.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
슬로우 쿼리 원인 분석과 튜닝

배포가 끝나고 서비스를 확인하는데 API 응답 시간이 처음엔 3초, 그다음엔 5초로 늘어납니다. 요청이 쌓이면서 결국 타임아웃으로 끊어집니다. 이럴 때 가장 먼저 의심할 것 중 하나가 DB 슬로우 쿼리입니다.
APM도 DB 모니터링도 없이 데이터베이스를 운영하는 상황이 있습니다. 작은 서비스, 사내 도구, 초기 스타트업, 막 인수받은 레거시 시스템에서 흔히 볼 수 있습니다.
그래도 괜찮습니다. 대부분의 관계형 데이터베이스는 느린 쿼리 기록, 실행 통계, 현재 세션 조회 기능을 기본으로 제공합니다.
이 글에서는 데이터베이스의 기본 기능을 이용해 슬로우 쿼리를 찾고 원인을 분석한 뒤 튜닝하는 방법을 살펴보겠습니다.
슬로우 쿼리 분석은 보통 다음 순서로 진행됩니다.
- 어떤 SQL이 느린지 찾는다.
- 실행 계획(EXPLAIN)으로 원인을 확인한다.
- 인덱스와 쿼리를 수정한다.
이 글도 이 순서대로 살펴보겠습니다.
느린 쿼리를 찾는 세 가지 방법
느린 쿼리는 로그만으로도 찾을 수 있습니다. 다만 쉽지는 않습니다. 로그는 평소에 꺼져 있는 경우가 많고, 켜져 있어도 실행 내용을 한 줄씩 나열할 뿐이라 수천 줄을 집계해서 봐야 실제로 부하를 만드는 SQL을 찾을 수 있습니다. 또 임계치보다 빠르지만 매우 자주 실행되는 쿼리나, 지금 이 순간 실행 중인 쿼리는 로그에 나타나지 않습니다.
그래서 느린 쿼리를 찾는 방법을 세 가지로 나눕니다. 이미 실행이 끝난 쿼리는 로그와 통계 뷰에서 확인하고, 현재 실행 중인 쿼리는 세션 뷰에서 확인합니다. 이 세 가지 정보만으로도 대부분의 슬로우 쿼리는 찾을 수 있습니다.
① 엔진 슬로우 쿼리 로그 (이미 실행이 끝난 쿼리)
가장 직관적인 방법입니다. 임계 시간을 넘긴 쿼리를 데이터베이스가 로그에 기록합니다.
MySQL·MariaDB는 slow_query_log를 켜고 long_query_time으로 기준 시간을 정합니다.
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1;
SET GLOBAL log_queries_not_using_indexes = 'ON';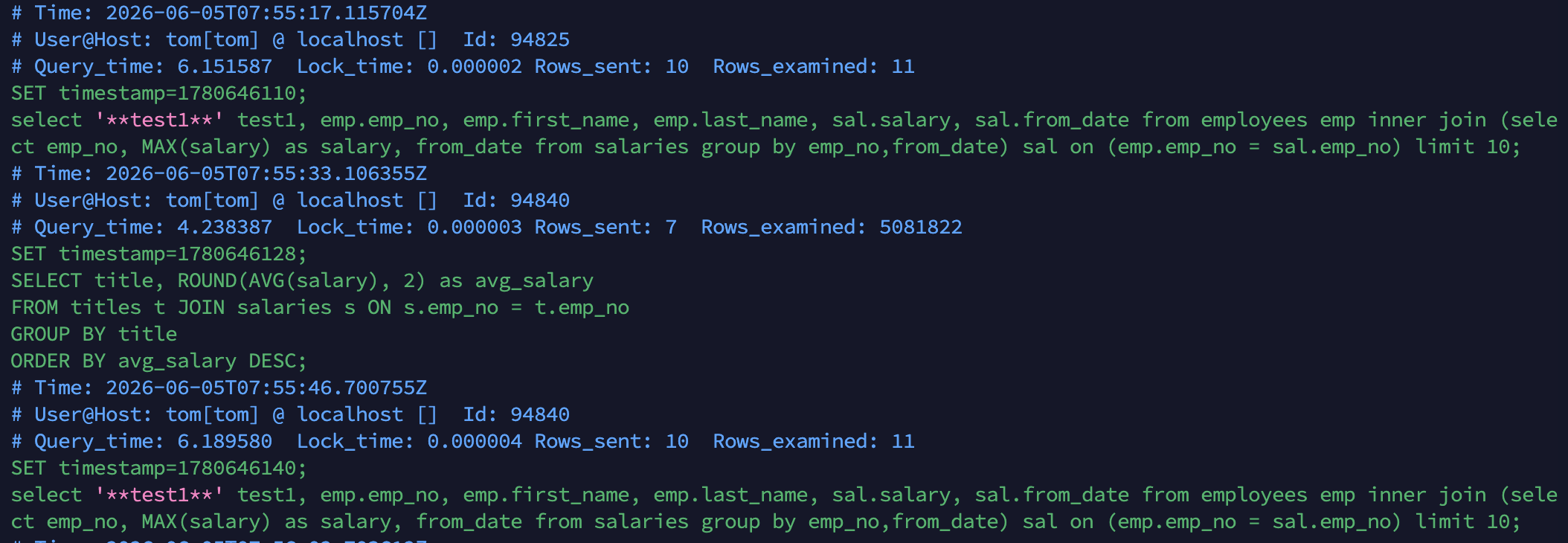
PostgreSQL은 log_min_duration_statement로 기준 시간을 설정합니다.
SET log_min_duration_statement = 1000;SQL Server는 Query Store를 통해 실행 이력을 저장할 수 있고, Oracle은 AWR·ASH 또는 Statspack을 통해 부하가 높은 SQL을 확인할 수 있습니다.
슬로우 로그의 장점은 "어떤 SQL이 얼마나 오래 걸렸는지"를 정확히 남긴다는 점입니다. 장애가 지나간 뒤에도 당시 실행된 SQL을 확인할 수 있어 원인 분석의 출발점이 됩니다.
다만 로그만으로는 한계가 있습니다. 임계치보다 빠르지만 매우 자주 실행되는 쿼리는 기록되지 않고, 현재 실행 중인 쿼리도 아직 로그에 남지 않습니다. 이런 경우에는 다음 두 가지 방법이 필요합니다.
② 누적 통계 뷰 (총 수행 시간 기준)
로그가 개별 실행 기록을 보여준다면, 통계 뷰는 같은 형태의 SQL을 묶어 누적 결과를 보여줍니다. PostgreSQL에서는 pg_stat_statements가 대표적입니다.
SELECT query, calls, total_exec_time, mean_exec_time
FROM pg_stat_statements
ORDER BY total_exec_time DESC
LIMIT 10;MySQL은 Performance Schema의 events_statements_summary_by_digest, Oracle은 V$SQL, SQL Server는 sys.dm_exec_query_stats를 활용합니다.
여기서 중요한 것은 정렬 기준입니다. 단건 실행 시간이 아니라 총 수행 시간(누적 실행 시간) 으로 정렬해야 합니다.
5초 걸리는 쿼리가 하루 한 번 실행되면 누적 시간은 5초입니다. 반면 0.5초 걸리는 쿼리가 하루 만 번 실행되면 누적 시간은 5,000초가 됩니다. 실제로 데이터베이스 자원을 더 많이 사용하는 쪽은 후자입니다.
③ 지금 실행 중인 세션
장애가 현재 진행 중이라면 세션 뷰가 가장 빠른 단서가 됩니다.
SELECT pid,
now() - query_start AS duration,
state,
query
FROM pg_stat_activity
WHERE state = 'active'
ORDER BY duration DESC;MySQL은 SHOW FULL PROCESSLIST, Oracle은 V$SESSION, SQL Server는 sys.dm_exec_requests를 사용합니다.
현재 실행 중인 SQL과 대기 상태를 확인할 수 있으며, 오래 실행되는 작업도 바로 찾을 수 있습니다.
실행 계획으로 원인을 확인한다
느린 쿼리를 찾았으면 왜 느린지를 봅니다. 대부분의 데이터베이스가 실행 계획을 제공합니다. MySQL과 PostgreSQL은 EXPLAIN, 실제 실행 시간까지 보려면 PostgreSQL의 EXPLAIN ANALYZE를 씁니다. Oracle은 EXPLAIN PLAN과 DBMS_XPLAN, SQL Server는 실제 실행 계획을 켜고 쿼리를 돌립니다.
예를 들어 다음 쿼리가 느리다고 가정해 보겠습니다.
SELECT *
FROM orders
WHERE customer_id = 12345;실행 계획을 확인합니다.
EXPLAIN
SELECT *
FROM orders
WHERE customer_id = 12345;MySQL에서는 다음과 비슷한 결과가 나올 수 있습니다.
table: orders
type: ALL
rows: 2500000여기서 type=ALL은 인덱스를 사용하지 않고 테이블 전체를 읽고 있다는 의미입니다. 조회 결과는 몇 건뿐인데 수백만 건을 읽고 있다면, 인덱스가 없는지 또는 인덱스를 사용하지 못하고 있는지 먼저 확인합니다.
처음부터 실행 계획 전체를 이해할 필요는 없습니다. 풀 테이블 스캔 하나만 잡아도 많은 문제를 찾을 수 있습니다.
개발 환경에서는 멀쩡하던 쿼리가 운영에서만 느린 경우도 많습니다. 운영은 데이터가 훨씬 많아 풀스캔 비용이 커지고, 옵티마이저가 참고하는 통계가 오래됐거나, WHERE DATE(created_at) = ...처럼 칼럼을 함수로 감싸 인덱스를 우회하는 것이 흔한 원인입니다. 운영 데이터로 실행 계획을 다시 뜨고, 통계가 오래됐으면 갱신(ANALYZE, Oracle은 DBMS_STATS)부터 해 봅니다.
문제 해결은 인덱스와 쿼리부터 확인
원인을 찾았다면 가장 단순한 방법부터 적용합니다.
1단계. 인덱스
WHERE, JOIN, ORDER BY에 자주 사용되는 칼럼을 중심으로 인덱스를 검토합니다.
앞에서 살펴본 예시 쿼리에 인덱스를 추가해 보겠습니다.
인덱스 생성
CREATE INDEX idx_customer_id
ON orders(customer_id);인덱스를 추가한 뒤 다시 실행 계획을 확인합니다.
type = ref
rows = 3앞에서는 인덱스를 사용하지 않아 약 250만 건을 읽었지만, 인덱스 추가 후에는 3건만 읽는 것을 확인할 수 있습니다. 같은 결과를 얻기 위해 읽어야 하는 데이터 양이 크게 줄어든 것입니다.
실행 계획에서 사용되지 않는 인덱스는 저장 공간을 차지하고 쓰기 작업의 비용만 증가시킬 수 있습니다. 따라서 인덱스를 추가한 뒤에는 실제로 사용되는지 실행 계획으로 다시 확인하는 것이 중요합니다.
2단계. 쿼리
인덱스만으로 해결되지 않으면 쿼리 자체를 수정합니다.
- 반복 실행되는 서브쿼리를 조인으로 변경
SELECT *대신 필요한 칼럼만 조회
3단계. 아키텍처
인덱스와 쿼리 개선으로도 해결되지 않는다면 구조적인 대응을 검토합니다.
- 읽기 전용 레플리카 추가
- 애플리케이션 캐시 도입
- 집계 결과 사전 계산
다만 이 단계는 운영 복잡도를 높이므로, 앞 단계에서 해결 가능한지 먼저 확인하는 것이 좋습니다.
다시 느려지지 않게, 슬로우 로그와 임계치 관리
한 번 문제를 해결했다고 끝은 아닙니다. 슬로우 쿼리 로그를 항상 활성화해 두면 다음 문제가 발생했을 때 바로 원인을 추적할 수 있습니다.
운영 환경에서는 slow_query_log 또는 log_min_duration_statement를 지속적으로 활성화해 두는 경우가 많습니다.
임계치는 운영 환경에 맞게 조정합니다.
- 단건 1초 경고, 3초 위험을 시작값으로 사용
- 같은 SQL이 10분 안에 5회 이상 임계치를 넘으면 집중 확인
- 처음에는 다소 높게 시작하고 점진적으로 조정
또한 슬로우 쿼리를 수정할 때마다 원인과 조치 내용을 간단히 기록해 두면, 같은 문제가 다시 발생했을 때 훨씬 빠르게 대응할 수 있습니다.
마치며
모니터링 도구가 없어도 데이터베이스 기본 기능만으로 슬로우 쿼리를 찾고 분석할 수 있습니다. 로그·통계 뷰·세션 뷰로 문제를 찾고, 실행 계획으로 원인을 확인한 뒤, 인덱스부터 차례대로 개선하는 것이 핵심입니다.
다만 시스템 규모가 커질수록 이 과정은 점점 번거로워집니다. 수천 줄의 로그를 직접 분석하고 여러 서버를 비교해야 하기 때문입니다. 모니터링 도구를 사용하면 특정 시간대의 슬로우 쿼리를 빠르게 추려 보고, 여러 데이터베이스의 상태를 한 화면에서 확인할 수 있습니다.
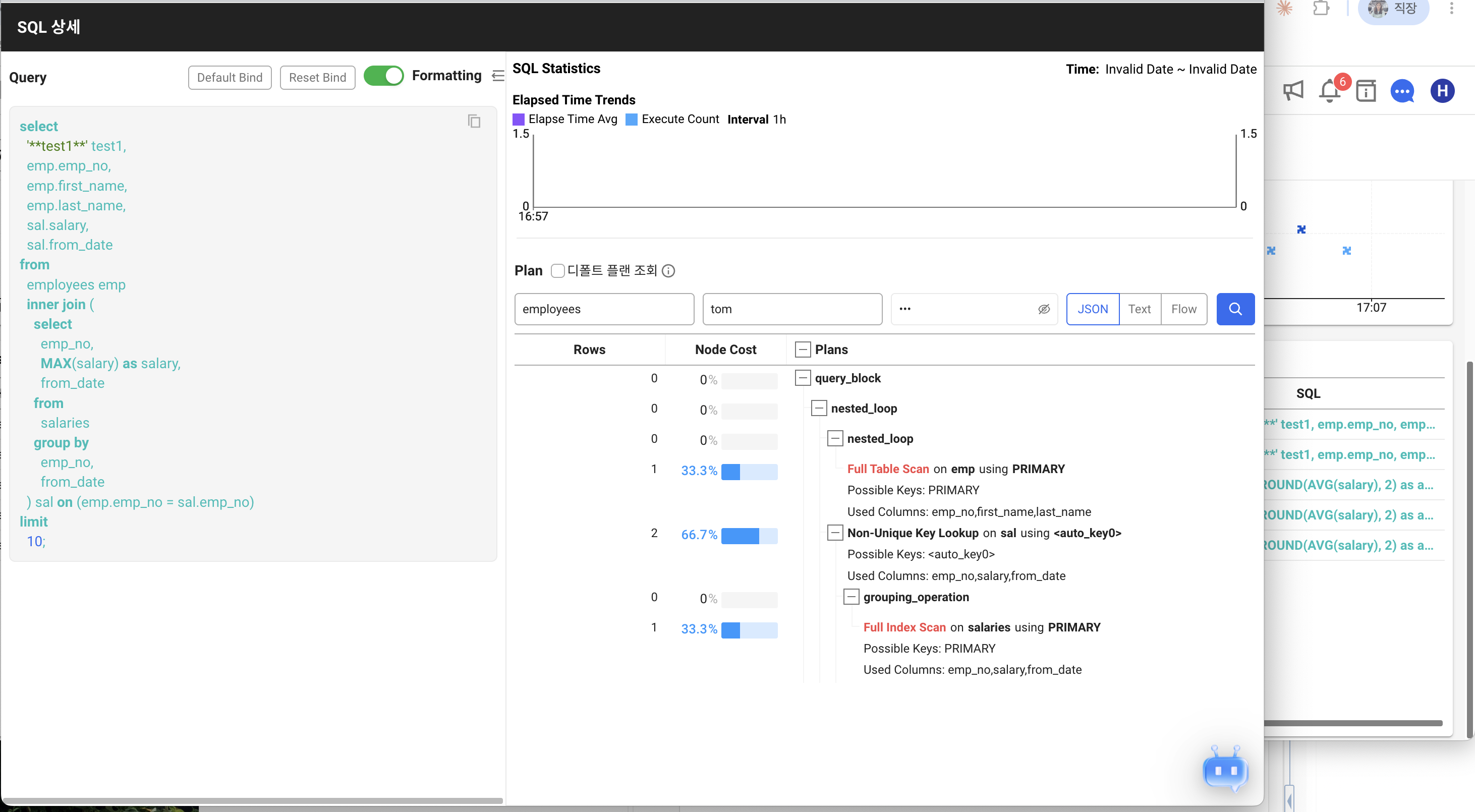
별도 모니터링 도구 없이 분석하기가 번거롭다면, 와탭 데이터베이스 모니터링을 15일 무료로 써 보는 것도 방법입니다. 실행 계획 해석과 인덱스 제안을 자연어로 정리해 주는 AI 분석도 함께 제공합니다.
%20(1).png)
더 읽을거리
- MySQL 모니터링 시작하기 (와탭 공식 문서)
- PostgreSQL 모니터링 시작하기 (와탭 공식 문서)
- Use The Index, Luke (인덱스와 SQL 성능을 다루는 무료 온라인 교재)