.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
SingleStore 모니터링 무엇을 봐야 하나
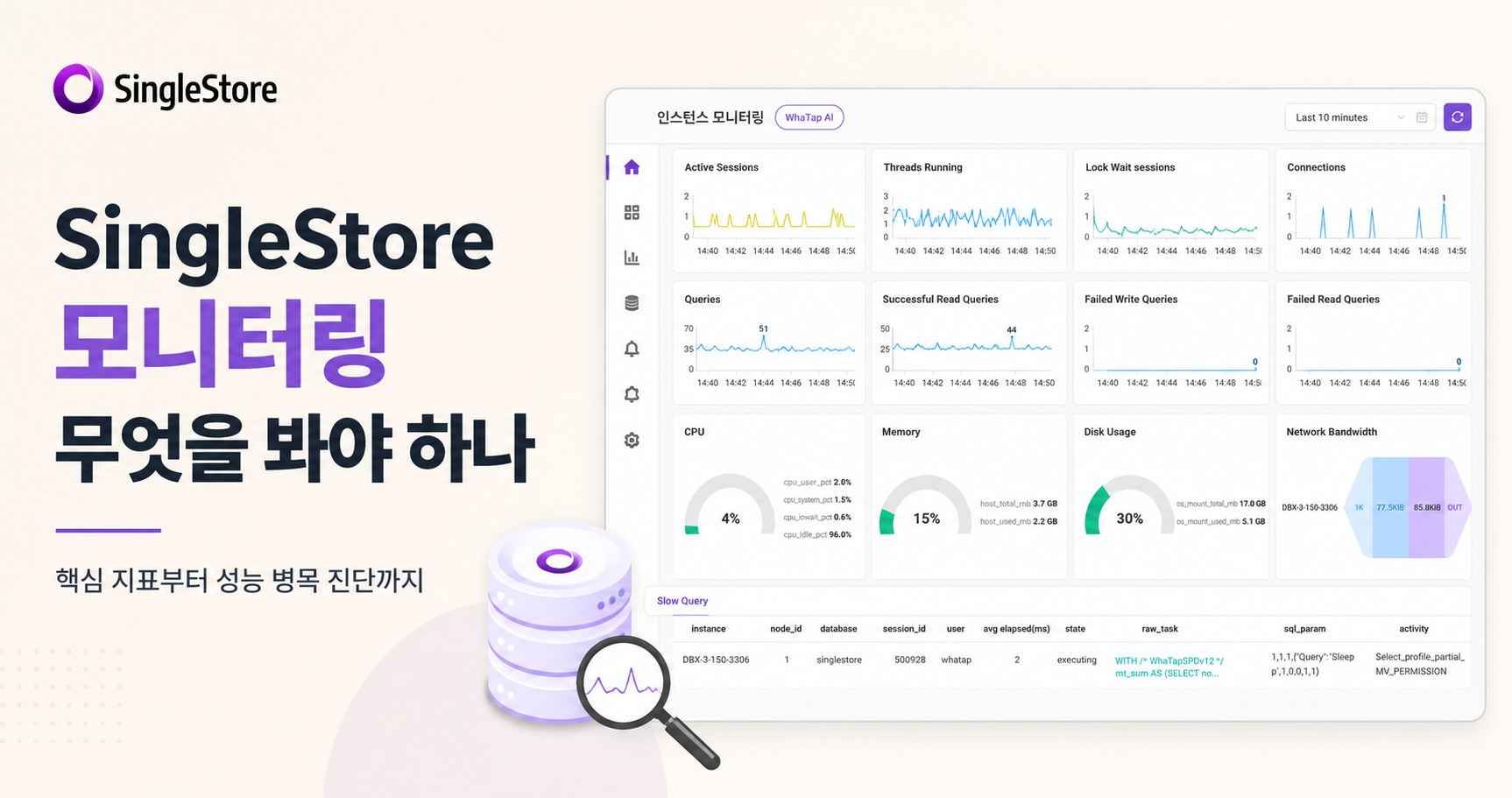
같은 쿼리인데 어떤 날은 0.2초, 어떤 날은 8초가 걸립니다. 단일 데이터베이스라면 슬로우 쿼리 로그 하나로 범인을 좁힐 수 있지만, SingleStore처럼 데이터를 여러 노드에 나눠 저장하는 분산 SQL 데이터베이스에서는 이야기가 달라집니다. 쿼리는 같아도 데이터가 노드마다 고르게 퍼져 있느냐, 한 노드에 몰려 있느냐에 따라 응답시간이 수십 배씩 벌어집니다.
이 글은 SingleStore(싱글스토어, 구 MemSQL)를 운영하거나 도입을 검토하는 개발자, DBA, SRE를 대상으로 합니다. 일반적인 데이터베이스 모니터링이 아니라, 분산 SQL 데이터베이스이기 때문에 추가로 봐야 하는 지점을 중심으로 정리합니다. 노드 구조에서 시작해 데이터 스큐, 스토리지 엔진, 분산 쿼리, 파이프라인 순서로 짚어 드립니다.
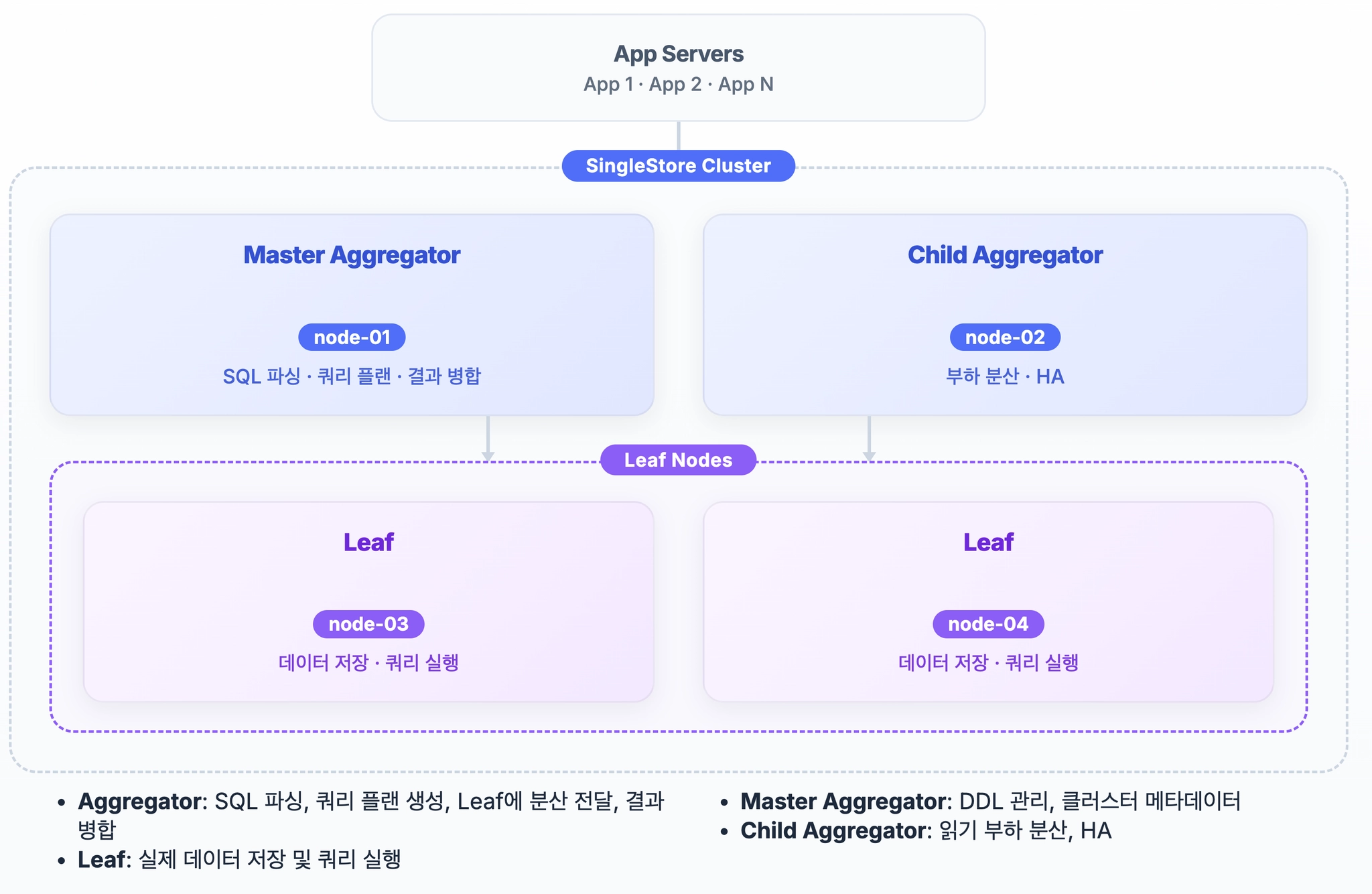
애그리게이터와 리프 노드는 무엇이 다른가
SingleStore 클러스터는 역할이 다른 두 노드로 구성됩니다. 애그리게이터(aggregator) 노드는 클라이언트 쿼리를 받아 각 노드에 나눠 보내고, 돌아온 중간 결과를 합쳐 클라이언트에 돌려주는 라우터 역할을 합니다. 리프(leaf) 노드는 실제 데이터를 조각으로 나눠 저장하고 그 위에서 연산을 수행하는 저장 겸 연산 노드입니다.
애그리게이터는 다시 둘로 나뉩니다. 클러스터 전체를 통제하고 메타데이터를 관리하는 마스터 애그리게이터(master aggregator)가 하나 있고, 쿼리 부하를 분산해 받는 차일드 애그리게이터(child aggregator)가 여럿 붙습니다. 클라이언트 연결과 쿼리 진입은 주로 애그리게이터 쪽으로 몰리고, CPU와 메모리, 디스크를 실제로 많이 쓰는 쪽은 데이터를 들고 있는 리프 노드입니다.
이 구조 때문에 모니터링의 첫 단추는 노드별 자원 사용량을 분리해서 보는 것입니다. 애그리게이터의 CPU가 치솟는다면 결과 병합이나 클라이언트 연결 쪽 부하를 의심하고, 특정 리프 노드만 CPU와 메모리가 높다면 그 노드에 데이터나 쿼리 부하가 쏠렸다는 신호입니다. 노드를 하나의 평균값으로 뭉쳐 보면 이런 편중이 평균에 묻혀 보이지 않습니다.
클러스터 헬스를 볼 때는 노드 목록이 실제 구성과 일치하는지부터 확인합니다. SingleStore는 클러스터 메타데이터 뷰(MV_NODES)로 현재 살아 있는 노드와 역할을 조회할 수 있어, 리프 노드 하나가 빠지거나 응답이 없을 때 이를 빠르게 잡아낼 수 있습니다. 리프 노드 하나가 빠지면 데이터 재분배가 일어나고, 그 과정에서 쿼리 성능이 일시적으로 흔들릴 수 있습니다. 따라서 노드 수 변화와 자원 사용량을 함께 보는 것이 좋습니다.
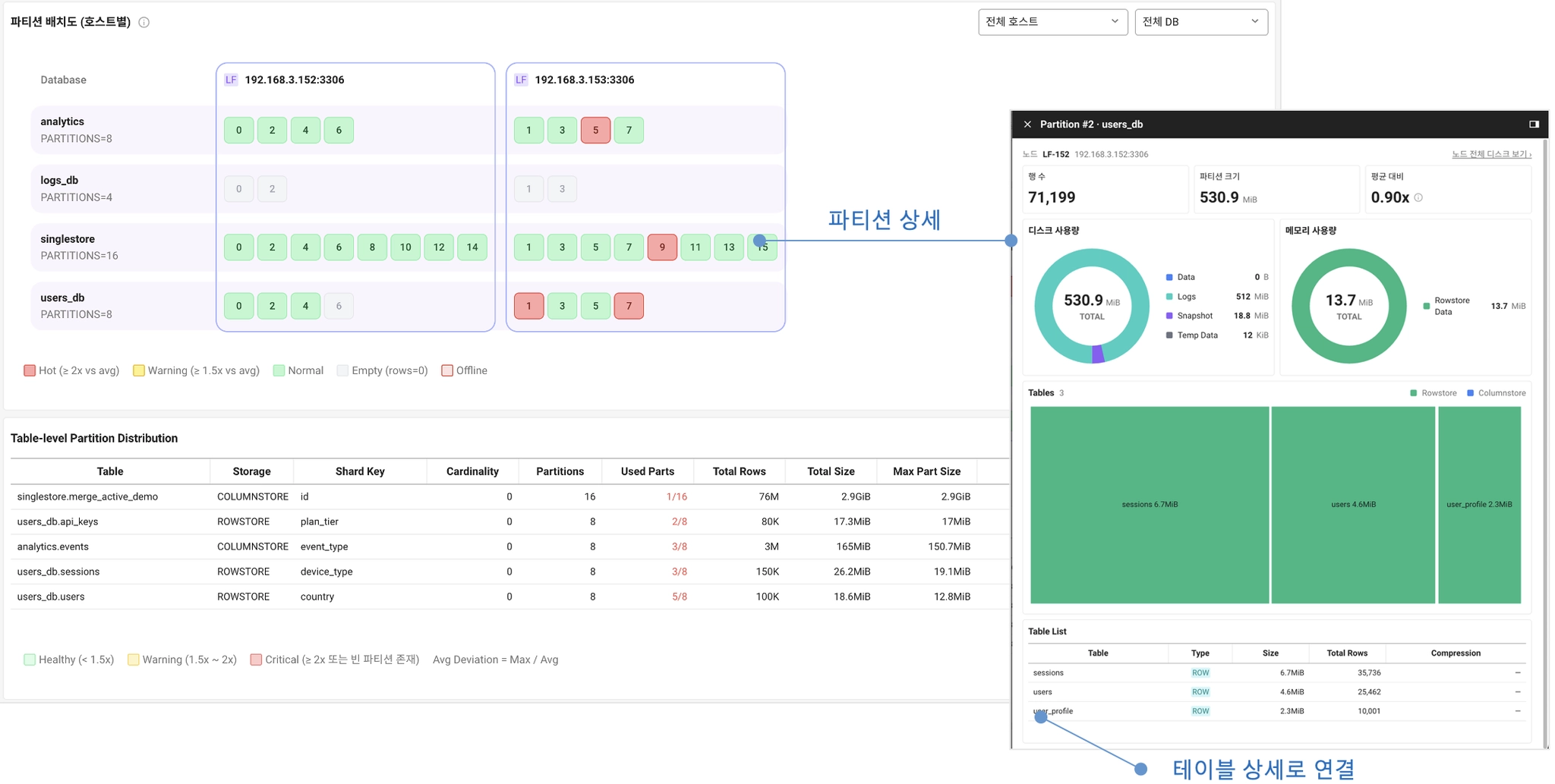
데이터 스큐, 분산 SQL DB 성능을 가르는 단서
분산 SQL 데이터베이스 모니터링에서 가장 중요하면서도 놓치기 쉬운 지표가 데이터 스큐(data skew)입니다. 데이터 스큐란 테이블의 데이터가 클러스터의 파티션들에 고르지 않게 분포한 상태를 말합니다. SingleStore는 리프 노드를 다시 파티션(partition)이라는 조각으로 나누고, 각 파티션이 데이터의 일부(샤드)를 들고 있습니다.
어떤 행이 어느 파티션에 들어갈지는 샤딩 키(shard key)가 결정합니다. INSERT가 들어오면 애그리게이터가 샤딩 키 컬럼 값에 해시 함수를 적용해 파티션 번호를 계산하고, 해당 파티션으로 행을 보냅니다. 그래서 샤딩 키 값이 같은 행은 항상 같은 파티션에 모입니다.
문제는 샤딩 키 분포가 한쪽으로 치우칠 때입니다. 예를 들어 쇼핑몰에서 대형 고객사 한 곳이 전체 주문의 40%를 차지하면, 그 고객 데이터가 특정 파티션에 집중됩니다. 다른 파티션은 여유가 있어도 그 파티션 하나가 병목이 되면서 전체 조회 시간이 함께 늘어날 수 있습니다. 이렇게 파티션 간 데이터가 불균형하게 분포한 상태를 파티션 스큐(partition skew)라고 합니다.
스큐가 왜 성능을 직접 떨어뜨리는지는 분산 쿼리의 동작 방식에서 나옵니다. 여러 파티션에 걸친 쿼리는 가장 느린 파티션보다 빠를 수 없습니다. 모든 파티션의 결과가 모여야 애그리게이터가 최종 결과를 낼 수 있기 때문입니다. 행이 한 파티션에 몰려 있으면 그 파티션의 처리 시간이 전체 쿼리 시간을 좌우하고, 나머지 파티션은 일찍 끝낸 채 기다립니다. 같은 쿼리가 어떤 날 느려지는 현상의 상당수가 여기에서 옵니다.
그래서 봐야 할 지표는 단순한 총 행 수가 아니라 파티션별 편차입니다.
- 파티션별 행 수 편차: 파티션마다 들고 있는 행 수가 얼마나 벌어져 있는가. 한두 파티션만 유독 크면 샤딩 키 분포를 의심합니다.
- 파티션별 바이트(메모리) 편차: 행 수는 비슷해도 행 크기가 달라 메모리 점유가 한쪽으로 쏠릴 수 있습니다. 메모리 스큐는 특정 리프 노드의 메모리 압박으로 이어집니다.
- 노드 간 데이터량 편차: 파티션이 노드에 고르게 배치됐는지. 노드 하나에 큰 파티션이 몰리면 그 노드가 클러스터의 병목이 됩니다.
스큐를 발견했을 때의 일반적인 해결 방향은 샤딩 키를 다시 고르는 것입니다. SingleStore 공식 문서는 샤딩 키에 컬럼을 추가해 분포를 더 고르게 만들거나, 데이터를 재분배하는 방식을 권합니다. 다만 키 변경은 재적재를 동반하므로, 운영 중인 클러스터에서는 스큐 추이를 꾸준히 관찰해 임계점을 넘기 전에 대응하는 편이 안전합니다.
분산 쿼리가 느릴 때 어느 노드를 봐야 하나
SingleStore는 MySQL 와이어 프로토콜과 호환되어 기존 MySQL 도구로 접속할 수 있지만, 슬로우 쿼리를 보는 각도는 분산 환경에 맞춰야 합니다. 단일 DB에서는 "이 쿼리가 느리다"로 끝나지만, 분산 SQL 데이터베이스에서는 "이 쿼리가 어느 노드, 어느 파티션에서 느린가"까지 내려가야 원인이 잡힙니다.
컬럼스토어와 로우스토어, 어느 쪽 부하인가
쿼리가 어느 스토리지 엔진을 타는지부터 가릅니다. SingleStore는 한 클러스터 안에서 두 가지 엔진을 함께 씁니다. 컬럼스토어(columnstore)는 데이터를 컬럼 단위로 디스크에 저장해 대량 집계와 분석 쿼리에 강하고, 로우스토어(rowstore)는 한 행의 모든 필드를 메모리에 함께 저장해 짧은 트랜잭션과 점 조회에 빠릅니다. SingleStore Helios에서는 컬럼스토어가 기본 테이블 형식이고, 로우스토어는 전부 메모리에 올라갑니다.
이 둘을 묶어 유니버설 스토리지(Universal Storage)라고 부릅니다. 유니버설 스토리지는 컬럼스토어가 발전하면서 컬럼스토어 위에서도 행 단위 잠금, 해시 인덱스, 업서트 같은 트랜잭션 워크로드를 처리할 수 있게 된 형태입니다. 덕분에 트랜잭션과 분석을 한 데이터베이스에서 함께 돌리는 HTAP(Hybrid Transactional/Analytical Processing, 트랜잭션과 분석 워크로드를 한 시스템에서 동시에 처리하는 방식)가 가능해졌습니다.
다만 모니터링 관점에서는 두 엔진의 병목 지점이 여전히 다릅니다. 로우스토어는 메모리에 상주하므로 테이블이 커질수록 리프 노드의 메모리 사용량이 먼저 문제가 됩니다. 메모리 사용량은 한계에 가까운데 디스크는 여유롭다면, 로우스토어 테이블 증가를 먼저 의심합니다. 반대로 컬럼스토어는 디스크 입출력과 세그먼트 병합 부하가 주로 나타납니다. HTAP로 운영한다면 같은 클러스터에서 분석 쿼리가 트랜잭션 응답시간을 밀어내고 있지 않은지, 워크로드별 자원 점유를 분리해 보는 것이 핵심입니다.
실행 계획과 액티브 세션으로 느린 지점 좁히기
분산 쿼리는 애그리게이터가 실행 계획을 세워 각 리프 노드로 작업을 내려보내고, 리프가 자기 파티션에서 처리한 중간 결과를 다시 애그리게이터가 합치는 흐름입니다. 그래서 쿼리 실행 계획을 볼 때는 작업이 단일 파티션으로 떨어지는지, 여러 파티션에 흩어지는지가 첫 갈림길입니다. 샤딩 키와 완전히 일치하는 조건은 단일 파티션으로 라우팅되어 빠르지만, 샤딩 키를 타지 못하는 조회는 모든 파티션을 훑고 노드 간 데이터 이동(리파티셔닝)을 일으켜 느려집니다.
실시간 진단에서는 액티브 세션, 곧 지금 이 순간 실행 중인 쿼리를 노드별로 보는 것이 출발점입니다. 어느 리프 노드에 실행 중인 쿼리가 쌓여 있는지를 보면, 부하가 쏠린 노드와 그 노드에서 도는 SQL을 바로 좁힐 수 있습니다. 특정 리프에서만 액티브 세션이 길게 머문다면 앞서 말한 데이터 스큐나 그 노드의 자원 포화를 함께 의심합니다.
락 경합과 대기, 데드락도 분산 환경에서 그대로 나타납니다. 다만 잠금이 어느 노드, 어느 세션 사이에서 벌어지는지를 분산 관점으로 추적해야 합니다. 어떤 세션이 무엇을 기다리고 있고 누가 자원을 쥐고 있는지를 노드와 묶어 보면, 한쪽 트랜잭션이 길게 잡고 있어 뒤 작업이 줄줄이 밀리는 상황을 풀어낼 수 있습니다.
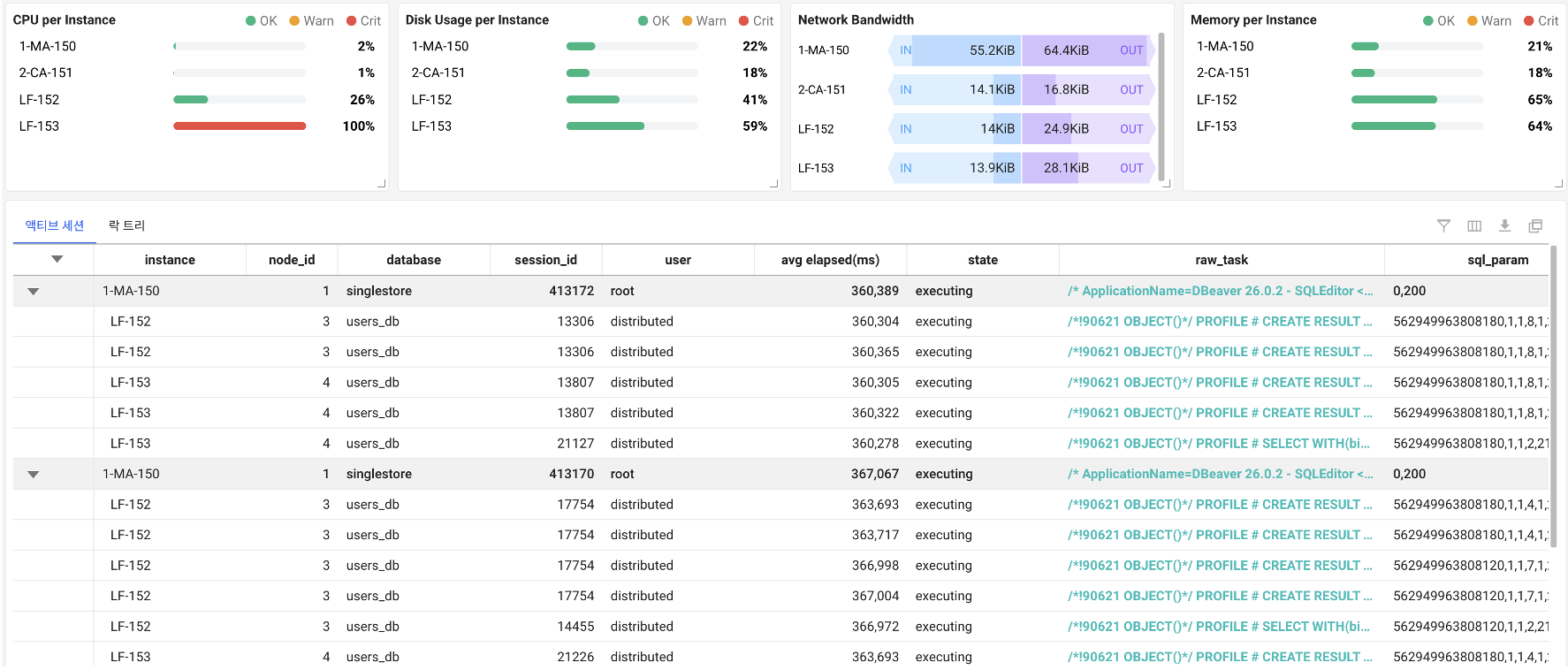
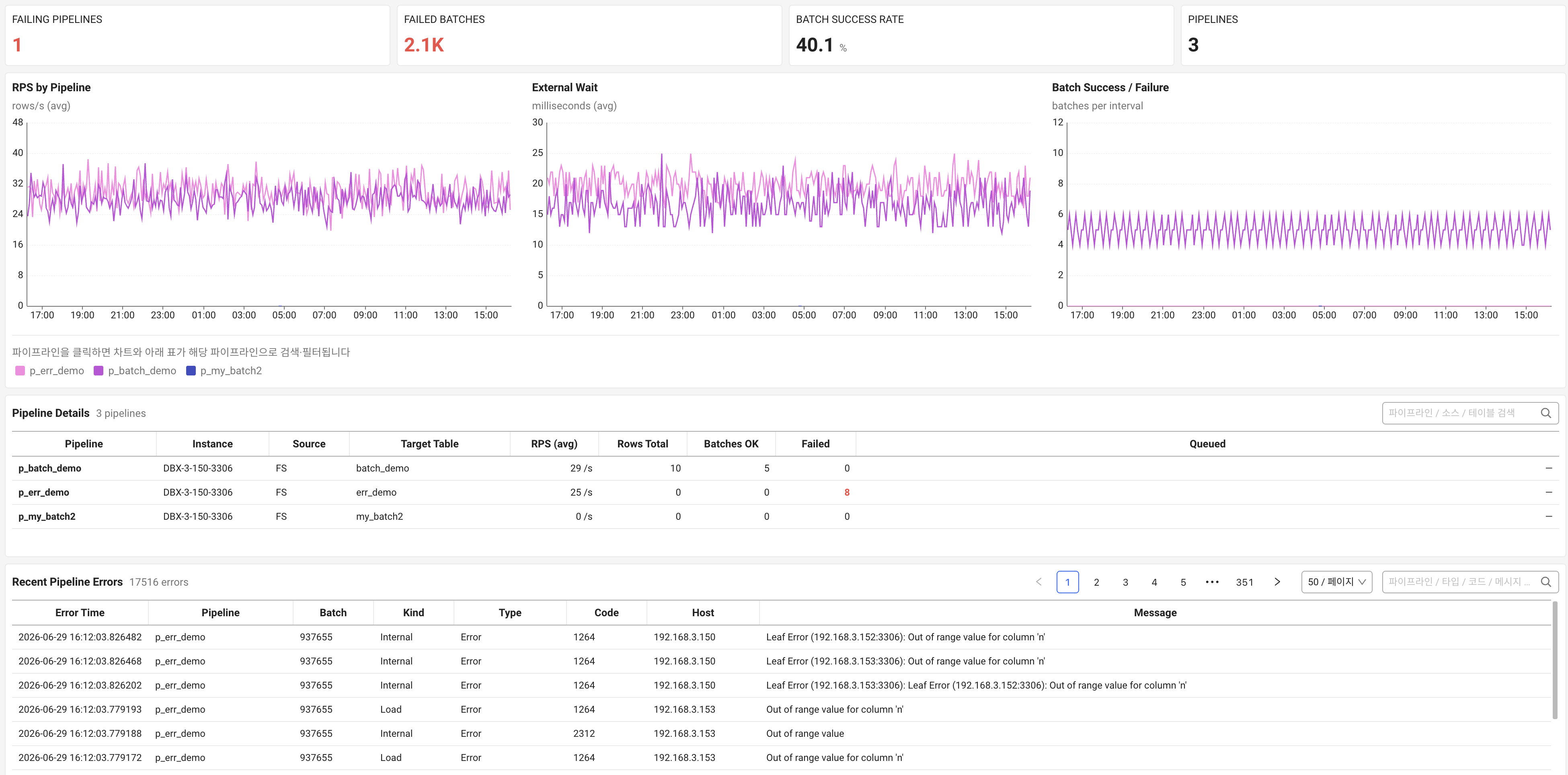
파이프라인 지연, 실시간 적재의 건강 신호
SingleStore에는 SingleStore 파이프라인(SingleStore Pipelines)이라는 데이터 적재 기능이 있습니다. 카프카 같은 소스에서 대량의 데이터를 높은 처리량으로, 정확히 한 번(exactly-once) 의미로 데이터베이스에 흘려 넣는 기능입니다. 실시간 적재를 파이프라인에 맡기는 구성이라면, 파이프라인이 막히는 순간 대시보드가 보는 데이터도 그만큼 과거가 됩니다.
파이프라인에서 봐야 할 신호는 지연과 배치 상태입니다. 소스에 들어온 데이터와 실제 적재 사이의 시차가 벌어지면, 대시보드나 분석 쿼리가 보는 데이터가 그만큼 과거의 것이 됩니다. 배치가 자꾸 실패하거나 재시도가 쌓이면 적재가 막혀 지연이 누적됩니다. 파이프라인이 처리 중 쓰는 메모리도 함께 봐야 하는데, 적재 부하가 리프 노드 메모리 사용량을 높여 다른 쿼리와 자원을 다투기도 하기 때문입니다.
파이프라인은 소스부터 적재 완료까지를 하나의 흐름으로 보고, 어느 단계에서 막히는지를 추적하는 것이 핵심입니다. 적재 지연이 단순히 소스 유입량 증가 때문인지, 특정 리프 노드의 포화 때문인지를 가르려면 앞에서 본 노드별 자원과 스큐 지표를 같이 놓고 봐야 합니다.
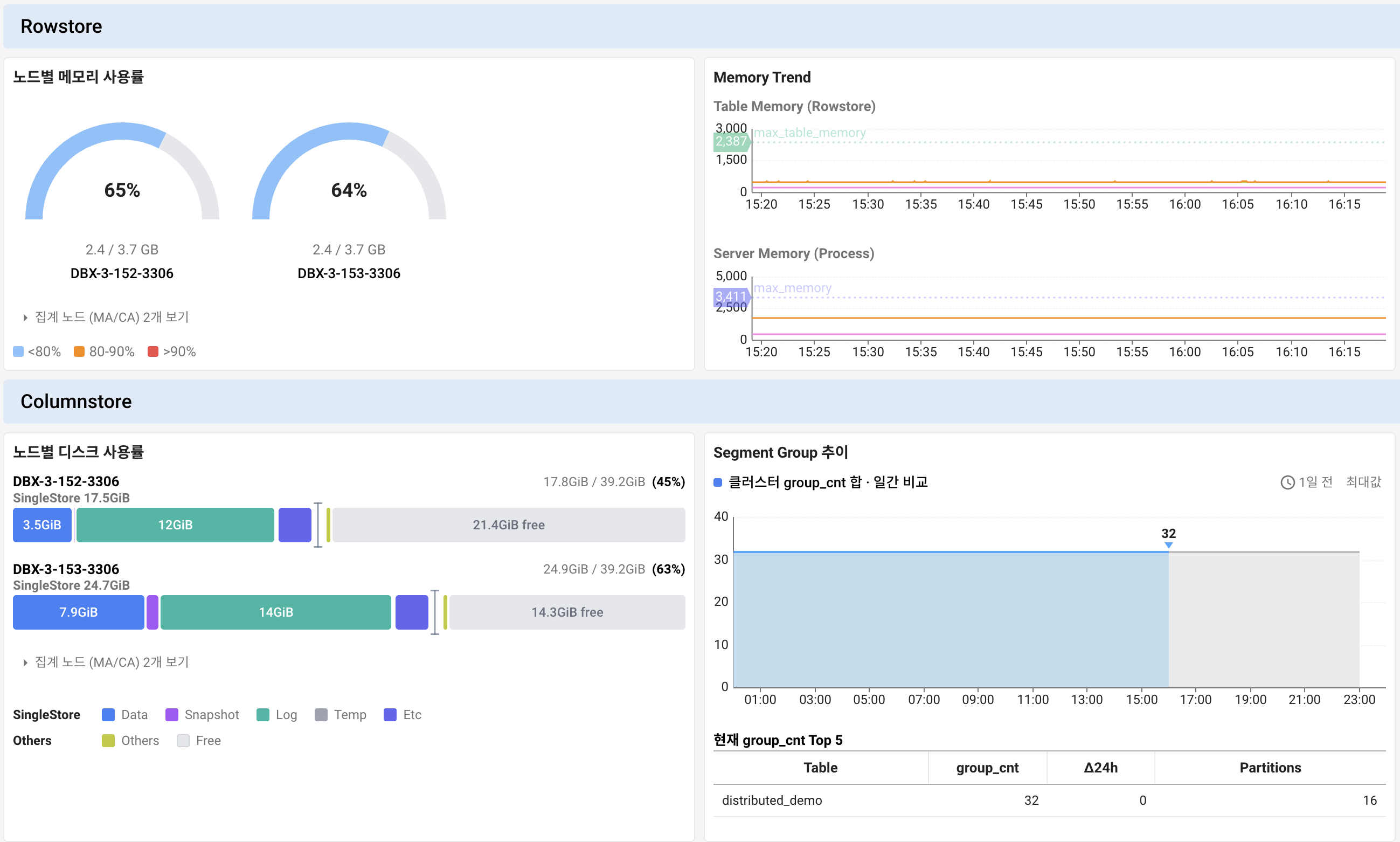
마치며
SingleStore 같은 분산 SQL 데이터베이스를 볼 때는 단일 인스턴스 DB의 평균 지표만으로는 부족합니다. 핵심은 평균에 가려진 편중을 드러내는 것입니다. 노드별로 자원을 분리해 보고, 파티션별 행 수와 메모리 편차로 데이터 스큐를 짚고, 분산 쿼리가 어느 노드와 파티션에서 느린지까지 내려가고, 파이프라인 지연을 적재 흐름 단위로 추적하는 일이 분산 환경 모니터링의 골자입니다. SingleStore에서는 "느린 SQL이 무엇인가"보다 "어느 리프 노드에서 왜 느려졌는가"를 먼저 묻는 것이 분산 환경에 맞는 접근입니다.
SingleStore를 운영하거나 도입을 검토하고 있다면 이 지점들을 한 화면에서 노드별로 분리해 볼 수 있는지를 기준으로 모니터링 도구를 따져보면 좋습니다. 와탭은 애그리게이터와 리프 노드 구조를 자동으로 인식해 노드별 자원, 데이터 스큐, 분산 쿼리, 파이프라인 상태를 통합 화면으로 보여주는 SingleStore 모니터링을 제공합니다. 직접 확인해 보고 싶다면 무료로 체험해 볼 수 있습니다.
더 읽을거리








