.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
CrashLoopBackOff 원인 4가지 구분법

kubectl get pods 를 실행하니 STATUS 칸에 CrashLoopBackOff가 떠 있습니다. 파드는 떴다가 죽고, 또 떴다가 죽기를 반복합니다. 이럴 때 다음에 무엇을 확인해야 할지 몰라 검색하다 이 글에 도착한 분도 많을 것입니다. 결론부터 말하면, 빠르게 해결하는 길은 명령어를 더 많이 외우는 것이 아니라 원인을 먼저 구분하는 데 있습니다. CrashLoopBackOff는 원인마다 남기는 단서가 다르기 때문입니다.
CrashLoopBackOff는 에러가 아니라 증상입니다
CrashLoopBackOff라는 이름만 보면 특정 오류처럼 느껴집니다. 하지만 쿠버네티스에서 이 상태는 "컨테이너가 계속 실패해 재시작 간격(Back-Off)을 점점 늘리고 있다"는 의미입니다. 쉽게 말하면 쿠버네티스가 "계속 죽고 있으니 재시작 간격을 늘리면서 지켜보는 중"이라고 알려 주는 상태입니다.
실무에서는 다양한 이유로 CrashLoopBackOff가 발생하지만, 자주 만나는 원인은 크게 네 가지로 나눠 볼 수 있습니다.
- 메모리 부족(OOMKilled)
- 설정·환경변수 오류
- 의존 서비스 연결 실패
- 헬스체크(livenessProbe) 실패
CrashLoopBackOff 원인을 구분하는 법
네 가지 원인은 각각 결정적인 단서를 하나씩 남깁니다. 그 단서를 알면 "내 경우는 이거구나"를 빠르게 짚을 수 있습니다.
표만 봐도 갈래가 잡히지만, 핵심만 한 번씩 짚어 보겠습니다.
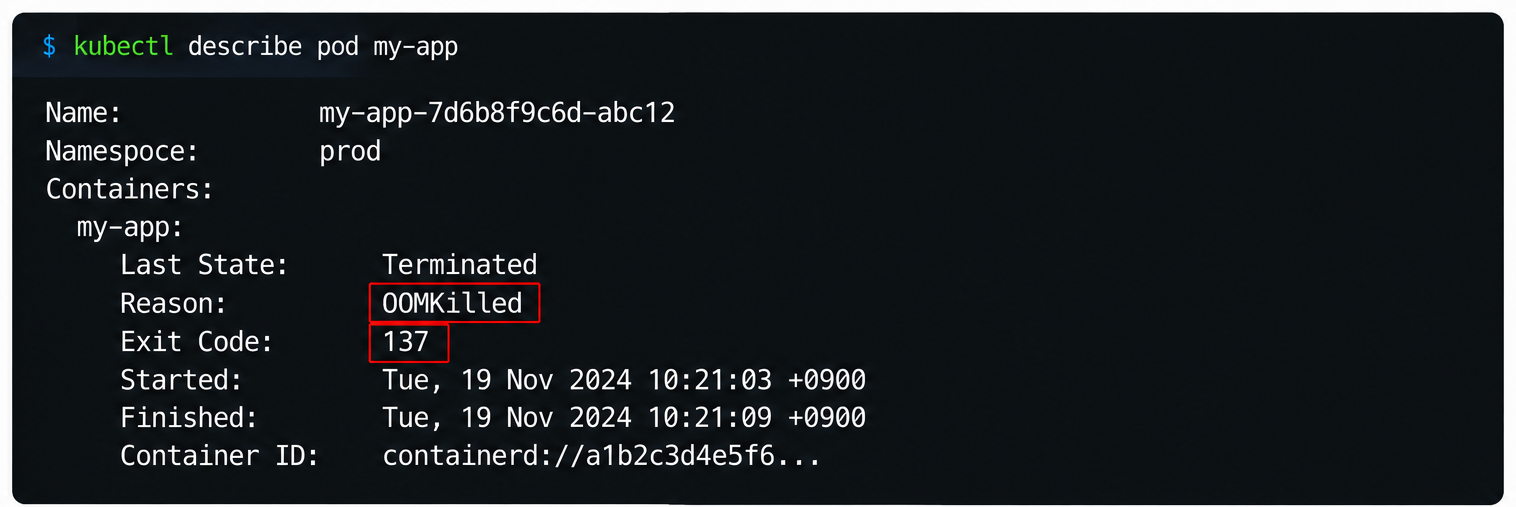
메모리 초과는 컨테이너가 정해 둔 메모리 한도(resources.limits.memory)를 넘어 커널이 프로세스를 강제로 종료한 경우입니다. Exit Code: 137이 보이면 일단 메모리부터 의심하면 됩니다.
설정·환경변수 오류는 컨테이너가 참조하는 ConfigMap·Secret·환경변수가 없거나 형식이 틀린 경우입니다. 앱이 뜨자마자 거의 즉시 죽고, 로그에 config not found 같은 메시지가 떴다 사라집니다.
의존 서비스 미준비는 앱이 데이터베이스나 다른 API에 연결을 시도했는데 상대가 아직 준비되지 않은 경우입니다. connection refused나 dial tcp timeout이 시작 직후부터 반복됩니다.
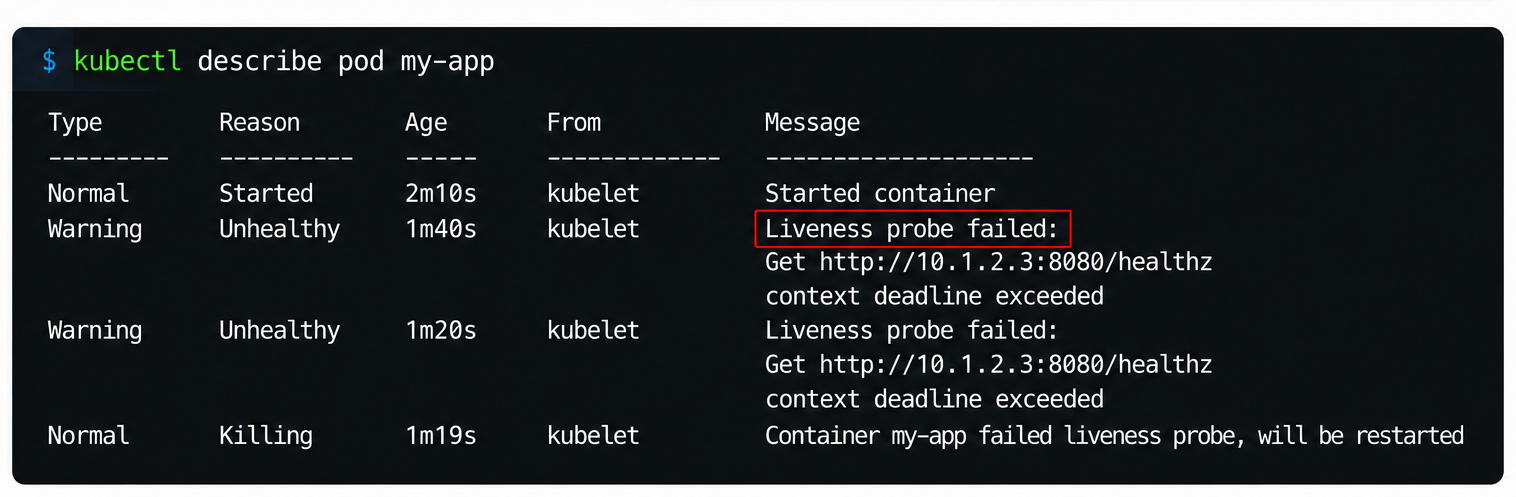
헬스체크 실패는 조금 다릅니다. 앞의 세 경우와 달리 앱이 멀쩡히 실행 중인데도 죽습니다. livenessProbe가 연속으로 실패하면 kubelet이 응답이 없다고 판단해 컨테이너를 강제로 재시작하기 때문입니다. 한참 잘 떠 있다가 죽고 Liveness probe failed 이벤트가 보이면 이 갈래입니다.
의외로 자주 헷갈리는 경우들
원인을 구분하는 게 왜 중요한지는, 자주 일어나는 오판 케이스를 보면 분명해집니다.
하나는 메모리 초과를 앱 버그로 착각하는 경우입니다. Exit Code: 137은 앱이 스스로 잘못된 게 아니라 커널이 메모리 부족 때문에 강제로 종료한 것입니다. 이 숫자를 모르고 로그만 들여다보면 "왜 갑자기 죽지" 하며 코드를 한참 뒤지게 됩니다. 137이라는 단서 하나면 곧장 메모리 한도부터 살피게 됩니다.
메모리 쪽에서 자바 애플리케이션이 특히 잘 빠지는 함정도 있습니다. 컨테이너 메모리 한도를 넉넉히 줬는데도 OOMKilled가 반복되는 경우입니다. JVM은 힙 말고도 클래스 정보, 스레드 스택, 네이티브 메모리를 따로 쓰기 때문에 힙 크기를 컨테이너 한도와 똑같이 잡아 버리면 나머지가 한도를 넘겨 뜨자마자 죽습니다. 한도를 늘리는 것보다 힙을 한도보다 여유 있게 잡는 게 먼저인데, 적절한 메모리 산정은 그 자체로 큰 주제라 여기서는 "OOMKilled가 났다"는 원인를 알아채는 데까지만 짚겠습니다.
또 하나는 멀쩡한 컨테이너를 헬스체크가 죽이는 경우입니다. 예를 들어 livenessProbe의 timeoutSeconds를 1초로 잡아 뒀는데 헬스체크 응답이 평소 1.2초쯤 걸린다면, 앱은 정상인데도 프로브가 자꾸 실패해 결국 멀쩡한 컨테이너를 종료합니다. 임계치를 너무 빡빡하게 잡으면 오히려 문제를 만든다는 점이 핵심입니다.
진단의 진짜 어려움은 시간에 있습니다
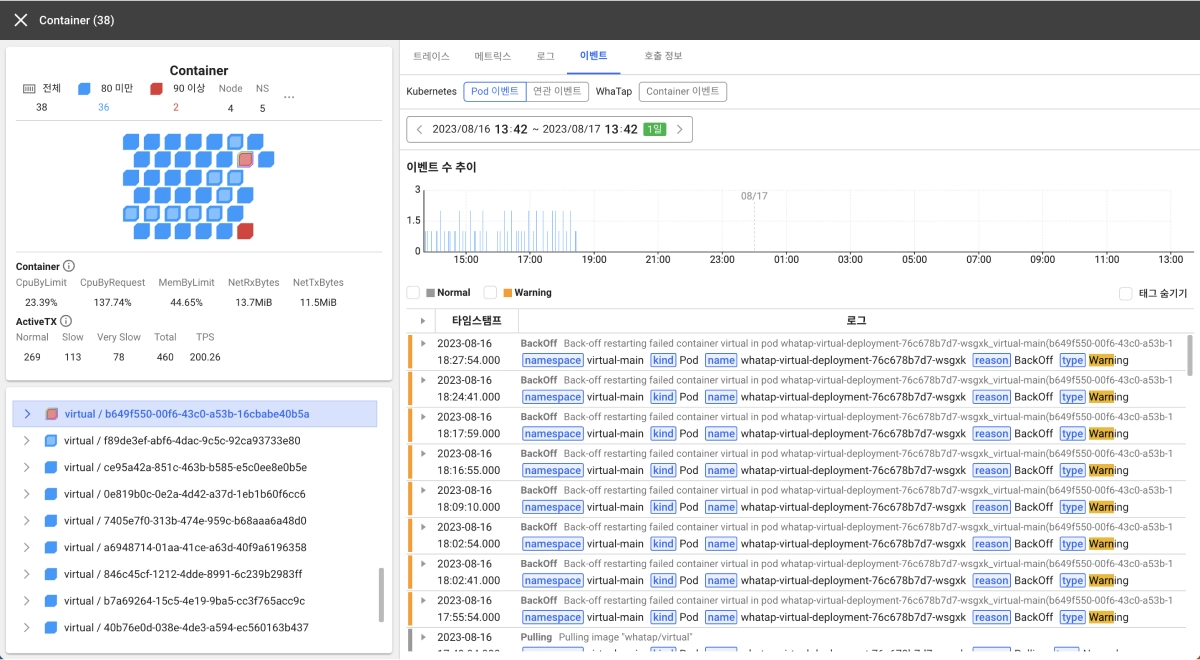
원인을 구분하는 방법을 알아도, 실제 진단에서는 한 가지 어려움이 더 있습니다. 단서가 금방 사라진다는 점입니다. CrashLoopBackOff는 재시작이 반복되는 상태라 이전 컨테이너 로그를 확인할 수 있는 시간이 짧습니다. kubectl logs --previous로 직전 로그를 볼 수 있지만, 이건 바로 직전 1회분만 남습니다. 이미 여러 번 죽었다 살아났다면 정작 처음 죽은 이유는 확인하기 어려울 수 있습니다. 이벤트도 마찬가지로, 재시작이 잦으면 오래된 이벤트가 새 이벤트에 밀려납니다.
게다가 kubectl describe pod는 "OOMKilled가 일어났다"는 결과만 알려 줄 뿐, 메모리가 어떻게 거기까지 갔는지는 보여 주지 않습니다. 특정 요청이 몰려 한순간에 치솟은 것인지, 누수처럼 서서히 차오른 것인지에 따라 대응이 완전히 달라지는데 그 추이는 지나가고 나면 남지 않습니다. 단서를 놓치면 결국 컨테이너가 다음에 또 죽기를 기다렸다 그 순간을 붙잡아야 하고, 진단은 그만큼 늦어집니다.
그래서 지난 상태를 시간 순으로 보존하는 모니터링 체계가 있으면 원인 추적이 한결 수월해집니다. 컨테이너가 죽기 직전 메모리가 어떻게 올라갔는지, 처음 재시작이 언제 시작됐는지를 나중에도 되짚어 볼 수 있기 때문입니다. CrashLoopBackOff처럼 단서가 빨리 휘발하는 문제일수록 시계열 메트릭과 로그 보존이 도움이 됩니다.
마치며
CrashLoopBackOff를 만났을 때 제일 먼저 할 일은 kubectl describe pod로 Exit Code와 이벤트를 보고 네 가지 원인 중 어디인지 가늠하는 것입니다. 137이면 메모리, 즉시 종료에 config 오류면 설정, 연결 오류 반복이면 의존성, 한참 떠 있다 죽으면 헬스체크입니다. 원만 분류할 수 있어도 절반은 푼 셈입니다.
앞에서 본 어려움은 결국 지나간 시점을 되돌려 볼 수 없다는 데 있습니다. 이미 여러 번 재시작된 뒤라면 처음 죽었을 때의 로그와 이벤트는 확인하기 어려울 수 있습니다. 만약 컨테이너별 재시작 이력과 메모리 추이, 종료된 컨테이너의 로그까지 시간 순으로 남아 있다면 어떨까요. 이미 여러 번 재시작된 뒤에도 처음 죽은 순간으로 돌아가 메모리가 한순간에 치솟았는지, 서서히 증가했는지 확인할 수 있다면, 다시 죽기를 기다릴 필요 없이 훨씬 편하게 원인을 짚을 수 있을 것입니다.
와탭 Kubernetes 모니터링을 15일 무료로 사용하면서 남아 있는 기록으로 직접 원인을 추적해 보는 것도 방법입니다.
다음 편에서는 비슷하게 헷갈리는 ImagePullBackOff, 즉 이미지를 받아 오지 못해 파드가 뜨지 못하는 경우를 다뤄 보겠습니다.
더 읽을거리
.png)