.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
Java 모니터링 완벽 가이드: JVM·JMX부터 APM까지

IT 리서치 기관 ITIC의 2024년 조사에 따르면, 중견·대기업의 90% 이상이 IT 다운타임 1시간당 30만 달러(약 4.3억 원) 이상의 손실을 본다고 응답했습니다. 이 가운데 41%는 시간당 100만 달러에서 500만 달러 이상의 손실이 발생한다고 답했습니다.
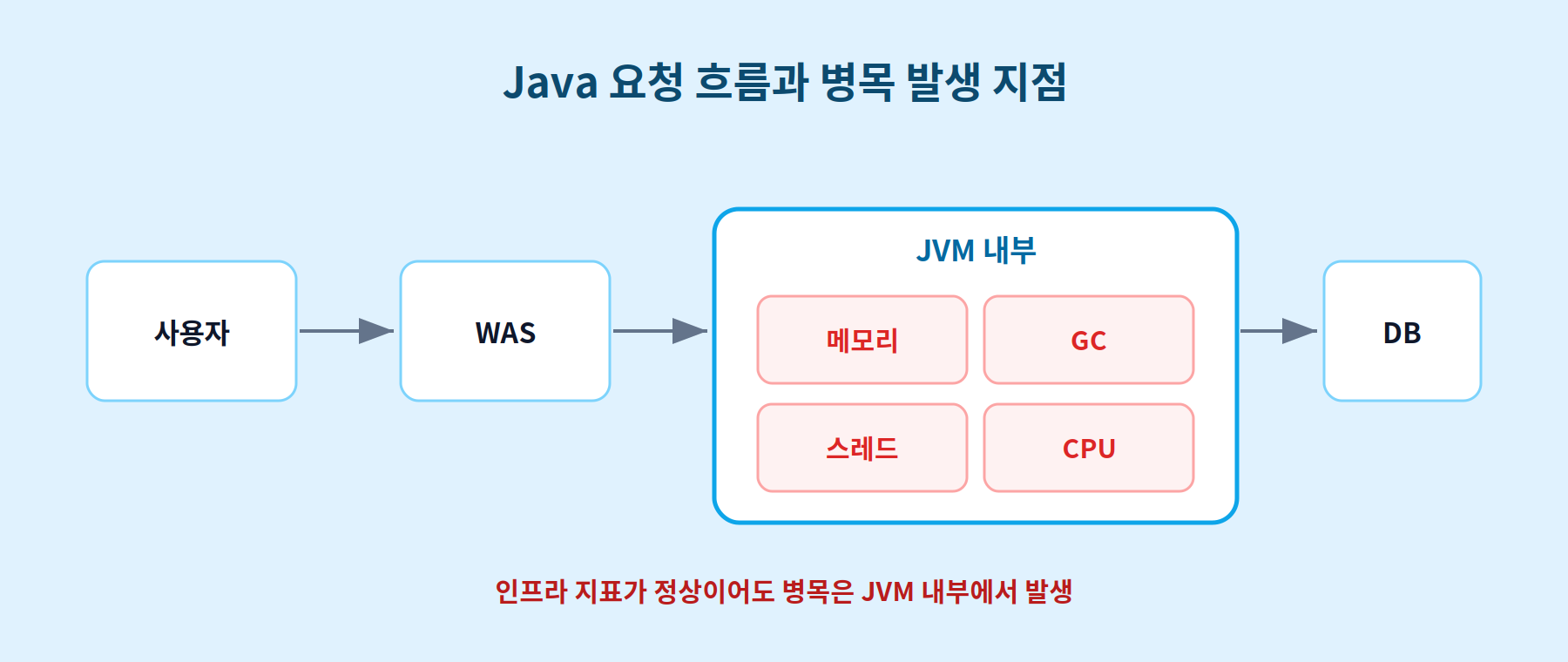
서버 CPU도 메모리도 멀쩡한데, 고객은 "서비스가 느리다"고 말합니다. 로그를 봐도 뚜렷한 에러가 없습니다. 이럴 때 원인은 인프라가 아니라 JVM 내부에 숨어 있는 경우가 많습니다.
문제는 이 지연이 그대로 비용이 된다는 점입니다. 장애로 잡히지도 않은 채 손실만 쌓입니다. 이 글은 JVM의 어디를 봐야 하는지, 어떤 도구로 확인하는지, 운영 환경에서는 무엇이 더 필요한지를 순서대로 짚어 드립니다.
JVM 모니터링이 필요한 이유: 에러는 결과일 뿐, 원인은 안에 있습니다
사용자가 보는 503 에러나 응답 지연은 대부분 결과입니다. 진짜 원인을 찾으려면 애플리케이션을 실제로 돌리는 엔진, 즉 JVM 안을 들여다봐야 합니다.
JVM 모니터링은 이 내부 상태를 계속 지켜보면서 병목의 원인을 찾는 일입니다. 운영 환경에서 꼭 챙겨야 할 지표는 네 가지입니다.
첫째, 메모리(Heap)입니다. 다 쓴 객체가 회수되지 않고 계속 쌓이는 현상을 메모리 누수라고 합니다. 이때 메모리 사용량이 계단처럼 늘어납니다. 그대로 두면 결국 OutOfMemoryError가 발생합니다. 대용량 파일 처리나 캐시 로직에서 자주 나타납니다. 그래서 메모리 사용량이 어떻게 늘고 주는지, 그 흐름을 보는 것이 점검의 시작입니다.
둘째, GC(Garbage Collection)입니다. GC는 안 쓰는 객체를 자동으로 치워주는 기능입니다. 그런데 청소하는 동안에는 애플리케이션이 잠깐 멈춥니다. 이 멈춤을 'Stop-the-World'라고 부릅니다. GC가 너무 자주 돌면 CPU를 잡아먹고, 멈추는 시간이 길어질수록 응답도 그만큼 느려집니다. 그래서 GC는 '몇 번 발생했는지'와 '얼마나 오래 멈췄는지'를 함께 봐야 합니다. 특히 부하가 큰 Full GC가 잦으면 사용자는 주기적인 끊김을 체감합니다.
셋째, 스레드(Thread)입니다. 스레드는 요청을 실제로 처리하는 일꾼입니다. 이 일꾼들이 서로의 자원을 기다리며 멈춰버리는 경우가 있습니다. 이것을 교착 상태(Deadlock)라고 합니다. 또 한 작업이 일꾼을 전부 차지하면, 새 요청을 받을 일꾼이 남지 않습니다. 어떤 스레드가 무엇을 기다리는지 확인하려면 스레드 덤프를 떠서 들여다봐야 합니다.
넷째, CPU입니다. 비효율적인 반복 연산이나 무한 루프에 가까운 코드가 한 스레드의 CPU를 과하게 차지할 때가 있습니다. 그러면 전체 처리량이 급격히 떨어집니다.
이 네 가지는 서로 독립적으로 움직이지 않습니다. 메모리 누수가 GC를 늘리고, 과도한 GC가 CPU를 점유합니다. 그 영향으로 요청을 처리하는 스레드까지 지연됩니다. 그래서 하나만 보면 안 되고, 메모리·GC·스레드·CPU를 함께 봐야 합니다.
그런데 이 지표들을 함께 보려면, 먼저 '볼 수 있는 환경'부터 갖춰야 합니다.
모니터링이 없으면 트러블슈팅은 '추측'이 됩니다
모니터링이 없는 상태에서 장애가 발생하면 담당자는 일단 서버에 접속해 로그를 수동으로 확인하는 것부터 시작합니다. 문제는 이 방법이 장애가 '지금 재현되고 있을 때만' 유효하다는 점입니다.
한 개발팀에서는 매번 15초나 걸리는 느린 기능이 2년 동안 방치된 적이 있습니다. 에러가 발생하지 않았기 때문입니다. 나중에 모니터링 도구로 발견한 뒤에는 원인 파악과 수정에 1시간도 걸리지 않았습니다. 15초였던 응답을 100ms 수준까지 줄였습니다. 모니터링이 없었다면 그 기능은 계속 방치되었을 것입니다.
모니터링이 없을 때 자주 겪는 문제는 다음과 같습니다.
- 재현되지 않는 장애는 추적이 어렵습니다. 새벽에 잠깐 발생했다 사라진 장애는 그 시점 데이터가 없으면 원인을 찾기 어렵습니다.
- 복구가 늦어집니다. 문제 지점을 찾지 못하니 일단 서버를 재시작하는 임시방편에 기대게 됩니다.
- 같은 문제가 반복됩니다. 그때그때 복구해도 원인을 모르면 다음에 다시 발생합니다.
결국 모니터링은 모든 장애를 막아주는 장치가 아닙니다. 장애가 났을 때 '무슨 일이 있었는지 설명할 수 있게' 해주는 출발점입니다.
그렇다면 JVM 내부 상태는 대체 어떤 경로로 꺼내 보는 것일까요?
JMX란? JVM 내부 지표를 밖으로 꺼내주는 표준 창구
JVM 안의 메모리·GC·스레드 정보는 어떻게 꺼내 볼까요? 그 표준 통로가 바로 JMX(Java Management Extensions)입니다.
JMX는 Java 애플리케이션의 상태를 관리하고 모니터링하기 위한 표준 규격입니다. 뒤에서 소개할 jconsole을 비롯한 여러 도구가 이 JMX를 통해 JVM의 상태를 가져옵니다.
JMX는 어떻게 동작하나
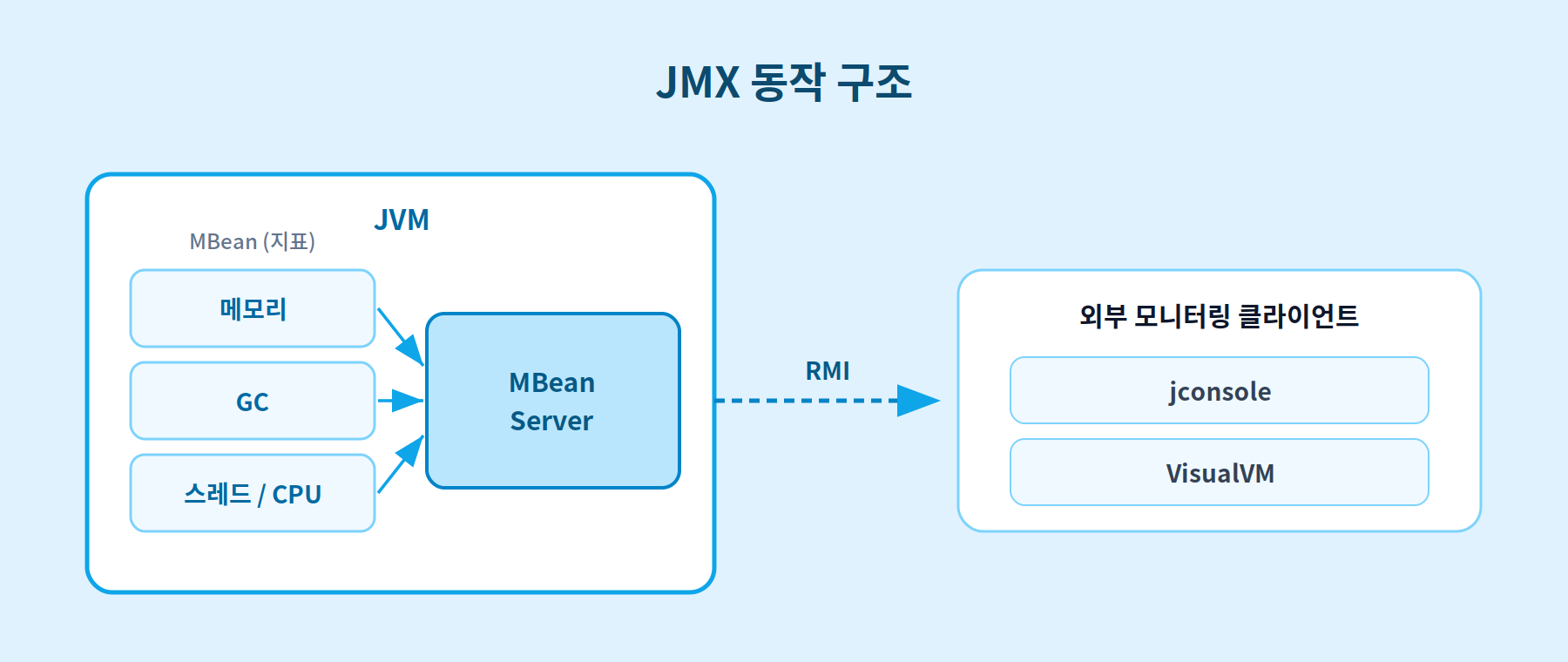
JMX의 핵심은 MBean(Managed Bean)입니다. JVM 안에서 들여다보고 싶은 대상을 밖에서 조회할 수 있도록 객체 형태로 꺼내놓은 것이라고 보면 됩니다. JVM은 기본으로 다음 정보를 제공합니다.
- 메모리 정보: Heap과 Non-Heap 사용량
- GC 정보: 발생 횟수와 누적 소요 시간
- 스레드 정보: 활성 스레드 수, 교착 상태 감지, 스레드별 CPU 시간
- 시스템 정보: 프로세스 CPU 사용률과 시스템 부하
이 정보들은 JVM 안의 MBean Server라는 곳에 모입니다. 그러면 jconsole 같은 외부 도구가 이 서버에 접속해 값을 읽어갑니다.
정리하면, JMX는 JVM 내부의 지표를 표준화된 창구를 통해 밖으로 내보내는 규격입니다
원격 서버의 JVM에 접속하려면
다른 서버에서 돌아가는 JVM을 모니터링하려면 애플리케이션을 띄울 때 JMX 옵션을 붙여야 합니다.
-Dcom.sun.management.jmxremote.port=[포트]
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
-Djava.rmi.server.hostname=[서버 IP]설정이 끝나면 외부 도구가 원격으로 JVM에 접속할 수 있습니다.
다만 위 예시는 인증과 암호화를 꺼둔 구성이라 보안에 취약합니다. 운영 환경에서는 그대로 쓰면 안 됩니다. 실제로는 인증과 암호화, 접근 가능한 네트워크 범위, 포트와 방화벽 정책까지 함께 설계해야 합니다. 이런 설정과 보안 관리 부담은 원격 모니터링의 진입 장벽이 되기도 합니다.
이 JMX를 실제로 활용하는 도구들을 하나씩 살펴보겠습니다.
Java 모니터링 툴 비교: jstat, jconsole, VisualVM
Java 환경에서는 유료 솔루션 없이도 JVM 상태를 확인할 수 있는 도구가 여럿 있습니다. 대표적으로 JDK에 포함된 jstat과 jconsole, 그리고 따로 설치해 쓰는 VisualVM이 있습니다.
로컬이나 개발 환경에서 상태를 빠르게 점검할 때 쓰는 세 가지를 비교하면 다음과 같습니다.
jstat: 명령어로 GC 빠르게 보기
jstat은 화면(GUI)을 쓰기 어려운 서버 환경에서 GC와 메모리 상태를 빠르게 확인하기 좋습니다.
다음 명령으로 실행합니다.
jstat -gcutil <pid> <interval>출력에서는 무거운 청소(Full GC)가 몇 번 일어났는지, 거기에 시간이 얼마나 쌓였는지 등을 볼 수 있습니다. 이 수치가 짧은 시간에 급격히 오른다면, JVM이 메모리를 충분히 확보하지 못한 채 청소를 반복하고 있다는 신호일 수 있습니다.
다만 이 수치는 계속 더해지는 누적 값입니다. 그래서 한 시점의 숫자보다, 일정 시간 동안 얼마나 빠르게 늘어나는지를 봐야 합니다.
jconsole·VisualVM: 화면으로 스레드와 메모리 살펴보기
jconsole과 VisualVM은 상태를 그래프와 화면으로 보여줍니다.
jconsole은 메모리 사용량, 스레드 수 같은 정보를 실시간으로 보여줍니다. 교착 상태를 감지하거나, 각 스레드가 무슨 일을 하고 있는지 확인할 때도 쓸 수 있습니다.
VisualVM은 한 발 더 나아갑니다. 상태 모니터링은 물론, 어떤 코드가 느린지 추적하는 프로파일링, 메모리·스레드 덤프 분석까지 한 화면에서 제공합니다. 덕분에 특정 스레드가 CPU를 과하게 쓰는 문제 등을 진단할 수 있습니다.
참고로 VisualVM은 지금은 기본 포함되지 않으므로, visualvm.github.io에서 따로 내려받아 설치해야 합니다.
여기까지는 개발 환경 이야기입니다. 막상 실서비스에 올리면 이 도구들이 다르게 보이기 시작합니다.
운영 환경에서 드러나는 내장 툴의 한계
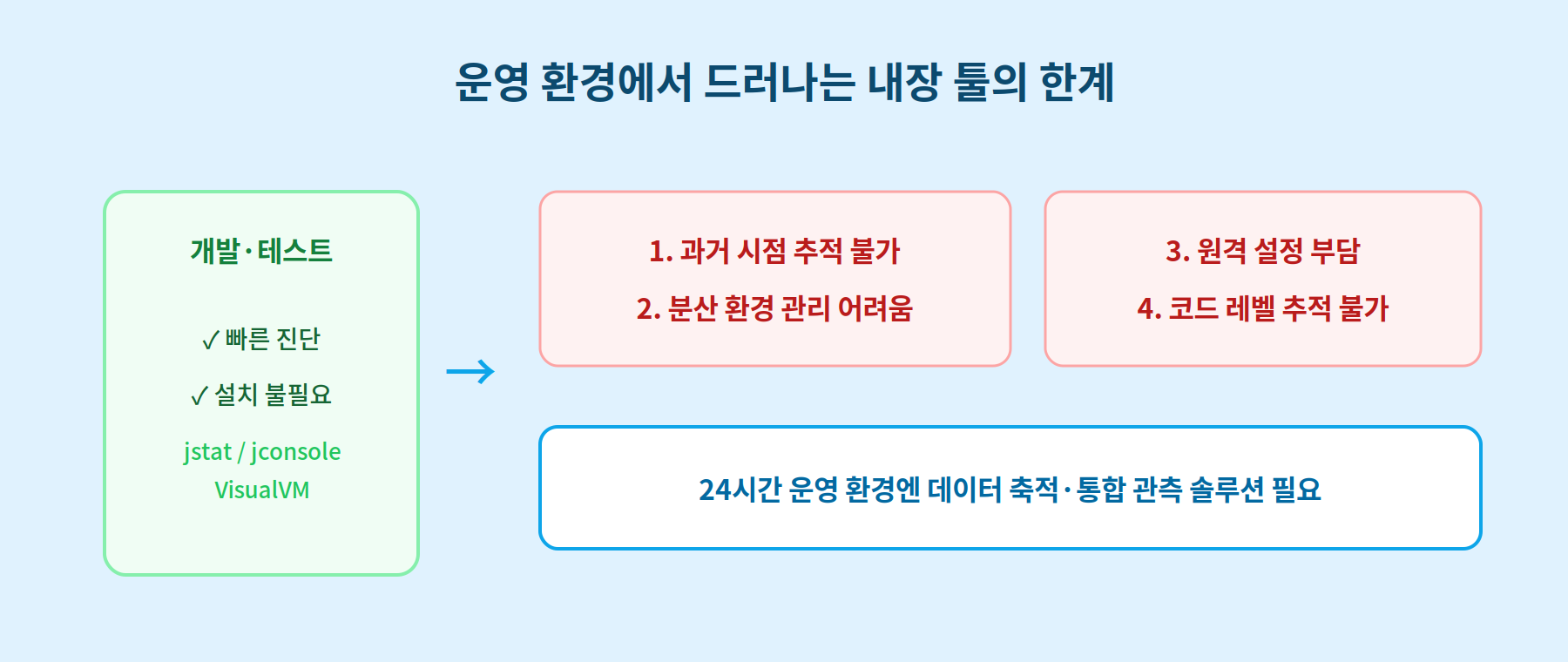
jstat, jconsole, VisualVM은 강력한 도구입니다. 다만 기본적으로 사람이 특정 JVM에 직접 붙어서 상태를 보는 용도로 만들어졌습니다. 서버가 24시간 돌아가는 실서비스 환경에서는 다음 한계에 부딪힙니다.
첫째, 과거 시점을 보기 어렵습니다. jconsole이나 VisualVM은 지금 연결된 순간의 데이터만 보여줍니다. 새벽 3시에 난 장애를 오전 9시에 조사하려 해도, 그때 데이터가 저장돼 있지 않으면 분석할 수 없습니다.
둘째, 여러 서버를 관리하기 번거롭습니다. 서비스를 여러 개로 쪼개 운영하거나 서버가 여러 대면, 서버마다 일일이 연결 정보를 관리해야 합니다. 수십 대의 상태를 한 화면에서 보기도 어렵습니다.
셋째, 원격 접속 설정이 까다롭습니다. 원격으로 보려면 앞서 본 옵션 설정에 더해 포트와 방화벽까지 손봐야 합니다. 보안 정책이 엄격한 곳에서는 이 설정 자체가 부담입니다.
넷째, 어디서 문제가 났는지까지는 알려주지 않습니다. 내장 도구는 "메모리가 높다", "스레드가 많다" 같은 상태는 보여줍니다. 하지만 정작 어떤 기능, 어떤 코드에서 문제가 났는지까지는 연결해 주지 않습니다. 결국 덤프를 떠서 담당자가 손으로 분석해야 합니다.
이것은 도구의 결함이 아니라 용도의 차이입니다. 이 도구들은 개발·테스트 단계에서 특정 JVM을 그때그때 진단하기에 적합합니다. 반면 24시간 운영 환경에서는 데이터를 계속 모아 쌓고, 여러 서버를 한꺼번에 볼 수 있는 별도 솔루션이 필요합니다.
그럼 그 '별도 솔루션'은 실제로 무엇을 다르게 해줄까요?
와탭(WhaTap)으로 보는 운영 환경의 Java 모니터링
와탭랩스(WhaTap Labs)의 Java 모니터링은 앞서 본 내장 도구의 한계를 운영 관점에서 보완합니다. 핵심 차이는 세 가지입니다.
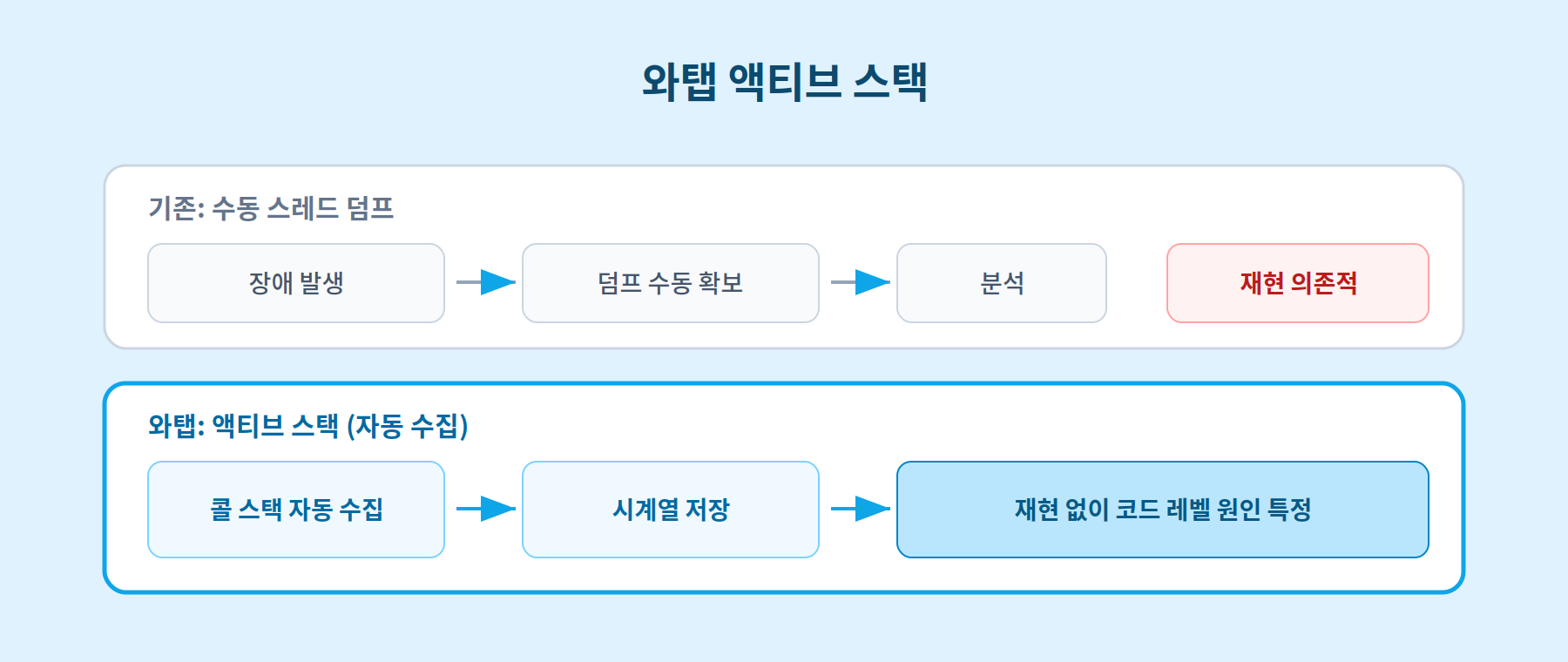
1. 덤프를 뜨지 않아도 '액티브 스택'으로 원인을 바로 찾습니다
와탭은 실행 중인 트랜잭션이 지금 어떤 코드(메소드)를 지나고 있는지를 기본 10초마다 모아 저장합니다. 이 기록을 액티브 스택(Active Stack)이라고 합니다. 수집 주기는 조절할 수 있습니다.
덕분에 장애를 다시 재현하거나 덤프를 손으로 뜨지 않아도 됩니다. 이미 저장된 기록만 보고도 어떤 코드 구간에서 지연이 났는지 바로 추적할 수 있습니다. 액티브 스택은 와탭의 특허 기술(출원번호 10-2020-0037381)입니다.
2. 복잡한 호출 관계도 사각지대 없이 추적합니다
서비스를 여러 개로 쪼개 운영하면 서로 호출하는 관계가 복잡하게 얽힙니다. 와탭은 이 호출 관계를 화면으로 그려주고, 시점별로 어떻게 변하는지까지 보여줍니다.
또 눈에 잘 안 띄는 백그라운드 작업까지 추적하는 옵션을 제공합니다. 화면에 보이는 요청만 보다가 놓치는 사각지대를 줄일 수 있습니다.
데이터베이스 모니터링과 연계하면, 애플리케이션의 지연이 데이터베이스 문제와 연결돼 있는지도 한 흐름에서 확인할 수 있습니다.
3. SaaS형으로 약 5분 만에 도입합니다
서버마다 포트를 열고 도구를 연결하는 과정이 없습니다. 작은 프로그램(에이전트)을 설치하고 키만 입력하면 됩니다. 그러면 통합 대시보드에서 여러 서버를 한 화면으로 모니터링할 수 있습니다.
수집된 데이터는 시간 순서대로 쌓입니다. 그래서 새벽에 난 장애도 그 시점으로 돌아가 분석할 수 있습니다. 실시간 확인은 물론 과거 장애 분석까지 됩니다.
결론: '운영 단계'에 맞는 전략을 고르세요
Java 성능 병목의 진짜 원인은 겉으로 보이는 에러가 아니라 JVM 안의 메모리·GC·스레드·CPU에 있을 수 있습니다. JMX는 이 내부 지표를 밖으로 꺼내주는 표준 통로이고, jstat·jconsole·VisualVM은 로컬과 개발 환경에서 상태를 빠르게 진단하도록 돕습니다.
다만 24시간 운영 환경에서는 요건이 더해집니다. 과거 시점 추적, 여러 서버 통합 관측, 어떤 코드에서 문제가 났는지까지 짚어내는 분석이 필요해집니다.
핵심은 '어떤 도구가 더 좋은가'가 아니라 '지금 우리 시스템이 어느 단계에 있는가'입니다. 개발·테스트에서는 기본 도구로 충분할 수 있지만, 서비스 규모와 복잡도가 커질수록 데이터를 계속 모으고 통합 분석할 수 있는 APM이 필요합니다.
모니터링은 장애를 막는 도구가 아니라, 장애가 났을 때 그 원인을 설명할 수 있게 해주는 운영의 언어입니다.
운영 환경의 Java 모니터링 전략을 검토하고 있다면 와탭의 Java 모니터링을 직접 확인해 보세요.