.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
AWS와 Azure를 한 곳에서 모니터링하는 방법

서비스를 운영하다 보면 AWS와 Azure를 함께 사용하는 환경이 자연스럽게 생기기도 합니다. 결제 시스템은 AWS에, 사내 시스템은 Azure에 두거나, 인수한 서비스의 환경을 그대로 이어받는 식입니다.
평소에는 큰 문제가 없습니다. 각 클라우드는 맡은 역할을 잘 수행합니다. 하지만 장애가 발생하면 이야기가 달라집니다.
두 개의 브라우저 탭을 번갈아 봅니다. 한쪽은 AWS CloudWatch, 다른 쪽은 Azure Monitor입니다. CloudWatch에서는 Latency, Azure Monitor에서는 Response Time이라는 이름으로 같은 응답시간을 보고 있는데, 지표 이름도 다르고 단위와 집계 방식도 달라 같은 시각의 데이터를 비교하는 일조차 쉽지 않습니다.
워크로드는 각 클라우드에서 잘 돌아가는데도 지표는 각자의 콘솔에 흩어져 있습니다. 같은 현상을 보면서도 두 콘솔을 오가며 서로 다른 기준으로 해석해야 합니다. 문제는 운영이 아니라, 관측이 나뉘어 있다는 점입니다.
두 클라우드의 지표를 함께 보려면 결국 공통 포맷이 필요합니다. AWS CloudWatch와 Azure Monitor의 지표를 Prometheus 노출 포맷(OpenMetrics 규격)이라는 공통분모로 한곳에 모으는 것이 가장 일반적인 접근입니다. 다만 지표를 모으는 것과 한 화면에서 보는 것은 다른 문제입니다. 실제 구축 과정에서 함께 고려해야 할 점까지 짚어 보겠습니다.
같은 것을 보는데도 비교가 어려운 이유
처음 겪었을 때 가장 당황한 건, 같은 응답시간을 보고 있는데도 두 콘솔이 서로 다른 언어를 쓰는 것처럼 느껴졌다는 점이었습니다. CloudWatch와 Azure Monitor는 같은 시스템 상태를 보여 주지만 지표를 저장하고 조회하는 방식은 서로 다릅니다.
- 지표 이름이 다릅니다. 같은 값을 재는데도 두 클라우드가 부르는 이름이 다릅니다.
- 조회 방식이 다릅니다. CloudWatch는 Metrics Insights(SQL과 비슷한 쿼리)로 지표를 뽑고, Azure Monitor 지표는 메트릭 탐색기(Metrics Explorer)로 조회합니다. 한쪽 방식을 다른 쪽에 그대로 옮길 수 없습니다.
- 집계 주기와 단위가 다릅니다. 기본 수집 간격과 시간 단위(초·밀리초)도 서로 달라 그래프를 나란히 놓아도 같은 기준으로 비교하기 어렵습니다.
이름 차이는 생각보다 큽니다. 가상 머신 기본 지표만 봐도 같은 값을 서로 다른 이름으로 표현합니다.
여기에 한 가지 더 알아 둘 차이가 있습니다. 메모리처럼 운영체제 안에서 봐야 하는 값은 두 클라우드의 취급이 다릅니다. AWS EC2는 메모리 사용률이 기본 지표에 없어 별도 에이전트를 설치해야 나옵니다. Azure VM은 여유 메모리(Available Memory) 정도는 에이전트 없이 기본으로 제공하고, 더 상세한 메모리 지표만 에이전트가 필요합니다.
물론 어느 한쪽이 잘못된 것은 아닙니다. CloudWatch와 Azure Monitor는 각각 자기 클라우드 환경에 맞게 설계된 도구입니다. 문제는 두 콘솔을 함께 봐야 하는 순간입니다. 지표 이름과 쿼리 방식, 집계 기준이 서로 달라 운영자는 머릿속에서 계속 기준을 맞춰야 합니다. 장애 상황처럼 시간이 중요한 순간일수록 이런 작은 차이가 원인 분석을 더 어렵게 만듭니다.
공통분모는 Prometheus 노출 포맷입니다
두 콘솔을 계속 오가다 보면 결국 드는 생각은 하나입니다.
"둘 다 같은 형식으로만 볼 수 있으면 좋을 텐데."
실무에서는 이 문제를 두 클라우드의 지표를 하나의 공통 포맷으로 변환해 한곳에 모으는 방식으로 해결합니다. 가장 널리 쓰이는 공통 포맷이 Prometheus 노출 포맷(OpenMetrics)입니다.
원리는 단순합니다. 지표를 내보내는 쪽이 /metrics 주소로 텍스트 형태의 데이터를 노출하면, 수집기가 주기적으로 그 주소를 읽어 옵니다(scrape). 사람이 직접 봐도 이해할 수 있을 만큼 단순한 형식입니다.
# HELP http_requests_total 처리한 HTTP 요청 수
# TYPE http_requests_total counter
http_requests_total{method="GET",status="200"} 12043
물론 CloudWatch와 Azure Monitor가 처음부터 /metrics를 제공하는 것은 아닙니다. 대신 각 클라우드의 API에서 지표를 읽어 Prometheus 포맷으로 다시 노출해 주는 익스포터(exporter)를 사용합니다.
AWS는 CloudWatch API에서 지표를 읽어 Prometheus 포맷으로 변환하는 익스포터를 씁니다. 대표적으로 YACE(Yet Another CloudWatch Exporter)가 있습니다.
Azure도 Azure Monitor 지표를 같은 포맷으로 노출하는 익스포터를 쓸 수 있고, Azure Managed Prometheus 환경에서는 스크레이프 설정으로 바로 수집하기도 합니다.
이렇게 두 익스포터가 각각 /metrics를 제공하면 수집기는 두 주소를 모두 스크레이프해 하나의 백엔드에 저장합니다. 그 이후부터는 CloudWatch 지표와 Azure 지표를 PromQL로 함께 조회할 수 있습니다.
즉, 운영자는 더 이상 AWS와 Azure 지표를 서로 다른 방식으로 다룰 필요가 없습니다. 두 클라우드의 지표를 하나의 관측 데이터처럼 비교하고 분석할 수 있기 때문입니다.
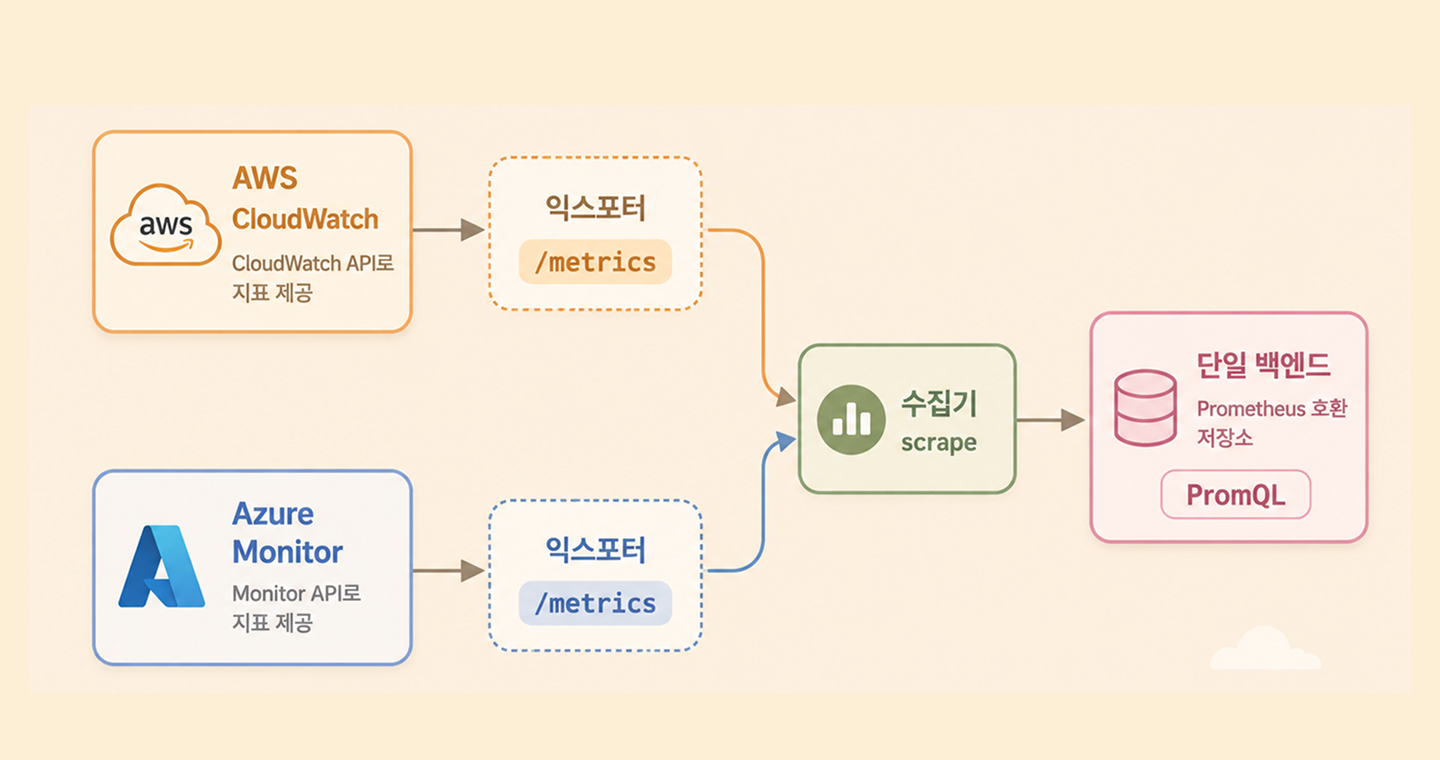
장애가 발생했을 때도 지표를 비교하기 위해 두 콘솔을 계속 오갈 필요는 없어집니다. 적어도 관측 데이터는 하나의 기준으로 조회할 수 있기 때문입니다.
모으는 것과 한 화면에서 보는 것은 다른 일입니다
여기서 하나 더 짚고 넘어갈 점이 있습니다. 지표를 한곳에 모았다고 해서 한 화면이 자동으로 만들어지는 것은 아닙니다.
수집이 끝난 직후에도 CloudWatch 지표와 Azure 지표는 각자 이름과 라벨을 유지한 채 저장됩니다. 결국 한 화면에서 함께 보려면 통합 대시보드를 직접 구성해야 합니다.
보통은 Prometheus 호환 백엔드에 시각화 도구를 연결해 필요한 그래프를 배치하고, PromQL로 두 클라우드의 지표를 같은 패널에 올립니다. 오픈소스로는 Grafana 같은 도구를 많이 쓰고, 이 과정을 대신 해 주는 관리형 서비스를 쓰기도 합니다. 한 번은 직접 구성해야 하는 작업이지만, 이후에는 AWS와 Azure를 하나의 화면에서 계속 확인할 수 있습니다.
대시보드를 구성할 때는 몇 가지를 미리 고려해 두는 편이 좋습니다.
- 라벨 정합: CloudWatch 태그와 Azure 태그의 이름이 다르면 같은 서비스도 서로 다른 대상으로 인식됩니다. 수집 단계에서
service,env같은 공통 라벨로 정리해 두면 쿼리와 대시보드 구성이 훨씬 단순해집니다. - 수집 지연: 클라우드 API를 통해 지표를 가져오는 방식은 실시간이 아닙니다. 특히 CloudWatch는 지표가 확정된 뒤 조회되는 특성 때문에 몇 분 정도 지연될 수 있습니다.
- API 호출 비용: CloudWatch는 지표 조회 API 호출에 비용이 발생합니다. 필요한 지표만 수집하도록 설정하지 않으면 생각보다 비용이 커질 수 있습니다.
자주 묻는 질문
1. AWS와 Azure 지표를 한 번에 볼 수 있나요?
표준 포맷으로 모으면 하나의 저장소에서 같은 쿼리 언어(PromQL)로 다룰 수 있습니다. 다만 한 화면에서 나란히 보는 대시보드는 직접 구성해야 합니다.
2. Azure Monitor 지표는 KQL로 조회하나요?
지표는 메트릭 탐색기(Metrics Explorer)로 봅니다. KQL(Kusto Query Language)은 로그 조회용이라 지표에는 쓰지 않습니다.
3. 메모리 사용률도 기본 지표로 나오나요?
AWS EC2는 메모리 사용률이 기본 지표에 없어 별도 에이전트가 필요합니다. Azure VM은 여유 메모리 정도는 에이전트 없이 기본으로 제공합니다.
마치며
멀티 클라우드 지표를 함께 보는 출발점은 공통 포맷입니다. CloudWatch와 Azure Monitor 지표를 Prometheus 노출 포맷(OpenMetrics 규격)으로 변환해 수집하면, 서로 다른 콘솔을 오가며 기준을 맞추던 작업을 크게 줄일 수 있습니다.
물론 한 화면에서 보기 위한 대시보드는 환경에 맞게 직접 구성해야 하고, 라벨 체계와 수집 주기, API 호출 비용도 함께 고려해야 합니다. 하지만 이런 기준만 잘 잡아 두면 이후에는 두 클라우드를 같은 방식으로 비교하고 분석할 수 있습니다.
AWS와 Azure 지표를 직접 모으고 대시보드까지 구성하기가 부담스럽다면, 이 과정을 관리형으로 제공하는 서비스를 쓰는 방법도 있습니다. 와탭도 클라우드 연동(Integrations)을 지원하니, 멀티 클라우드 모니터링을 무료로 체험해 보시기 바랍니다.
더 읽을거리