.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
OpenMetrics로 Kafka Consumer Lag 모니터링하기

Kafka는 현대 데이터 인프라의 거의 모든 곳에 자리하고 있습니다. 마이크로서비스 간 비동기 통신, 이벤트 스트리밍, CDC 파이프라인, 로그 수집까지 데이터가 흐르는 곳이라면 Kafka가 활용되는 경우가 많습니다.
그리고 Kafka를 운영하다 보면 거의 항상 마주치는 익숙한 알람이 있습니다.
새벽 3시. “Consumer Lag이 증가하고 있습니다.”
Kafka 운영자에게 가장 익숙하면서도 가장 부담스러운 알람입니다. Lag이 증가하고 있다는 것은 프로듀서가 메시지를 쌓는 속도를 컨슈머가 따라잡지 못하고 있다는 의미입니다. 이 추세가 멈추지 않으면 데이터 처리 지연이 비즈니스 영향으로 직결될 수 있습니다.
문제는 이 알람을 받았을 때 즉시 답해야 하는 질문들입니다.
- 어떤 컨슈머 그룹에서 lag이 발생하고 있는가?
- 어떤 토픽에서 발생하고 있는가?
- 일시적인 트래픽 스파이크인가, 추세적으로 증가하고 있는가?
- 컨슈머가 중단된 것인가, 단순히 느려진 것인가?
- 메시지 발행 속도가 평소보다 급증한 것인가?
이 질문들에 답하려면 컨슈머 그룹, 토픽, 파티션 등 여러 기준의 메트릭을 동시에 확인해야 합니다. 그러나 Kafka는 모니터링 진입 장벽이 높은 미들웨어 중 하나로 알려져 있습니다.
이 글에서는 Kafka 모니터링이 왜 까다로운지, 그리고 와탭의 OpenMetrics Kafka 템플릿이 이 복잡성을 어떻게 한 화면에 정리하는지 살펴보겠습니다.
Kafka 모니터링이 까다로운 이유
1. JMX는 모니터링에 적합한 인터페이스가 아닙니다
Kafka의 메트릭은 기본적으로 JMX(Java Management Extensions)를 통해 노출됩니다. 문제는 JMX가 현대적인 모니터링 워크플로를 염두에 두고 설계된 인터페이스가 아니라는 점입니다.
Prometheus로 Kafka 메트릭을 수집하려면 일반적으로 다음과 같은 설정 과정이 필요합니다.
rules:
- pattern:"kafka.consumer<type=(.+), client-id=(.+)><>(.+)"
name: kafka_$1_$3
labels:
client_id: $2JMX MBean 이름을 정규식으로 매칭해 메트릭 이름과 라벨을 추출하는 방식입니다. 정확한 메트릭을 수집하려면 패턴 작성이 까다롭고, 누락된 메트릭이 없는지 일일이 검증해야 합니다.
게다가 Kafka 운영에 필요한 메트릭은 하나의 Exporter로 끝나지 않습니다.
- JMX Exporter: 브로커 자체의 JVM, request rate, controller 상태 등을 Kafka 브로커의 JMX MBean에서 추출
- Kafka Exporter(danielqsj/kafka_exporter): Consumer Lag, 파티션 정보, ISR 상태 등을 Kafka 프로토콜로 직접 수집
즉 운영팀은 두 종류의 Exporter를 동시에 배포하고 유지해야 하며, 각각의 패턴 매칭 규칙과 카디널리티 특성까지 관리해야 합니다. “Lag 메트릭이 수집되지 않는다”는 질문이 반복되는 이유도, 어떤 Exporter가 어떤 메트릭을 노출하는지에 대한 경계가 운영자에게 떠넘겨져 있기 때문입니다.
2. Consumer Lag은 중요하지만 관리가 까다롭습니다
Kafka 운영자라면 대부분 동의하는 사실이 있습니다. Consumer Lag은 Kafka 운영에서 가장 중요한 단일 지표라는 점입니다.
하지만 Lag은 다루기 까다로운 데이터 구조를 가지고 있습니다. Lag은 컨슈머 그룹 × 토픽 × 파티션 단위로 추적되기 때문에, 클러스터 규모가 커질수록 추적해야 할 시그널이 수천 개 이상으로 늘어납니다.
.png)
이 데이터를 그대로 알람에 연결하면 잦은 오탐으로 인한 알람 피로(alert fatigue)가 발생합니다. “lag이 1000을 초과하면 알람”과 같은 단순 임계치는 정상적인 트래픽 스파이크에서도 false positive를 만들고, 운영자는 곧 알람을 무시하기 시작합니다.
실제로 필요한 것은 컨슈머 그룹 단위로 집계된 lag 추세와 토픽 단위로 집계된 lag 분포를 구분해 보는 능력입니다. 하지만 이 시각화를 직접 만들려면 PromQL 쿼리 작성, 패널 설계, 알람 룰 튜닝에 상당한 시간이 필요합니다.
3. 클러스터 상태를 판단하는 기준이 명확하지 않습니다
“Kafka 클러스터가 정상인가?”라는 질문에 답하기는 의외로 어렵습니다. 다음과 같은 다양한 신호를 종합해야 하기 때문입니다.
- 모든 브로커가 살아 있는가?
- Under-replicated partition은 없는가?
- ISR(In-Sync Replicas) 수가 정상인가?
- 컨트롤러가 정상적으로 동작하고 있는가?
Kafka는 한두 개의 브로커가 중단되더라도 일정 수준까지는 정상 동작할 수 있습니다. 따라서 “전체가 다운되지 않았다”는 사실만으로 안심해서는 안 됩니다. 파티션 단위로 상태를 확인해야 합니다. 이 상태를 한눈에 보여주는 패널을 직접 설계하는 것 역시 간단한 작업이 아닙니다.
4. 직접 구축은 카디널리티 폭증과의 싸움입니다
Kafka 환경에서 Prometheus + JMX Exporter + Grafana 조합으로 직접 모니터링을 구축할 때 가장 흔한 문제는 메트릭 카디널리티입니다.
Kafka 브로커 한 대가 노출하는 메트릭은 100~200개에 달합니다. 여기에 토픽, 파티션, 컨슈머 그룹 라벨이 곱해지면 시계열 수가 수백만 개로 폭증할 수 있습니다. 결과적으로 Prometheus TSDB가 빠르게 포화되고, 쿼리 성능도 급격히 떨어집니다.
이를 관리하려면 메트릭 relabeling으로 verbose한 시그널을 drop하고, 토픽 단위 집계로 변환하고, 스크랩 주기를 1~2분으로 늘리는 등의 튜닝 작업이 필요합니다. 운영팀이 본업 대신 모니터링 인프라 튜닝에 시간을 쏟게 되는 흔한 시나리오입니다.
와탭 OpenMetrics Kafka 템플릿: 운영에 필요한 지표를 한 화면에 정리
와탭 OpenMetrics Kafka 템플릿은 위의 복잡성을 4개 영역으로 정리한 단일 대시보드로 풀어냅니다. Exporter 엔드포인트만 등록하면 즉시 사용할 수 있습니다.
1. Overview: 가장 먼저 확인해야 할 5개 지표

대시보드 최상단에는 운영자가 가장 먼저 확인해야 할 5개 카드 메트릭이 한 줄에 배치됩니다.
여기서 주목할 점은 Total Lag이 카드 메트릭으로 가장 오른쪽에 배치되어 있다는 점입니다. 이는 단순한 UI 결정이 아니라, Kafka 운영의 핵심 지표가 무엇인지에 대한 명확한 관점을 반영한 설계입니다. 운영자가 대시보드를 열었을 때 가장 먼저 눈이 가는 위치에 가장 중요한 숫자가 배치되어 있습니다.
2. Message Throughput: 메시지 발행 속도와 소비 속도 비교

Total Lag이 증가하는 원인은 결국 두 가지 중 하나입니다. 프로듀서가 더 많이 쓰고 있거나, 컨슈머가 덜 읽고 있거나.
이 둘을 분리해 보여주는 영역이 Message Throughput입니다.
- Production Rate(msg/s): 초당 발행되는 메시지 수
- Consumption Rate(msg/s): 초당 소비되는 메시지 수
두 그래프를 나란히 비교하면 lag 증가의 원인을 빠르게 파악할 수 있습니다. Production Rate만 급증했다면 트래픽 스파이크가 원인일 가능성이 높고, Consumption Rate만 떨어졌다면 컨슈머 측 문제일 가능성이 높습니다. 별도의 PromQL 작성 없이 시각적 비교만으로 1차 진단이 가능한 구조입니다.
3. Consumer Lag: 컨슈머 그룹과 토픽 기준으로 나눠 보기

Consumer Lag을 다루기 어렵게 만드는 핵심 이유는 다차원성입니다. 와탭 템플릿은 이를 두 개의 분리된 차트로 정리합니다.
Lag By Consumer Group
컨슈머 그룹 단위로 집계된 lag을 시계열로 표시합니다. 이를 통해 “어떤 애플리케이션이 처리를 따라가지 못하고 있는가”를 즉시 식별할 수 있습니다. 알람 설정의 1차 단위로도 가장 적합합니다.
Lag By Topic
토픽 단위로 집계된 lag을 보여줍니다. 이를 통해 “어떤 데이터 스트림이 적체되고 있는가”를 비즈니스 관점에서 파악할 수 있습니다. 예를 들어 결제 토픽의 lag은 사용자 영향이 즉각적이지만, 로그 토픽의 lag은 상대적으로 우선순위가 낮을 수 있습니다. 이런 판단에 활용할 수 있습니다.
Members By Group: Lag 증가 원인을 마지막으로 확인하는 지표
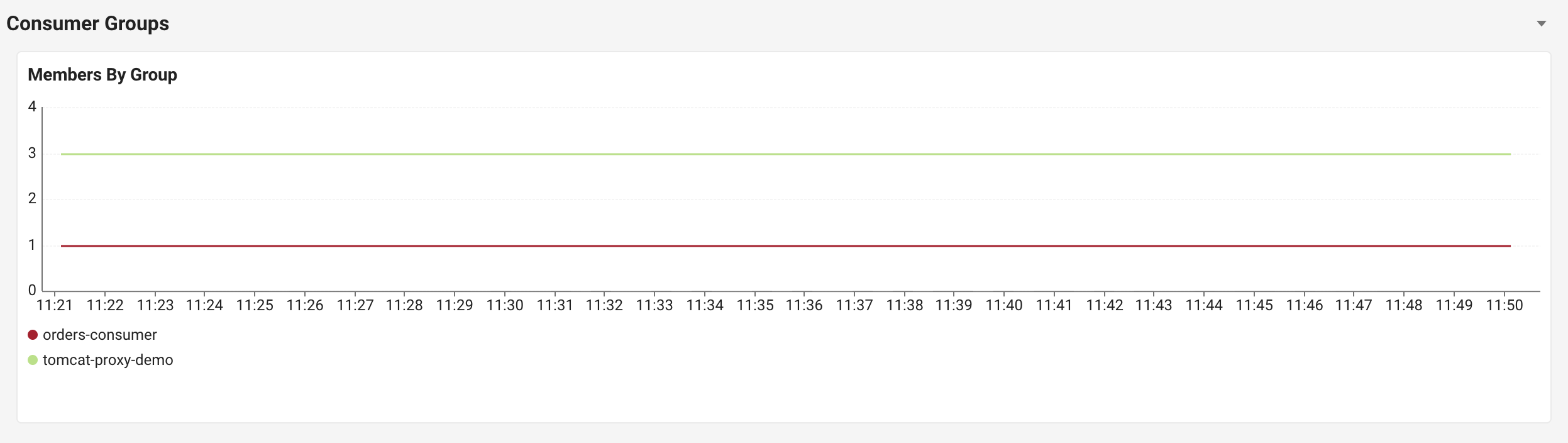
같은 영역 하단에는 컨슈머 그룹별 활성 멤버 수가 시계열로 표시됩니다. 멤버 수가 갑자기 줄었다면 컨슈머 인스턴스 다운, 0이라면 그룹 전체 장애를 의심할 수 있습니다. Lag 증가의 직접적인 원인을 검증할 수 있는 마지막 퍼즐 조각입니다.
Lag By Consumer Group에서 “누가 막혔는지”를 식별하고, 바로 옆 Members By Group에서 “그 그룹이 왜 막혔는지, 즉 인스턴스 수가 줄어든 것인지”를 검증하는 동선이 한 화면 안에서 완결됩니다.
4. Cluster Health: 파티션 단위로 클러스터 상태 확인
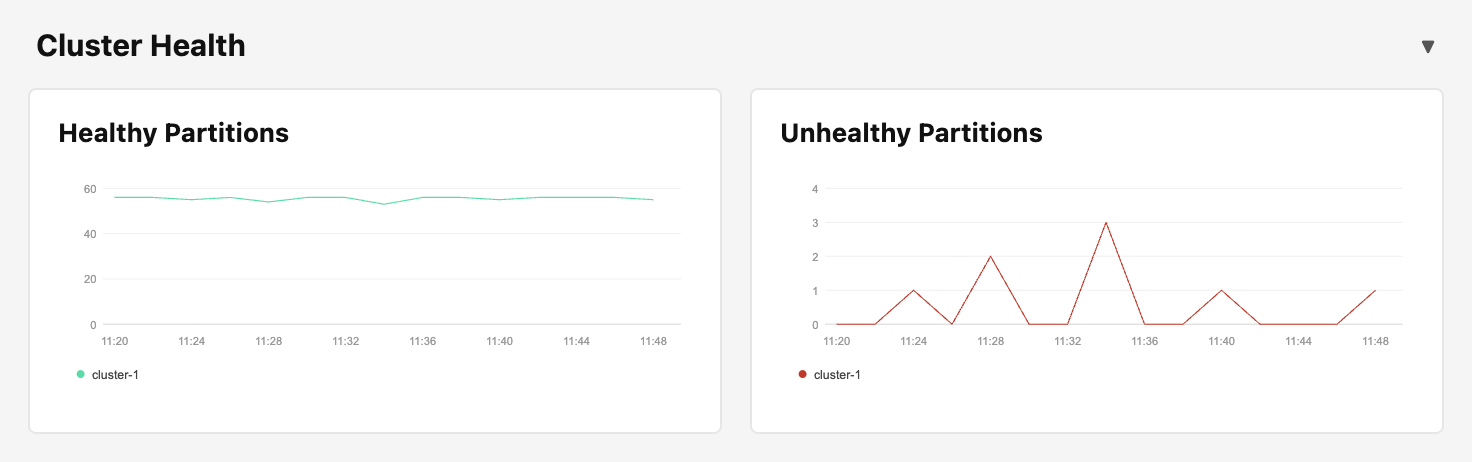
“클러스터가 정상인가?”라는 모호한 질문을 와탭 템플릿은 파티션 단위의 이진 분류로 단순화합니다.
- Healthy Partitions: 정상 동작 중인 파티션 수
- Unhealthy Partitions: Under-replicated 또는 ISR 불일치 등으로 비정상 상태인 파티션 수
이 분류는 운영자가 즉시 액션을 결정할 수 있게 해줍니다. Unhealthy Partitions가 0이면 안심할 수 있고, 0이 아니라면 어떤 파티션에 문제가 있는지 상세 진단으로 들어가면 됩니다. 직관적이고 명확한 트리거 구조입니다.
실전 시나리오: 새벽 3시 “Consumer Lag” 알람을 5분 안에 진단하기
위 4개 영역이 한 화면에 통합되면, 새벽 3시 알람의 진단 동선은 다음과 같이 흘러갑니다.
T+0초: 알람 수신
“Total Lag exceeds threshold.”
T+30초: Overview 카드 확인
대시보드를 열자마자 Total Lag 카드가 빨간색 임계치를 표시합니다. 동시에 Consumer Groups, Brokers 카드 숫자가 평소와 같은지 확인합니다. 브로커 수가 정상이라면 인프라 다운 가능성은 낮습니다.
T+1분: Message Throughput 비교
Production Rate와 Consumption Rate 그래프를 나란히 확인합니다. Production Rate는 평소 수준인데 Consumption Rate가 급락해 있다면, 컨슈머 측 문제라는 가설을 세울 수 있습니다.
T+1분 30초: Lag By Consumer Group으로 원인 그룹 식별
Lag By Consumer Group 차트에서 lag이 급격히 증가하고 있는 그룹이 하나로 좁혀집니다. 예를 들어 order-processor 그룹입니다.
T+2분: Members By Group으로 가설 검증
같은 그룹의 멤버 수 시계열을 확인합니다. 평소보다 낮아져 있다면 컨슈머 인스턴스 일부가 중단되었다는 결론을 내릴 수 있습니다. 멤버 수가 평소와 같다면 인스턴스는 살아 있지만 처리 속도만 느려진 상황이므로, 별도 가설로 분기해야 합니다.
T+3분: Cluster Health 점검
Healthy/Unhealthy Partitions 차트로 브로커 측 문제가 아닌지 한 번 더 검증합니다. 모두 healthy 상태라면 컨슈머 측 조치에 집중할 수 있습니다.
T+5분: 조치 결정
컨슈머 인스턴스 재시작 또는 스케일 아웃 여부를 결정합니다.
직접 구축한 환경이라면 JMX Exporter 메트릭이 정상 수집되는지부터 의심하고, Grafana 대시보드를 여러 개 열어 시간축을 맞추고, kafka-consumer-groups.sh를 별도로 실행해 검증해야 했을 가능성이 높습니다. 5분 안에 결론에 도달하기 어려운 작업입니다.
와탭 OpenMetrics Kafka 템플릿을 써야 하는 5가지 이유
1. 핵심 지표 우선 배치: Total Lag이 카드 메트릭에 있습니다
Kafka 모니터링의 본질은 Lag을 잡는 것입니다. 와탭 템플릿은 이 사실을 UI 설계에 그대로 반영합니다. Total Lag이 가장 위, 가장 눈에 띄는 위치에 카드 메트릭으로 배치되어 있습니다.
이는 단순한 패널 배치의 문제가 아니라, 운영자가 문제를 확인하는 순서에 맞춰 대시보드를 구성한 것입니다. 직접 구축한 대시보드에서 “Total Lag을 어디에 둘 것인가”를 고민하지 않아도 됩니다.
2. Consumer Lag을 그룹과 토픽 기준으로 나눠 볼 수 있습니다
Lag을 그룹별로 보면 “누가 막혀 있는가”를 알 수 있고, 토픽별로 보면 “어떤 데이터가 막혀 있는가”를 알 수 있습니다. 이 두 관점을 모두 제공하는 것이 Lag 진단의 핵심입니다. 와탭 템플릿은 이를 두 개의 나란한 차트로 깔끔하게 정리합니다.
복잡한 PromQL sum by 쿼리를 직접 작성하지 않아도, 다차원 lag 데이터가 의미 있는 두 차원으로 자동 집계됩니다.
3. Production과 Consumption 비교로 원인을 빠르게 구분할 수 있습니다
Lag이 증가하는 원인이 “쓰는 쪽”인지 “읽는 쪽”인지 구분하는 것이 1차 진단의 핵심입니다. 와탭 템플릿은 두 Rate를 별도 차트로 나란히 배치해 시각적 비교만으로 원인을 좁힐 수 있게 합니다.
단순해 보이는 설계지만, 실제 새벽 알람 상황에서는 큰 차이를 만듭니다. PromQL을 작성하지 않아도 두 그래프의 형태만 비교하면 됩니다.
4. JMX 패턴 매칭의 부담을 줄일 수 있습니다
직접 구축할 때 가장 큰 진입 장벽은 JMX MBean 정규식 매칭입니다. 어떤 메트릭이 어떤 패턴으로 노출되는지, 어떤 라벨이 누락되지 않는지 일일이 검증해야 합니다.
와탭은 OpenAgent를 통해 표준 Kafka Exporter(kafka_exporter, JMX Exporter 등)의 메트릭을 자동으로 수집하고 정규화합니다. 운영자가 정규식과 씨름할 필요가 없습니다.
5. 메트릭 폭증에 따른 부담도 SaaS 환경에서 줄일 수 있습니다
Kafka 환경에서 가장 자주 마주치는 운영 부담은 메트릭 카디널리티 폭증입니다. 이 문제 역시 와탭의 글로벌 SaaS 인프라가 처리합니다. 수십만 개 메트릭의 안정적 수집이 검증된 환경에서 토픽, 파티션, 컨슈머 그룹 라벨이 늘어나도 운영팀이 별도로 튜닝할 부담이 줄어듭니다.
또한 OpenAgent의 metricRelabelConfigs를 통해 verbose한 메트릭을 수집 단계에서 필터링할 수도 있어, 비용과 가시성의 균형을 직접 조정할 수 있습니다.
직접 구축 vs 와탭 OpenMetrics Kafka 템플릿
결론: Kafka 모니터링은 단순해야 합니다
Kafka는 강력한 도구입니다. 하지만 그 강력함만큼이나 모니터링이 복잡해지기 쉬운 시스템이기도 합니다. JMX의 진입 장벽, Consumer Lag의 다차원성, 카디널리티 폭증까지. 이 모든 문제를 운영팀이 직접 해결하는 동안 정작 중요한 본업이 뒤로 밀리는 경우가 많습니다.
와탭 OpenMetrics Kafka 템플릿은 Kafka 운영자가 반드시 알아야 하는 4가지 영역, 즉 개요, 처리량, Consumer Lag, 클러스터 상태를 한 화면에 정리해 제공합니다. 복잡함은 도구가 흡수하고, 운영자는 판단과 조치에 집중할 수 있는 구조입니다.
새벽 3시 lag 알람이 발생했을 때, 5분 안에 원인을 짚고 조치 방향을 결정할 수 있는 환경. 그것이 좋은 Kafka 모니터링 도구의 조건입니다.
함께 보면 좋은 자료











