.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
응답시간 지표 비교, 평균·TPS·p95·p99 중 뭘 봐야 하나

평균 180ms, p99 3,200ms. 같은 서비스의 같은 시간에 측정한 응답시간인데 17배가 넘게 차이가 납니다. 그리고 둘 다 맞는 숫자입니다.
응답시간을 말하는 지표는 평균, TPS, p50, p95, p99까지 여럿이고, 각자 다른 질문에 답합니다. 평균으로는 "전체가 어떤가"를, p95로는 "느린 소수가 얼마나 느린가"를, TPS로는 "얼마나 많이 처리하나"를 봅니다. 어떤 숫자를 믿고 판단하느냐에 따라 같은 상황이 정상으로도, 장애로도 보입니다. 역할이 다른 지표를 구분하지 않으면, 멀쩡해 보이는 그래프 뒤에서 고객이 이탈합니다.
이 글은 응답시간을 말하는 지표들을 한 표로 비교하고, 상황별로 어떤 지표를 봐야 하는지 선택 기준을 정리합니다. 결론부터 말하면, 하나만 봐서는 부족하고, 평균은 가장 먼저 의심해야 합니다.
응답시간 지표 5가지
각 지표가 무엇을 말하고 어디서 약한지를 먼저 한 표로 봅니다. 뒤에 나오는 선택 가이드에서 "내 경우엔 무엇을 봐야 하나"를 짚을 때 다시 펼쳐 보면 됩니다.
여기서 가장 자주 헷갈리는 게 평균과 p50입니다. 둘 다 "보통값" 같지만 다릅니다. p50은 순위로 정한 한가운데 값이라 느린 소수에 흔들리지 않고, 평균은 극단값 쪽으로 끌려갑니다. 그래서 "보통 사용자가 느끼는 속도"를 알고 싶다면 평균이 아니라 p50을 봐야 합니다.
평균을 가장 먼저 의심하라
응답시간은 오른쪽 꼬리가 긴 분포입니다. 빠른 요청이 다수고, 느린 요청이 소수지만 아주 느립니다. 이 모양에서는 평균이 실제 체감과 가장 멀어집니다.
평균은 정상인데 고객은 느리다고 말하는 상황이 여기서 나옵니다. 결제 완료 버튼을 누른 일부 사용자는 3초 넘게 기다리지만, 평균만 보면 이상이 보이지 않습니다.
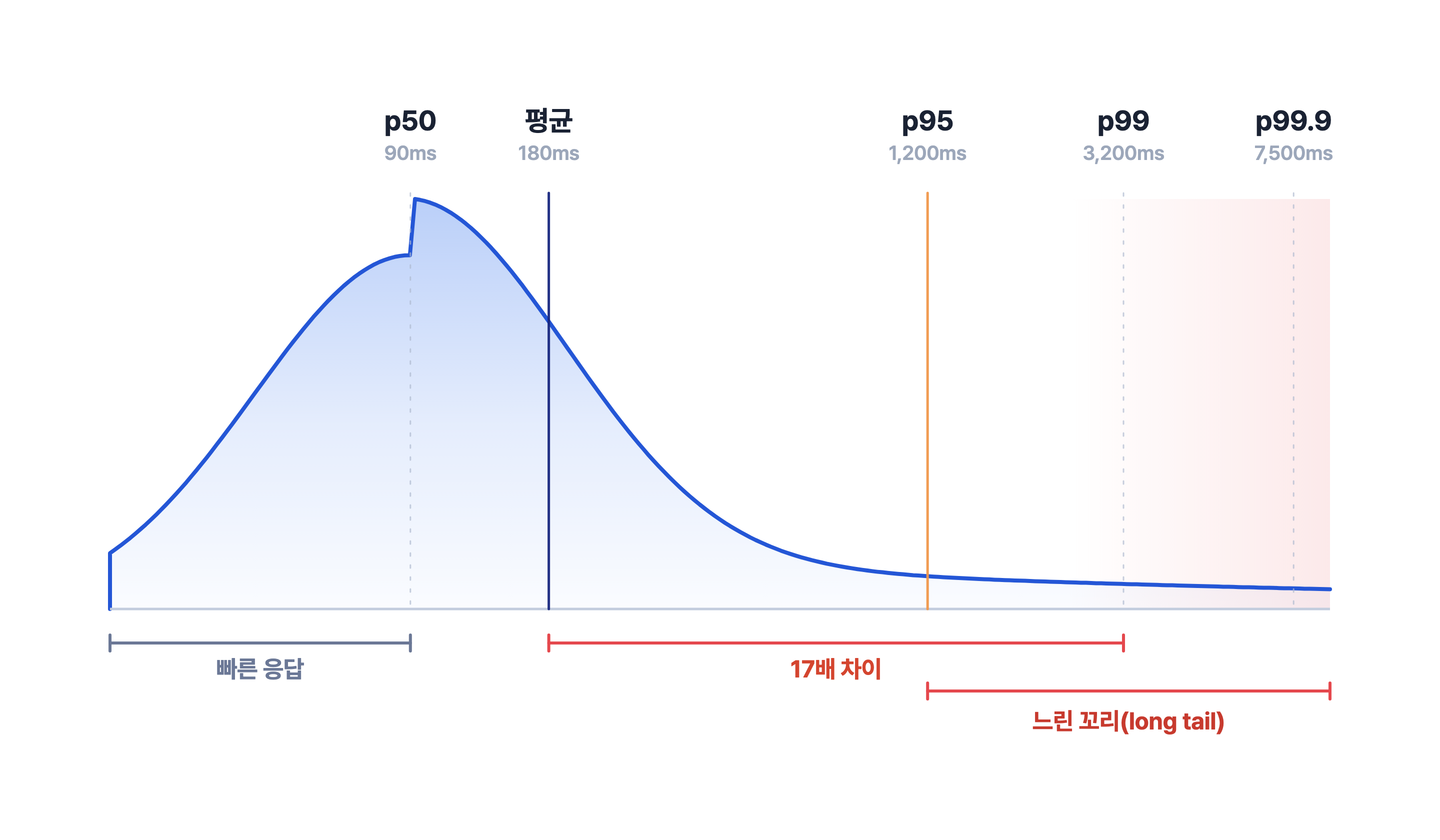
같은 데이터인데 p50은 90ms, 평균은 그 두 배인 180ms입니다. 아주 느린 요청 몇 건 때문입니다. 평균은 모든 값을 더해 나누다 보니 극단값 몇 개에 끌려 커지지만, p50은 줄을 세웠을 때 한가운데 값이라 느린 소수가 아무리 느려도 흔들리지 않습니다. 평균 180ms를 "보통 속도"로 읽으면 실제 다수가 겪는 90ms와 어긋나고, 동시에 1% 사용자가 3초 넘게 기다리는 사실은 평균 어디에도 드러나지 않습니다. 결제 API의 1%라면 주간 수천 건의 이탈이 발생할 수 있습니다.
그래서 서비스 품질 목표(SLO)는 평균이 아니라 p95·p99로 정의하는 것이 표준입니다. "평균 200ms"가 아니라 "요청의 95%를 500ms 안에 응답한다"가 실무 권장 형태입니다.
상황별 선택 가이드
지표는 "다 보는 것"이 아니라 "지금 답하려는 질문에 맞는 것"을 봅니다. 자주 마주치는 다섯 가지 질문으로 정리했습니다.
- "보통 사용자는 얼마나 빠른가" -> 평균이 아니라 p50. 다수의 체감 속도를 왜곡 없이 보여 줍니다.
- "서비스 품질 목표를 지키고 있나" -> p95. SLO·알림의 기준선으로 가장 널리 쓰입니다. 느린 소수까지 포함한 약속이기 때문입니다.
- "최악의 경험은 얼마나 나쁜가" -> p99·p99.9. 결제·로그인처럼 한 번만 오래 걸려도 사용자가 떠날 수 있는 기능에서 봅니다. 단, 스파이크에 민감해 노이즈가 큽니다.
- "용량이 충분한가, 언제 늘려야 하나" -> TPS(+포화점). 응답시간이 아니라 처리량을 묻는 질문이라, 응답시간 지표만으로는 답이 안 나옵니다.
- "전체가 느린가, 일부만 느린가" -> 평균과 p95의 간격. 둘이 가까우면 전반적 저하, p95만 크게 벌어지면 특정 구간의 국소 이슈입니다.
핵심은 단독으로 보지 않는다는 점입니다. 특히 "전체가 느린지 일부가 느린지"는 한 지표로 알 수 없고, 평균과 p95를 나란히 둘 때 비로소 보입니다.
한 지표로는 부족한 대표 사례. TPS와 p95 조합
가장 좋은 예가 처리량(TPS)과 지연(p95)을 같이 보는 경우입니다. TPS와 p95가 오르내리는 조합에 따라 상황도, 해야 할 조치도 달라집니다.
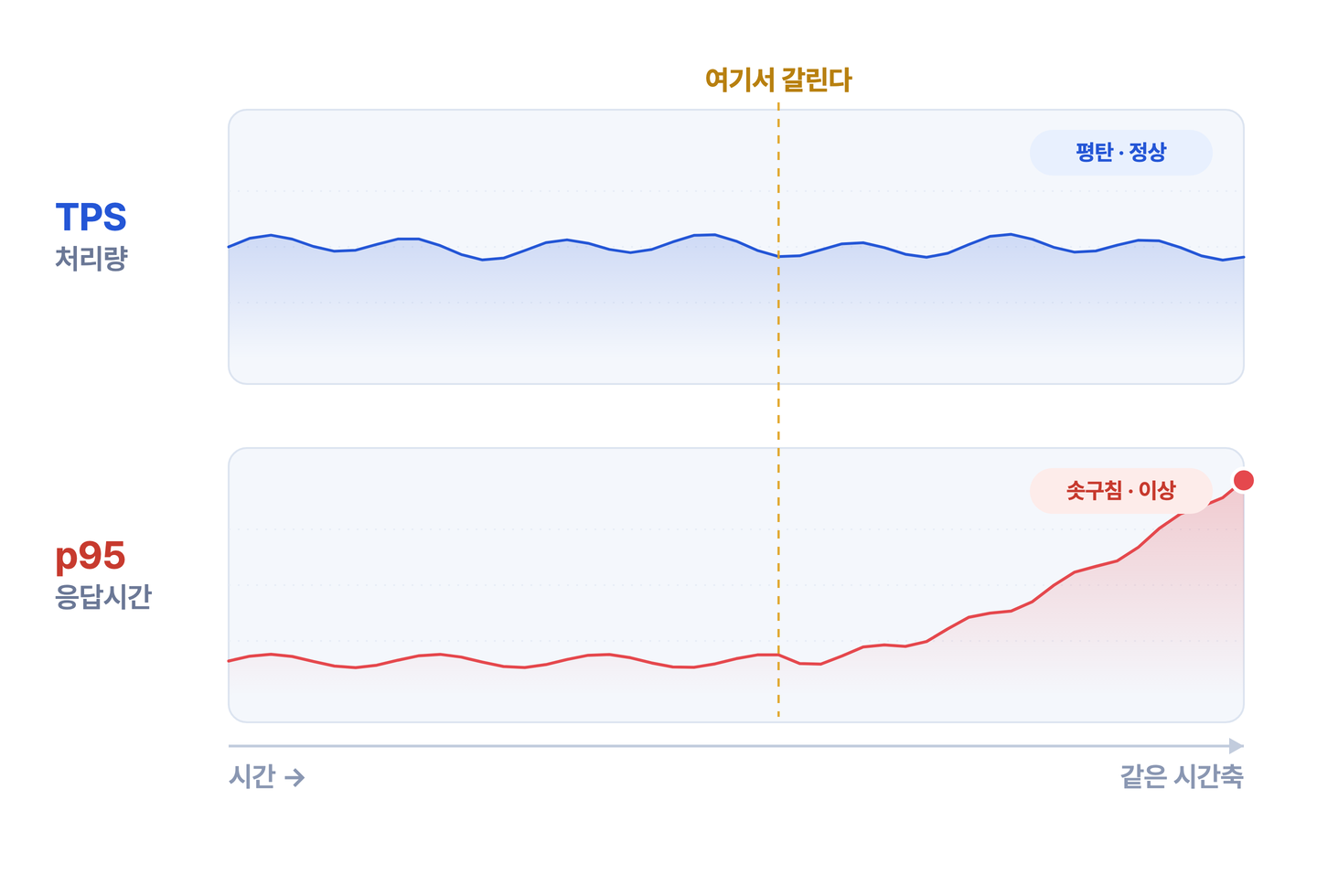
가장 헷갈리는 조합이 TPS 안정 + p95 상승입니다. "TPS도 정상이고 CPU도 여유 있는데 왜 고객은 느리다고 하지"라는 상황이 여기 해당합니다. 특정 고객사·API·외부 연동 구간만 느려지면서 p95가 먼저 반응하는데, TPS만 보는 팀은 며칠씩 놓치기도 합니다.
가장 위험한 건 TPS 하락 + p95 상승입니다. TPS만 보면 "트래픽이 줄었네"로 읽히지만, 실제로는 요청이 처리되지 못하고 대기열에 쌓이는 적체일 수 있습니다. "사용자가 줄었다"고 생각한 구간이 사실은 장애 시작점인 경우가 적지 않습니다.
이 지표들은 어디서 볼 수 있나
봐야 할 지표를 정했다면, 다음은 어디서 보느냐입니다. 공통 전제는 하나, 요청별 처리 시간이 기록돼 있어야 한다는 점입니다. 요청 수를 집계하면 TPS가, 응답시간 분포를 집계하면 백분위가 나옵니다. 어디서 시작하느냐에 따라 방법은 세 가지입니다.
- 이미 쌓이는 로그: 웹서버·로드밸런서 액세스 로그에 요청별 응답시간이 남는 경우가 많습니다(Nginx
$request_time, 클라우드 LB의 응답시간 필드). 집계하면 TPS와 p95·p99를 바로 계산할 수 있어, 가장 빨리 시작하는 길입니다. - 애플리케이션 메트릭: Prometheus 같은 시스템에 요청 시간을 히스토그램으로 수집하면 TPS와 백분위를 대시보드에서 함께 봅니다. 계측을 추가해야 하지만 API별로 원하는 지표를 직접 정의할 수 있습니다.
- APM·분산 트레이싱: TPS와 백분위가 자동으로 계산되고, p95가 올랐을 때 어떤 요청이 느렸는지, 그 안에서 어떤 SQL·외부 호출이 시간을 썼는지까지 따라 들어갈 수 있습니다.
한 가지 주의할 점이 있습니다. 백분위는 평균처럼 더해서 나누면 안 됩니다. 인스턴스별 p95를 다시 평균 내거나 시간대별 p95를 평균 내면 실제 값과 달라집니다. 그래서 p95는 이미 구해 둔 값을 다시 합치지 않고, 원본 응답시간을 모아 한 번에 계산해야 합니다. 그러니 p95 값을 비교할 때는 이렇게 원본에서 바로 구한 값인지 확인하는 것이 좋습니다.
정리하면 질문에 맞는 지표를 선택한다
응답시간 지표는 우열이 아니라 역할이 다릅니다. 평균은 거의 단독으로 보지 않고, 보통 체감은 p50으로, 품질 약속은 p95로, 최악 경험은 p99로, 용량은 TPS로 봅니다. 그리고 어떤 질문도 한 지표만으로는 답이 안 나옵니다. "전체가 느린가 일부가 느린가"는 평균과 p95의 간격으로, "처리량은 괜찮은데 왜 느려지나"는 TPS와 p95의 조합으로 비로소 보입니다.
처음부터 다 외울 필요는 없습니다. 다음에 "느리다"는 말을 들으면, 먼저 평균을 의심하고, 지금 답하려는 질문이 무엇인지부터 정하면 됩니다. 그게 곧 봐야 할 지표입니다.
WhaTap APM은 응답시간을 통계 데이터뿐 아니라 응답시간 분포(트랜잭션 맵 히트맵)로도 보여 줍니다. 히트맵은 p95 이상 느린 구간이 어느 응답시간 대역에 몰려 있는지 시각적으로 드러냅니다. 애플리케이션 대시보드에서는 이 히트맵과 TPS 추이가 한 화면에 함께 보여, "TPS가 떨어지는 시점에 p95가 어느 대역으로 올라가는지"를 한눈에 파악할 수 있습니다. 그 느린 구간은 그대로 트랜잭션 트레이스(SQL·외부 호출)까지 드릴다운됩니다. 5분 만에 무료로 시작해 보세요 → WhaTap APM 무료 체험
더 읽을거리








