.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
AI 에이전트 옵저버빌리티란 무엇인가

AI 에이전트에게 일을 맡기면, 실패가 예외(exception)로 오지 않습니다. 에이전트는 끝까지 동작하고 그럴듯한 결과를 내놓지만, 중간에 엉뚱한 도구를 부르거나 잘못 판단해 목표와 다른 답에 도착해 있곤 합니다.
이렇게 멀쩡히 응답하면서도 중간 경로에서 조용히 어긋나는 에이전트를, 어떤 경로를 거쳐 그 답에 도달했는지까지 들여다보는 것이 AI 에이전트 옵저버빌리티입니다.
이 글에서는 AI 에이전트 옵저버빌리티가 무엇인지, 기존 APM·LLM 옵저버빌리티와 어떻게 다른지, 무엇을 어떤 표준으로 추적하는지 정리합니다. 이런 흐름 속에서 AI 에이전트 모니터링(AI agent monitoring), agent observability 같은 표현도 운영 분야에서 함께 쓰이기 시작했습니다.
AI 에이전트 옵저버빌리티란
AI 에이전트 옵저버빌리티(agent observability)는 LLM(Large Language Model)으로 움직이는 자율 에이전트가 목표를 수행하는 전 과정을 관측하는 것입니다. 단일 응답 하나가 아니라, 에이전트가 어떤 추론을 거쳐 어떤 도구를 어떤 순서로 호출했고 그 결과 목표를 달성했는지까지 추적합니다.
에이전트를 기존 방식으로 관측하기 어려운 이유는 세 가지입니다.
- 비결정성. 같은 입력에도 매번 다른 추론 경로를 밟습니다. 한 번의 정상 동작이 다음 번을 보장하지 않습니다.
- 동적 실행 경로. 호출하는 도구와 거치는 단계가 실행할 때마다 달라집니다. 미리 정해 둔 고정 지표만으로는 경로를 따라갈 수 없습니다.
- 조용한 실패. 에러나 다운 없이, 그럴듯한 답을 내면서 목표에서 벗어납니다. 무엇이 잘못됐다는 신호 자체가 겉으로 드러나지 않습니다.
그래서 에이전트는 결과값 하나가 아니라 결과에 이르는 과정 전체를 기록해 둬야 사후에 원인을 되짚을 수 있습니다.
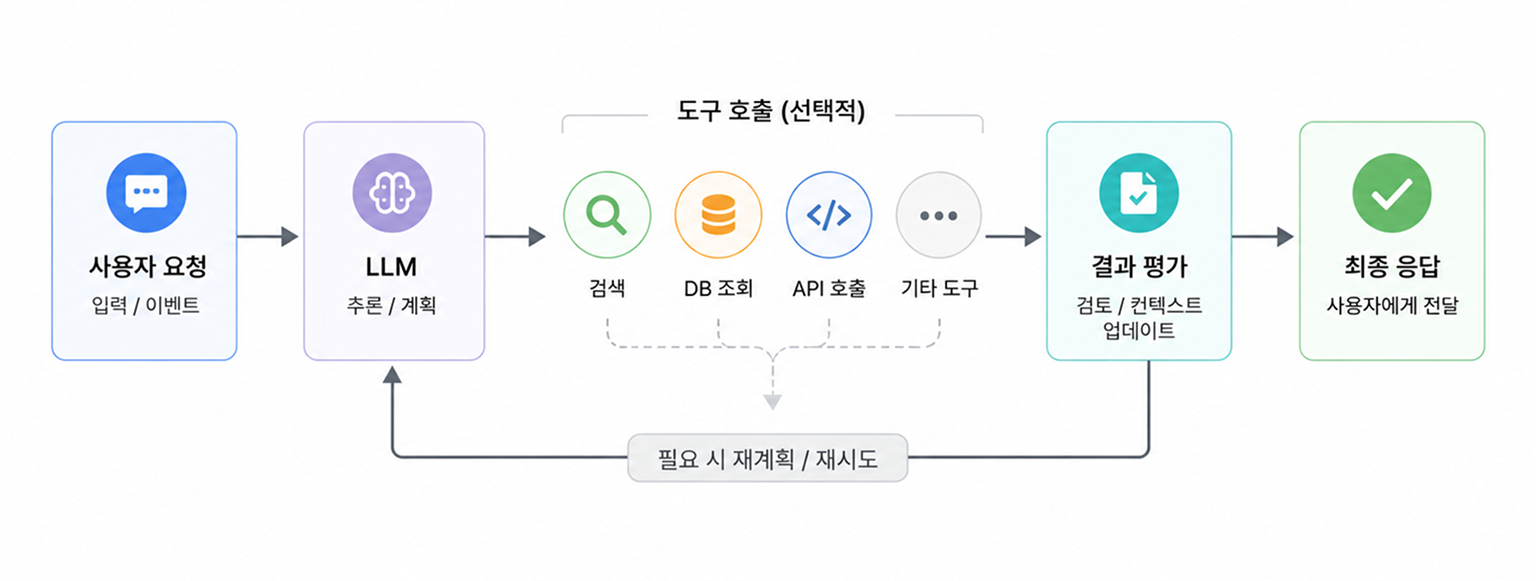
왜 에이전트 옵저버빌리티가 새로 필요해졌나
기존 애플리케이션은 요청을 받아 정해진 코드를 실행하고 결과를 돌려줍니다. 장애가 나면 예외가 발생하거나 응답 시간이 늘어나는 식으로 문제가 겉으로 드러나, 무엇이 잘못됐는지 비교적 빨리 알 수 있습니다.
반면 에이전트는 목표를 받으면 스스로 계획을 세우고, 도구를 고르고, 결과를 평가한 뒤 다음 행동을 정합니다. 실행 경로가 매번 달라지고, 잘못된 판단이 끼어들어도 시스템은 끝까지 응답을 만들어 냅니다. 그래서 '서비스가 살아 있는가'보다 '목표에 올바르게 도달했는가'가 더 중요한 질문이 됩니다.
성능과 가용성만 보던 관측에서 판단 과정과 도구 사용 경로까지 추적하는 관측으로 넘어가야 하는 이유가 여기에 있습니다.
APM, LLM 옵저버빌리티, 에이전트 옵저버빌리티는 무엇이 다른가
세 옵저버빌리티는 관측하는 단위가 다릅니다. APM(Application Performance Monitoring)은 서비스와 요청을, LLM 옵저버빌리티는 개별 모델 호출을, 에이전트 옵저버빌리티는 여러 판단과 도구 호출이 이어지는 실행 전체를 봅니다. 앞의 두 가지를 대체하는 것이 아니라, 그 위에 한 겹을 더 얹는다고 보면 됩니다.
에이전트 옵저버빌리티는 특히 다음과 같은 환경에서 중요합니다.
- 검색·RAG 에이전트
- MCP 기반 도구 호출 에이전트
- 여러 에이전트가 협력하는 멀티 에이전트 시스템
- 업무 자동화 에이전트(티켓 처리, 고객 지원, 운영 자동화)
이런 환경에서는 모델 호출 하나보다 에이전트가 어떤 경로를 거쳐 목표를 수행했는지가 더 중요한 분석 대상이 됩니다.
예를 들어 한 번의 모델 호출은 흠잡을 데 없이 좋은 답을 내놓을 수 있습니다. 그러나 에이전트가 그 답을 받아 잘못된 도구를 고르거나, 같은 단계를 반복하는 루프에 빠지거나, 엉뚱한 중간 결론을 다음 단계로 넘기면 전체 목표는 어긋납니다. LLM 옵저버빌리티가 호출 하나의 품질을 본다면, 에이전트 옵저버빌리티는 그 호출들이 이어진 경로 전체의 타당성을 봅니다.
조금 더 구체적인 장면을 들어 보겠습니다. 문서를 검색해 답하는 RAG(Retrieval-Augmented Generation) 에이전트가 있다고 합시다. 모델 호출 하나하나는 정상이고 최종 답변도 그럴듯한데, 에이전트가 검색 도구를 부르지 않고 기억에만 의존해 답했다면 결과는 사실과 어긋납니다. LLM 옵저버빌리티는 각 호출의 품질을 정상으로 볼 뿐이고, "검색 단계를 통째로 건너뛰었다"는 경로의 문제는 실행 전체를 따라가야 비로소 드러납니다. 에이전트가 조용히 실패하는 지점이 바로 이런 경로의 빈틈입니다.
에이전트는 무엇을 추적하고, 어떤 표준으로 보는가
에이전트 실행에서 관측해야 할 신호는 단일 지표가 아니라 경로를 따라 흩어져 있습니다. 그래서 "응답 시간"이나 "에러율" 하나로는 부족하고, 경로의 각 길목을 신호로 남겨 둬야 합니다.
무엇을 신호로 남기는가
이 신호들을 사후에 따라가려면 호출 지점이 일정한 형식으로 기록돼 있어야 합니다. 여기에 두 가지 표준이 맞닿아 있습니다.
MCP로 도구 호출을 표준화하기
MCP(Model Context Protocol)는 에이전트가 외부 도구와 데이터에 연결하는 방식을 표준화한 오픈 규격입니다. 도구마다 제각각이던 연결 방식이 하나의 인터페이스로 모이면, 에이전트가 무엇을 언제 어떤 입력으로 호출했는지가 일정한 형태로 드러납니다. 호출 인터페이스가 일정해지면 어디에 계측을 걸지가 분명해지고, 그 지점이 자연스럽게 관측·기록 지점이 됩니다. 표준화된 도구 호출은 곧 일관된 관측 지점인 셈입니다.
OpenTelemetry로 실행을 트레이스로 남기기
OpenTelemetry(OTel)의 GenAI 시맨틱 컨벤션은 에이전트 실행과 도구 호출을 트레이스(trace)와 스팬(span)으로 기록하는 벤더 중립 표준입니다. 에이전트의 한 작업을 하나의 트레이스로 잡고, 그 아래에 에이전트 호출(invoke_agent), 모델 호출(chat), 도구 실행(execute_tool)을 자식 스팬으로 펼쳐 둡니다. 이렇게 남기면 특정 제품에 묶이지 않고 실행 경로를 그대로 펼쳐 볼 수 있고, 조용한 실패가 어느 스팬에서 갈라졌는지 짚어낼 수 있습니다.
이 컨벤션은 아직 Development(실험) 단계로 발전 중입니다. 세부 속성 이름은 바뀔 수 있지만, 에이전트 실행을 벤더 중립 표준 형식으로 남기는 방향 자체는 분명합니다.
자주 묻는 질문
AI 에이전트 모니터링과 옵저버빌리티는 같은 말인가요.
결이 다릅니다. 모니터링은 미리 정해 둔 지표를 감시해 알려진 문제를 알리는 쪽이고, 옵저버빌리티는 밖에서 수집한 신호로 내부에서 무슨 일이 있었는지를 추론하는 쪽입니다. 실행 경로가 매번 달라지는 에이전트는 미리 정해 둔 지표만으로는 부족해, 경로를 사후에 되짚을 수 있는 옵저버빌리티가 필요합니다.
LLM 옵저버빌리티만 갖추면 충분하지 않나요.
LLM 옵저버빌리티는 모델 호출 하나하나의 품질을 봅니다. 에이전트 옵저버빌리티는 그 호출들이 이어진 경로와 도구 사용, 루프, 목표 달성까지 봅니다. 개별 호출은 모두 정상이어도 호출들을 엮은 경로가 틀릴 수 있으므로, 에이전트를 운영한다면 한 겹 더 넓은 관측이 필요합니다.
OpenTelemetry로 에이전트를 추적할 수 있나요.
가능합니다. OpenTelemetry의 GenAI 시맨틱 컨벤션이 에이전트 호출(invoke_agent)과 도구 실행(execute_tool) 스팬을 정의하고 있어, 에이전트 실행을 트레이스로 기록할 수 있습니다. 벤더 중립 표준이라 수집 도구나 백엔드를 바꿔도 같은 형식으로 남습니다.
멀티 에이전트는 어떻게 추적하나요.
지휘 역할의 에이전트가 여러 서브 에이전트에게 일을 나눠 맡기는 구조라면, 트레이스의 부모·자식 스팬 관계로 그 위임을 그대로 남길 수 있습니다. 어떤 에이전트가 무엇을 누구에게 맡겼고 어느 단계에서 어긋났는지를 한 트레이스 안에서 따라갈 수 있습니다.
마치며
AI 에이전트는 멈춰서 실패하지 않고 조용히 어긋납니다. 그래서 결과값 하나가 아니라 결과에 이르는 경로 전체를 관측하는 일이 에이전트 운영의 전제가 됩니다. 관측 단위가 요청에서 모델 호출로, 다시 실행 경로 전체로 넓어지는 흐름을 이해하면, 무엇을 추적하고 어떤 표준으로 기록할지 판단하기가 한결 쉬워집니다.
LLM과 AI 에이전트의 동작을 표준 기반으로 추적하고 한곳에서 분석하려는 단계라면, 와탭의 LLM 옵저버빌리티와 공식 문서를 함께 살펴보시기 바랍니다.
더 읽을거리


.png)





