는 모니터링항목을 어떤것을 해야할지 모르고, 개발을 해야하는 입장이라면 모든 항목을 모니터링 할 수 없기에 웹서버를 운영하면서 필요한 10가지 핵심 모니터링 지표를 정리해보았습니다.
2. 주요 H/W지표 4가지
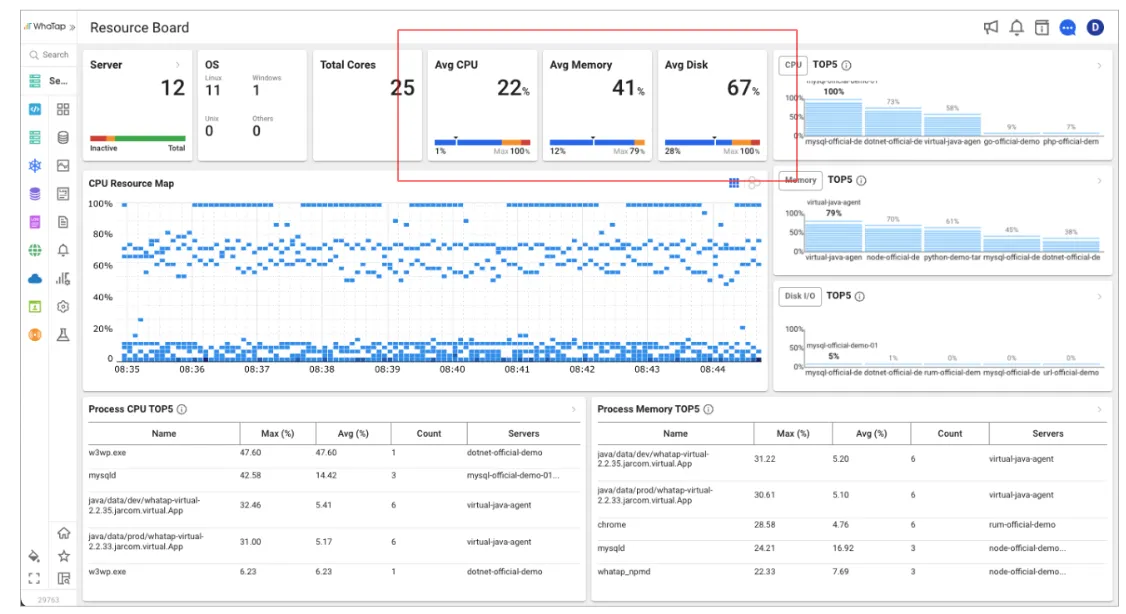
1) CPU 사용률
CPU 사용률이 100%에 달하면 시스템의 전반적인 반응 속도가 저하되고, 다른 프로그램의 실행이 불가능해지거나 서버 원격 접속이 지연되는 등 심각한 서비스 장애로 이어질 수 있습니다.
CPU 사용률이 급증했을 때, 해당 부하를 유발하는 프로세스를 식별하고 종료하면 방식으로 1차 조치가 가능합니다. 프로그램 로직(비효율적인 루프문 등)에 따라 일시적으로 100%가 되는 경우가 있으니, 알람을 걸 때에는 90%이상의 수치가 1분이상 지속과 같은식으로 지속시간을 추가적으로 정해주기도 합니다.
2) MEMORY 사용률
Memory 사용률이 100%가 되면 프로그램이 동작하지 않게 되거나, 기존 실행 중인 프로그램들조차 강제 종료되거나 심각한 성능 저하를 겪게 됩니다. 이 경우 CPU와 유사하게 과도한 메모리를 점유하는 프로세스를 찾아 종료하는 것이 일차적인 조치가 될 수 있습니다.
알람을 걸 때에는 CPU와는 다르게 지속시간을 추가적으로 정하지 않고 한번 발생하면 바로 알람을 발생하도록 하여도 괜찮습니다. 대부분의 경우 프로그램 로직이상으로 Memory Leak이 발생하여 높은상태를 유지하는 경우가 많기 때문입니다.
3) DISK 사용률
디스크 사용률이 100%에 이르면 파일 쓰기(업로드, 로그 저장 등)가 불가능해지고, 데이터베이스 쓰기 오류, 새로운 네트워크 소켓 오픈 실패 등 시스템 전반의 핵심 기능에 심각한 장애가 발생합니다. 이 문제 발생시, 일차적으로는 Linux의 df (디스크 공간 사용량 확인) 및 du (파일/디렉터리별 사용량 확인) 명령어를 활용하여 불필요하거나 과도한 고용량 파일을 식별하고 제거하여 조치할 수 있습니다. 알람을 걸 때에는 MEMORY사용률 알람과 같이 지속시간을 정하지 않아도 됩니다. 부분의 경우에는 파일크기가 한번 커지면, 작아지지 않기 때문입니다.
4) 네트워크 트래픽
네트워크 트래픽은 보통 bps (bits per second, 초당 전송 비트수)값을 통해 모니터링하며, 평시 대비 유입 및 유출 트래픽의 변화를 모니터링합니다. 송신되는 bps가 평소보다 큰 경우, 과도하게 데이터가 나가고 있다는 뜻이므로 데이터 유출이나, 비정상적으로 파일이 대용량 다운로드가 이루어지는 것이라고 생각할 수 있으며, 수신되는 bps가 평소보다 큰 경우, DOS 공격이 들어오거나 비정상적인 대용량 파일이 업로드 되고 있는 케이스가 있습니다. 알람을 걸 때에는 평시 상태를 확인하고, 2배이상의 bps 값을 초과할 경우 알람을 걸면 어느정도 이상감지할 수 있습니다.
3. 서비스 가용성을 위한 지표 3가지
1) 웹서버 HEALTH CHECK
웹서버가 정상동작하지 않는다면 해당 웹서버에 존재하는 모든 app들이 ‘서비스 중단’상태가 됩니다.
웹서버 상태가 비정상일 경우, 경우에 따라 다르지만 HW문제가 아니라면 웹서버를 리스타트하는 방식으로 1차적인 조치가 가능한 경우가 종종있습니다. 웹서버의 HEALTH CHECK 방식은 웹서버의 기본 주소인 http://ip:port (예: http://192.168.1.100:80)를 주기적으로 호출하여 HTTP 응답 코드(예: 200 OK)를 확인하는 것입니다. 이를 통해 웹서버 프로세스 자체의 활성 여부를 판단할 수 있습니다.
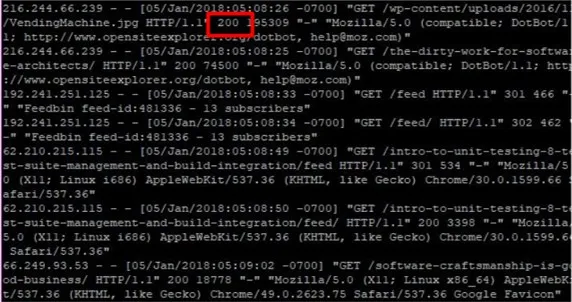
2) API HEALTH CHECK
개발하실때 api별로 unit test를 만드실 텐데요, unit test 코드를 활용하여 주기적으로 api를 호출하여 정상여부를 확인할 수 있습니다. 일반적으로 API HEALTH CHECK시 이상발생할 경우, 로그를 분석해야 조치가 가능한 경우가 많습니다. H/W 문제나 웹서버 문제등의 API 자체적인 문제가 아닌 경우도 발생하는 경우가 많으므로, 앞서 소개드린 CPU, 메모리, 디스크, 웹서버 헬스 체크와 같은 기본 지표들에 대한 알람을 선행하여 설정해주시는 것이 좋습니다.
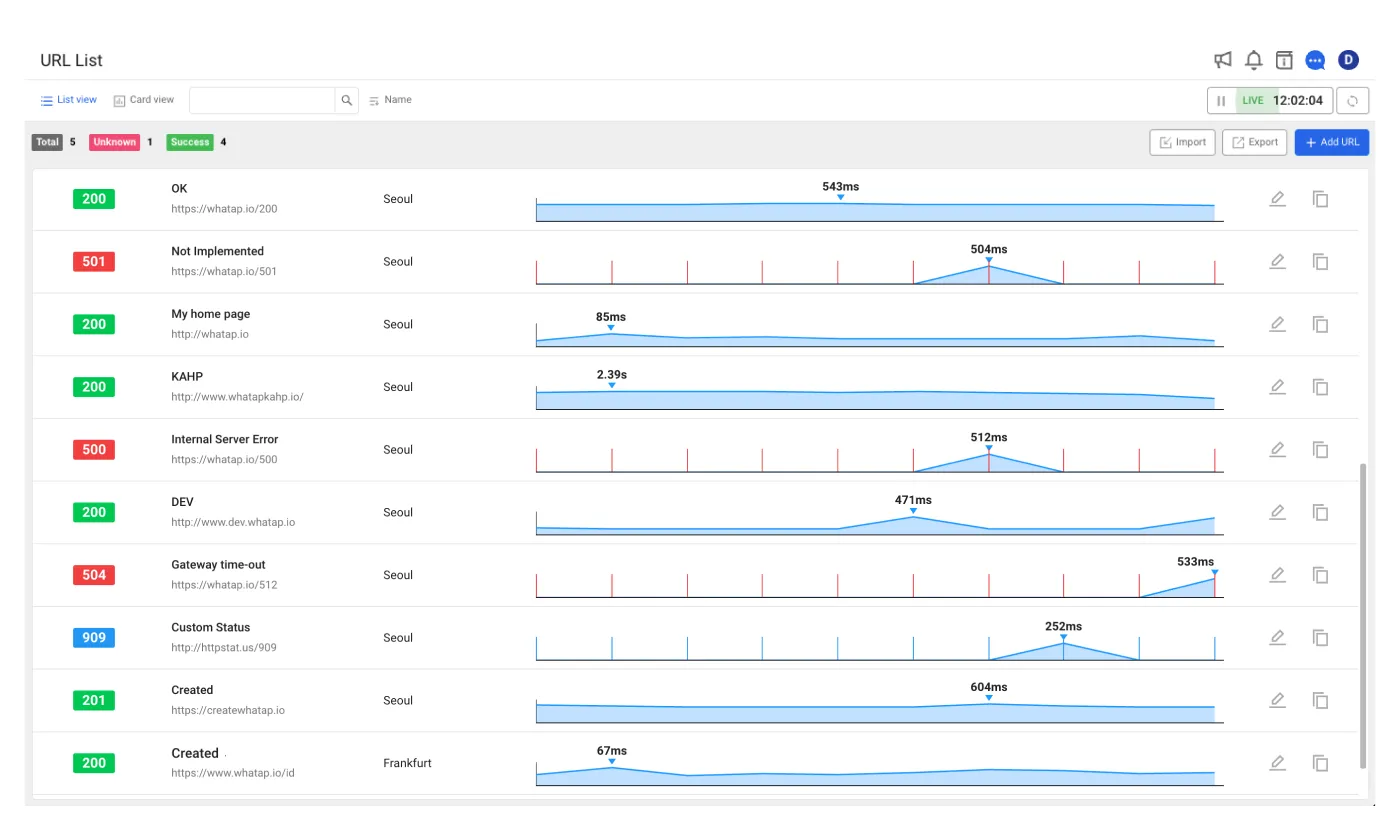
3) DB 연결 HEALTH CHECK
DB HEALTH 이상이 발생하는 경우는 DB자체의 문제보다는, 대체적으로 H/W나 다른 프로그램으로 인해 부하발생 등 외부 영향이 많습니다. DB가 비정상일 경우에 커넥션/쿼리 수행을 하면 DB에서 에러메시지(예: Connection Refused, Timeout)를 발생시키기에, 알람을 걸어놓지않은 지표가 있더라도 원인을 추정해서 조치가 가능한경우가 많습니다. 데이터베이스 연결 헬스 체크는 단순히 DB 서버에 대한 네트워크 연결(CONNECT) 가능 여부를 확인하는 것을 넘어, 실제 쿼리가 정상적으로 수행되는지 검증하는 것이 중요합니다. 이를 위해 SELECT 1 FROM DUAL과 같은 가장 간단한 쿼리를 주기적으로(예: 10초마다) 실행하여 정상적인 응답 여부를 확인함으로써 DB의 가용성을 판단할 수 있습니다.
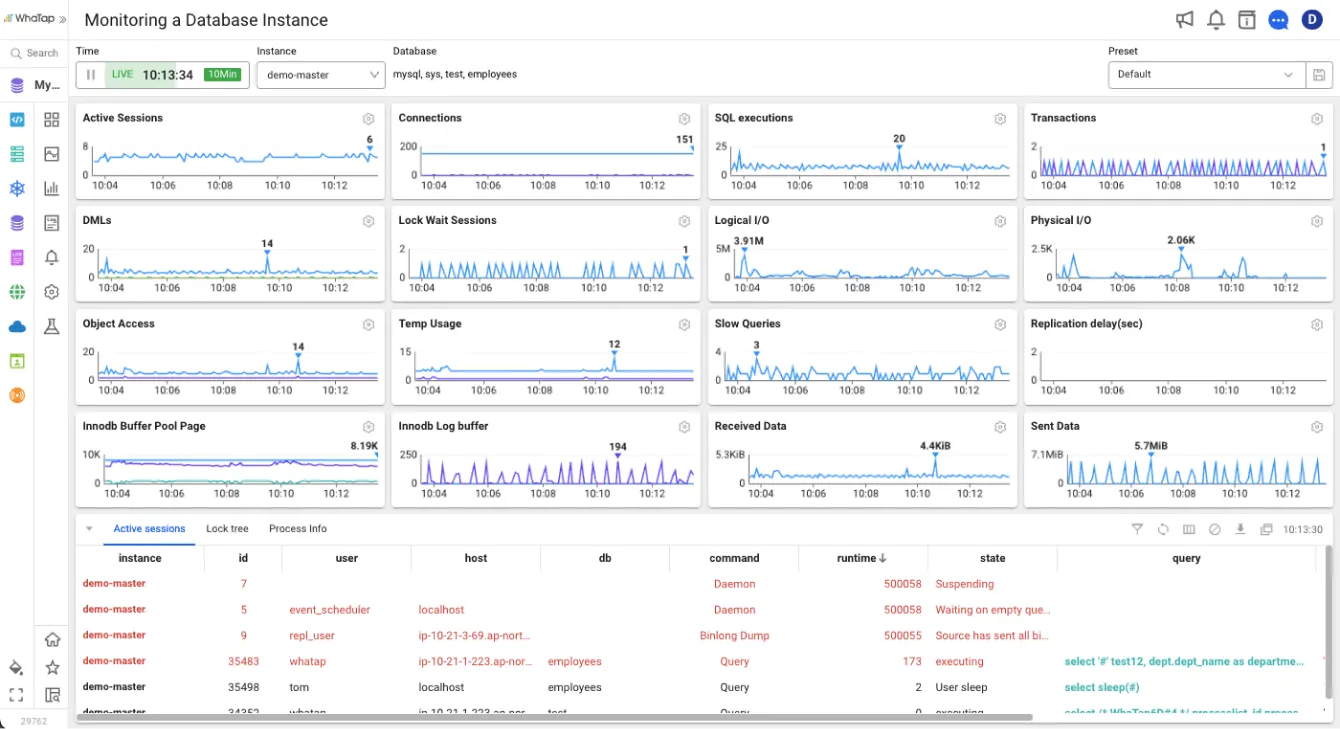
4. 서비스 신뢰성을 위한 지표 3가지
1) HTTP 상태코드 : 5XX 발생
HTTP 5XX 코드는 서비스 로직상의 결함, 미처 예상하지 못한 예외 상황, 또는 외부 연동 시스템의 문제 등으로 인해 서버가 사용자 요청을 정상적으로 처리하지 못했음을 의미합니다. 이러한 오류는 사용자에게 '서비스가 정상적으로 동작하지 않는다'는 불신을 주어 서비스 신뢰도를 크게 떨어뜨립니다. 이 지표는 일반적으로 웹서버에서 남기는 로그를 주기적으로 확인하여 모니터링할 수 있습니다.

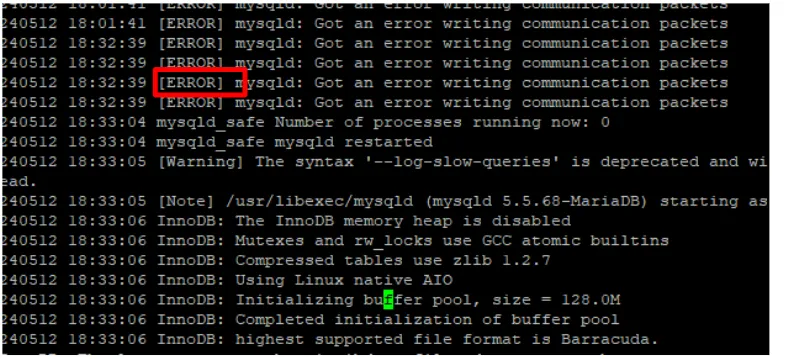
2) ERROR log 발생
서비스를 구성하는 모든 요소, 즉 애플리케이션(Application), 웹서버(Web Server), 데이터베이스(DB), 심지어 운영체제(OS)까지 각자의 에러 로그를 기록합니다. 예를 들어, 마리아DB(MariaDB)는 기본적으로 /var/lib/mysql 경로에 에러 로그를 남기며, 이 외에도 다양한 시스템 경로에 로그가 쌓입니다. ERROR로그는 서비스가 동작하지 않는 CASE이므로 필히 조치해주어야 서비스 신뢰성을 유지할 수 있습니다.
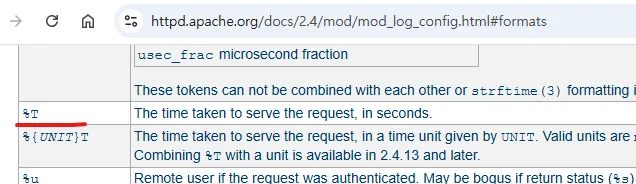
3) 서비스 응답속도 지연
사용자에게 서비스가 '느리다'는 인상을 주면 곧바로 불만과 이탈로 이어지기 때문에, 평상시 대비 응답 속도 변화를 감지하는 것은 매우 중요합니다. 평소보다 속도가 느려지는 여부를 확인함으로써, DB나 네트워크 등 비정상인 부분에 대해 미리 조치를 하여 장애예방을 할 수 있습니다. 이상적인 모니터링은 각 API나 리소스 종류별로 목표 응답 시간(SLO: Service Level Objective)을 설정하고 이를 초과할 때 알람을 발생시키는 것입니다. 하지만 첫 시작이 어렵다면, 전체 서비스에 대해 일괄적으로 60초 이상일 경우 알람 발생하도록 설정하면 장애사전방지가 가능합니다.
5. 모니터링 방식 비교
앞선 지표들에 대해서 모니터링하기 위해서는 모니터링툴을 직접개발하거나, 솔루션 도입(오픈소스, 제품구매, SaaS)등의 방식을 고민해볼 수 있습니다. 각 방식의 장단점을 비교하면 다음과 같습니다.
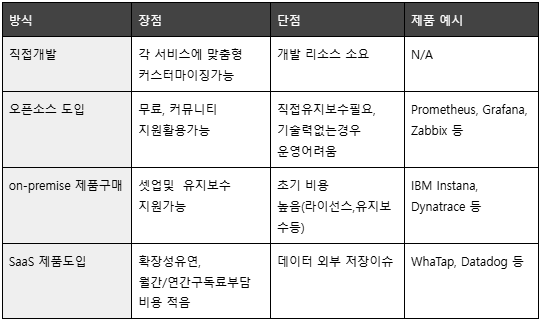
6. 맺으며
과거에는 모니터링 솔루션을 on-premise 도입하려고 하면 굉장히 높은 비용이 들고, 오픈소스를 도입하려면 기술력이 많이 필요 했습니다. 하지만, 요즘에는 WaTap과 같은 SaaS 형태로 제공하는 모니터링 솔루션이 많이 생겨서 합리적인 비용으로, 간단히 셋업하여, 쉽게 모니터링을 할 수 있게 되었습니다.
이 글을 읽으시는 여러분들도 SaaS형태의 모니터링 솔루션을 한번쯤은 사용해보시면서 이러한 장점들을 느껴보시면 좋겠습니다. 감사합니다.