.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
Nginx 모니터링, OpenMetrics 템플릿으로 5분 만에 시작하기

웹 서비스의 최전선에는 거의 항상 Nginx가 자리합니다. 리버스 프록시, 로드 밸런서, API 게이트웨이, 정적 파일 서버까지 다양한 역할을 수행하며 트래픽의 첫 관문 역할을 담당합니다. 그렇기 때문에 Nginx의 상태를 정확히 파악하지 못하면, 그 뒤에 놓인 애플리케이션과 데이터베이스의 문제 또한 제대로 진단하기 어렵습니다.
문제는 Nginx 모니터링이 생각보다 까다롭다는 점입니다. 기본 stub_status 모듈만으로는 활성 커넥션 수 정도만 확인할 수 있고, Prometheus와 Grafana 스택을 직접 구축하자니 초기 설정과 운영에 드는 공수가 만만치 않습니다.
이 글에서는 Nginx 모니터링이 왜 어려운지, 그리고 와탭 OpenMetrics의 Nginx 템플릿이 이 문제를 어떻게 5분 만에 해결하는지 실제 화면과 함께 살펴봅니다.
Nginx 기본 모니터링, 무엇이 부족한가
Nginx가 자체적으로 제공하는 모니터링 수단은 오픈소스 버전 기준 ngx_http_stub_status_module입니다. 해당 모듈을 활성화한 뒤 엔드포인트에 접근하면 다음과 같은 정보를 확인할 수 있습니다.
Active connections: 291
server accepts handled requests
16630948 16630948 31070465
Reading: 6 Writing: 179 Waiting: 106이 정보가 알려주는 것은 제한적입니다.
- 현재 활성 커넥션 수
- 누적 수용, 처리, 요청 카운터
- Reading / Writing / Waiting 상태 분포
하지만 운영 현장에서 실제로 확인하고 싶은 질문은 이보다 훨씬 구체적입니다.
- “지금 4XX 에러가 얼마나 발생하고 있나?”
- “어떤 메서드와 어떤 URL이 가장 느린가?”
- “p95 응답 지연이 SLA를 넘기고 있지 않은가?”
- “특정 인스턴스에만 502 에러가 몰리고 있지는 않은가?”
이런 질문에 답하려면 stub_status만으로는 부족합니다. Nginx Plus를 도입하면 일부 문제를 해결할 수 있지만 라이선스 비용이 발생합니다. 오픈소스 환경에서는 결국 두 가지 Exporter를 조합하는 방식이 사실상의 표준에 가깝습니다.
전자는 “지금 커넥션이 어떻게 흐르고 있는가”를 보여주고, 후자는 “들어온 요청이 어떻게 처리되었는가”를 보여줍니다. 두 데이터를 함께 봐야 비로소 Nginx의 전체 상태를 입체적으로 파악할 수 있습니다.

직접 구축의 현실, 왜 며칠이 걸리는가
Exporter 두 개를 띄우는 것 자체는 어렵지 않을 수 있습니다. 진짜 비용은 그 이후에 발생합니다.
직접 구축하려면 보통 다음과 같은 단계를 거쳐야 합니다.
- Nginx에
stub_status활성화 및 접근 제어 설정 - 액세스 로그 포맷을 Exporter가 파싱 가능한 형태로 표준화
- nginx-prometheus-exporter 배포 및 스크래핑 타겟 등록
- prometheus-nginxlog-exporter 배포 및 로그 경로 마운트
- Prometheus 서버에 두 타겟 추가 및 라벨링 정책 수립
- Grafana 대시보드 직접 설계어떤 패널을, 어떤 PromQL로, 어떻게 배치할지 결정
- 알람 룰 작성4XX 비율 임계치, p95 지연, 인스턴스 다운 등
- TSDB 보관 정책, 카디널리티 관리
공개된 Grafana 대시보드(예: grafana.com에 등록된 Nginx 대시보드)를 그대로 import하면 기본 화면은 수 시간 안에 띄울 수 있습니다. 그러나 자사 환경에 맞는 라벨 정책, 알람 임계치, 패널 구성을 다듬는 단계에서 시간이 본격적으로 들기 시작합니다. 팀이 Prometheus 운영 경험이 적다면 검증·튜닝 과정에서 며칠이 추가로 소요되는 경우가 많습니다.
더 큰 문제는 이렇게 만든 대시보드가 팀마다 제각각이라는 점입니다. 어떤 팀은 RPS를 메인 패널로 두고, 어떤 팀은 커넥션 수를 우선적으로 봅니다. 알람 임계치 역시 팀별로 다르게 설정되는 경우가 많습니다.
운영자가 진짜로 원하는 것은 매번 처음부터 대시보드를 설계하는 일이 아닙니다. 이미 검증된 베스트 프랙티스가 반영된 화면을 즉시 적용하고, 그 위에서 빠르게 문제를 해석하는 것입니다. 와탭 OpenMetrics Nginx 템플릿이 해결하는 지점이 바로 여기에 있습니다.
화면으로 보는 와탭 Nginx 템플릿
엔드포인트만 등록하면, 운영 현장에서 바로 활용할 수 있는 대시보드가 자동으로 구성됩니다. 실제 화면을 기준으로 살펴보겠습니다.
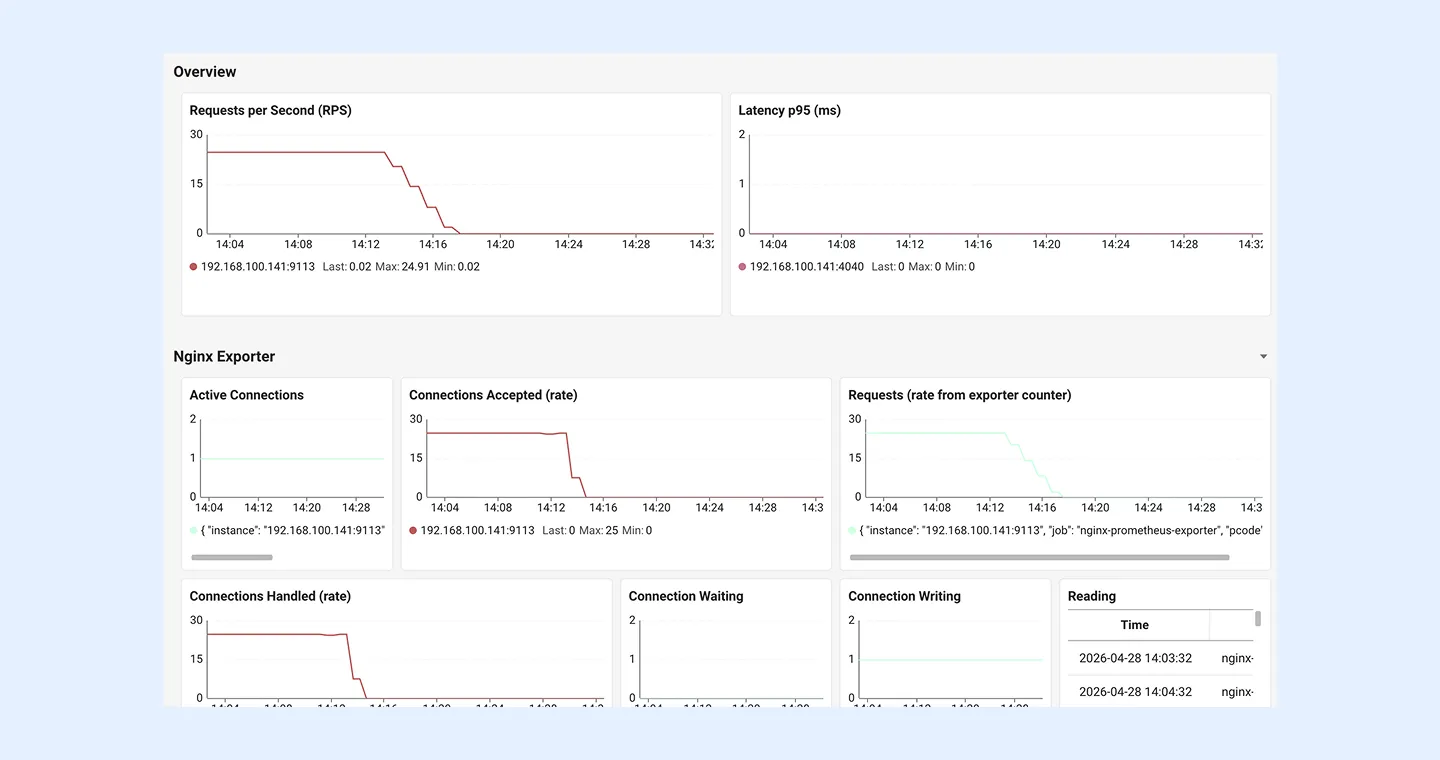
Overview: 한 화면 요약
가장 위에 배치된 Overview 영역은 운영자가 가장 먼저 확인해야 할 두 가지 핵심 지표를 보여줍니다.
- Requests per Second (RPS): 초당 요청 수. 트래픽 급증 또는 급감 시점을 즉시 식별할 수 있습니다.
- Latency p95 (ms): 95퍼센타일 응답 지연. 평균이 아닌 p95를 사용하는 이유는 사용자 경험에 실제 영향을 주는 “느린 요청”의 흐름을 추적하기 위해서입니다.
위 화면에서는 14:14 무렵 RPS가 약 25에서 0으로 급격히 하락한 구간이 명확히 드러납니다. 이러한 패턴은 단순한 트래픽 변화일 수도 있고, 업스트림 장애의 신호일 수도 있습니다. 따라서 장애 분석의 1차 분류 신호로 활용할 수 있습니다.
Nginx Exporter: 커넥션 레벨 추적
같은 화면 하단의 Nginx Exporter 영역은 stub_status 기반 메트릭을 다섯 개 패널로 나누어 보여줍니다.
- Active Connections: 현재 처리 중인 활성 커넥션 수
- Connections Accepted (rate): 초당 신규 수용 커넥션
- Connections Handled (rate): 초당 처리 완료 커넥션
- Connection Waiting / Writing / Reading: 상태별 커넥션 분포
여기서 Accepted와 Handled의 차이는 커넥션 거부 발생 여부를 판단하는 핵심 단서입니다. 두 값이 일치하지 않는다면 worker_connections 한도에 도달했을 가능성을 의심해볼 수 있습니다.
직접 구축한다면 이러한 차이를 시각화하는 패널을 별도로 설계해야 합니다. 하지만 와탭 OpenMetrics Nginx 템플릿에는 이 구성이 이미 포함되어 있어, 운영자는 별도의 대시보드 설계 없이 바로 상태를 확인할 수 있습니다.
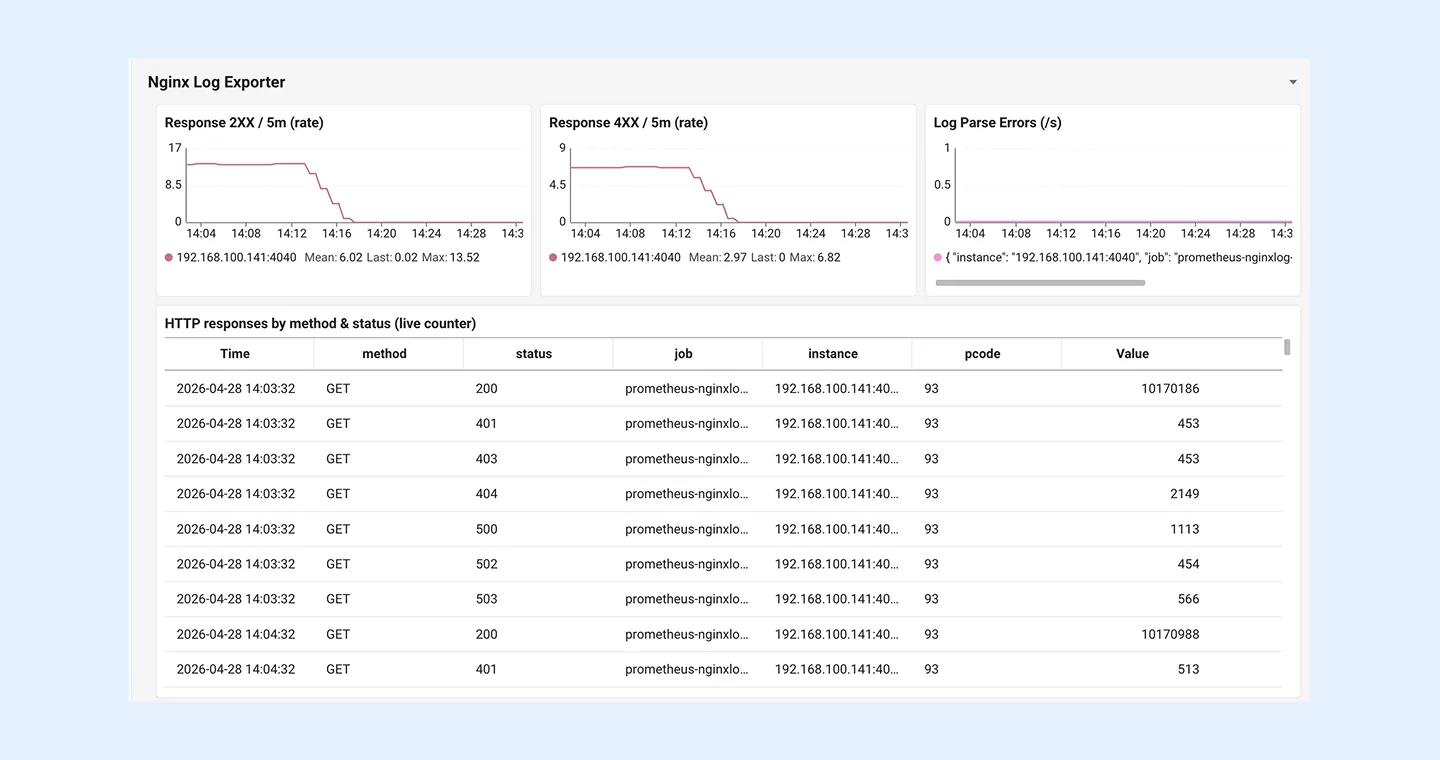
Nginx Log Exporter: HTTP 트랜잭션 분석
두 번째 영역은 액세스 로그를 파싱한 결과를 시각화합니다.
- Response 2XX / 5m (rate): 5분 윈도우 기준 정상 응답 비율
- Response 4XX / 5m (rate): 5분 윈도우 기준 클라이언트 에러 비율
- Log Parse Errors (/s): 로그 포맷 불일치로 인한 파싱 실패 건수
특히 주목할 패널은 하단의 HTTP responses by method & status (live counter) 테이블입니다. 이 테이블은 시간, 메서드, 상태코드, 인스턴스 단위로 응답 수를 세분화해 실시간으로 보여줍니다.
위 캡처에서는 단일 인스턴스에서 GET 메서드의 200, 401, 403, 404, 500, 502, 503 응답이 시간대별로 추적되고 있음을 확인할 수 있습니다.
이 테이블의 의미는 분명합니다. 별도의 ELK나 Loki 환경 없이도 “몇 시 몇 분에 어떤 메서드의 어떤 상태코드가 몇 번 발생했는지”를 즉시 확인할 수 있다는 뜻입니다.
와탭 OpenMetrics Nginx 템플릿을 써야 하는 5가지 이유
화면 설명만으로도 템플릿의 가치는 어느 정도 전달되었을 것입니다. 그렇다면 직접 구축 대신 와탭 템플릿을 선택해야 하는 구체적인 이유를 정리해보겠습니다.
1. 즉시 사용: 0일 만에 시작
직접 구축할 경우 공개 대시보드를 가져오더라도 자사 환경 맞춤 작업에 적지 않은 시간이 듭니다. 반면 와탭 템플릿은 엔드포인트 등록 즉시 동작합니다. PromQL 쿼리 작성, 패널 배치, 알람 룰 설계에 투입되는 시간이 크게 줄어듭니다.
운영팀이 모니터링 도구를 만드는 데 시간을 쓰는 대신, 본업인 서비스 안정성 확보에 집중할 수 있다는 의미입니다. 특히 신규 서비스 런칭 시점처럼 시간이 빠듯한 상황에서 큰 차이를 만듭니다.
2. 검증된 베스트 프랙티스: 패널 설계 고민 종료
Nginx 모니터링 대시보드를 직접 만들어본 분이라면, “어떤 메트릭을, 어떤 단위로, 어떻게 시각화할 것인가”를 결정하는 것 자체가 큰 고민이라는 사실을 잘 알고 계실 겁니다.
- p95를 볼 것인가, p99를 볼 것인가, 평균도 함께 보여줄 것인가?
- Accepted와 Handled를 어떻게 함께 비교할 것인가?
- 4XX와 5XX를 분리해서 볼 것인가, 합쳐서 볼 것인가?
와탭 템플릿은 이런 질문들에 대한 검증된 답을 이미 적용한 상태로 제공됩니다. 다양한 운영 환경에서 축적된 노하우가 패널 구성에 반영되어 있어, 운영자는 “보는 법”이 아니라 “해석하는 법”에 집중할 수 있습니다.
3. 두 Exporter 통합 시각화: 커넥션과 트랜잭션을 한 화면에서
직접 구축할 때 가장 까다로운 부분 중 하나는 nginx-prometheus-exporter와 prometheus-nginxlog-exporter의 데이터를 한 화면에서 의미 있게 결합하는 작업입니다.
와탭 템플릿은 이를 기본으로 제공합니다. Overview에서 RPS와 p95를 확인하고, Nginx Exporter에서 커넥션 흐름을 추적한 뒤, Nginx Log Exporter에서 트랜잭션 결과를 검증하는 3단 추적 흐름이 한 페이지에서 자연스럽게 이어집니다.
장애 발생 시 운영자의 시선 동선은 다음과 같이 흐릅니다.
14:14 RPS 급락 감지
→ Active Connections 확인: Nginx 자체는 살아 있는가?
→ 4XX/5XX 카운터 확인: 업스트림 문제인가?
→ HTTP responses 테이블에서 영향 범위 산정
이 모든 과정이 도구 전환 없이 한 화면 안에서 이루어집니다.
4. 운영 부담 0: TSDB 관리 불필요
직접 구축의 또 다른 숨은 비용은 Prometheus 자체의 운영입니다. TSDB 디스크 관리, 장기 보관을 위한 Thanos·Cortex 도입, 카디널리티 폭증 대응까지 모두 운영팀의 부담으로 돌아옵니다.
와탭은 SaaS 형태로 제공되므로 이러한 인프라 운영 부담을 줄일 수 있습니다. OpenAgent를 설치하고 엔드포인트를 등록하면 메트릭 수집과 시각화 환경을 빠르게 구성할 수 있습니다.
글로벌 SaaS 환경에서 대규모 메트릭을 안정적으로 수집해온 인프라 위에서 동작하므로, 운영팀은 메트릭 폭증이나 보관 정책 관리에 대한 부담을 덜고 서비스 운영에 집중할 수 있습니다.
5. PromQL 자산 보존: 직접 구축 경험이 그대로 살아남음
이미 Prometheus 기반으로 모니터링을 운영해온 팀이라면 이 부분이 특히 중요합니다. 와탭 OpenMetrics Explorer는 PromQL을 그대로 지원합니다.
sum by (status) (rate(nginx_http_response_count_total[5m]))기존에 작성해둔 쿼리, 알람 룰의 expression, 팀 위키에 정리해둔 PromQL 스니펫을 그대로 재사용할 수 있습니다.
또한 Kubernetes 환경에서 운영 중인 팀이라면, OpenAgent는 Prometheus Operator의 표준 CRD인 PodMonitor·ServiceMonitor를 인식하며, Operator를 사용하지 않는 환경을 위한 정적 엔드포인트 등록 방식도 함께 지원합니다. 따라서 기존 설정의 마이그레이션 비용도 최소화할 수 있습니다.
기존 자산은 유지하면서 운영 부담만 줄이는 것. 이것이 와탭 OpenMetrics가 제공하는 가장 합리적인 전환 경로입니다.
직접 구축 vs 와탭 OpenMetrics 템플릿
지금까지의 내용을 표로 정리하면 다음과 같습니다.
직접 구축이 가지는 유연성은 분명한 장점입니다. 하지만 모니터링은 수단이지 그 자체가 목적은 아닙니다. 운영 인력의 시간을 모니터링 도구 유지보수가 아니라 서비스 안정성 확보에 쓸 수 있도록 하는 것. 이것이 통합 관찰 플랫폼의 본질적인 역할입니다.
결론: Nginx부터 시작하는 통합 관찰성
Nginx는 거의 모든 웹 서비스의 출발점입니다. 따라서 Nginx의 가시성이 확보되면, 그 뒤에 이어지는 애플리케이션·DB·인프라 전체의 모니터링 전략도 함께 정리할 수 있습니다.
와탭 OpenMetrics Nginx 템플릿은 이 첫걸음을 가장 빠르게 시작하는 방법입니다. 직접 구축과 운영에 들였을 시간을 줄이고, 운영팀이 실제 문제 해결에 더 집중할 수 있도록 돕습니다.
함께 보면 좋은 자료




.png)





