.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
LLM 옵저버빌리티(관찰 가능성)란? LLM 모니터링이 필요한 이유

GPT, Claude, Gemini 등 LLM API 하나만으로 고객 상담부터 문서 요약, 코드 리뷰까지 자동화할 수 있는 시대입니다. 하지만 막상 프로덕션 환경에 적용하고 나면 전혀 다른 종류의 불안이 시작됩니다.
“이 답변이 정말 맞는 건가?”
“이번 달 토큰 비용이 왜 이렇게 많이 나온 거지?”
“어제까지 잘 동작하던 게 왜 갑자기 이상한 답변을 하지?”
기존 모니터링 도구만으로는 이런 질문에 답하기 어렵습니다. 만약 이러한 불안이 익숙하다면, 이 글이 해소의 실마리가 될 수 있습니다. LLM 애플리케이션이 1) 기존 소프트웨어와 어떻게 다른지, 2) 무엇을 관측해야 하는지, 3) 왜 풀스택 통합 관측이 필수인지를 차례대로 살펴보겠습니다.
LLM 애플리케이션, 기존 소프트웨어와의 차이점
LLM 애플리케이션은 기존 소프트웨어와 다릅니다. 핵심적인 차이는 세 가지로 요약할 수 있습니다.
LLM은 같은 질문에도 답변이 달라질 수 있고(비결정성), 내부에서 어떤 과정을 통해 답을 만들었는지 추적하기 어려우며(블랙박스), 리소스를 토큰 단위로 소비합니다. 따라서 기존 소프트웨어에서 사용하던 검증 방식이나 코드 레벨 디버깅, CPU·메모리 중심의 리소스 관리 방식을 그대로 적용하기 어렵습니다.
이러한 예측 불가능성을 운영 가능한 수준으로 관리하려면, 결국 새로운 관측 체계가 필요합니다. 바로 LLM 옵저버빌리티입니다.
LLM 옵저버빌리티란
LLM 옵저버빌리티(관찰 가능성)은, LLM을 활용하는 애플리케이션의 요청 흐름과 성능, 비용, 품질을 추적·분석하는 것을 의미합니다. 핵심은 모델 자체를 관측하는 것이 아니라, 모델을 사용하는 전체 과정을 관측하는 데 있습니다.

흥미롭게도 LLM 옵저버빌리티는 기존 APM(Application Performance Monitoring)과 기술적으로 동일한 구조를 가집니다. 전통적인 APM이 하나의 HTTP 요청을 Trace로 묶고, 그 안에서 DB 쿼리나 외부 API 호출을 Step으로 기록하듯이, LLM 옵저버빌리티도 하나의 사용자 요청을 Trace로 묶고 벡터 검색, LLM API 호출, Tool 실행을 Step으로 기록합니다. Trace–Metrics–Logs라는 기본 구조 역시 동일합니다.
차이는 Step 안에 기록되는 속성(Attribute)에 있습니다. 기존 APM이 커버하지 못하는 LLM 고유의 영역이 존재하기 때문입니다.
- 응답 품질: HTTP 200을 반환하면서 완전히 틀린 답을 할 수 있습니다. 환각(Hallucination)은 상태 코드로 잡히지 않습니다.
- 토큰과 비용: 프롬프트 길이, 모델 선택, 캐싱 여부에 따라 요청당 비용이 극적으로 달라집니다.
- 프롬프트와 컨텍스트: LLM 동작을 결정하는 것은 코드가 아니라 프롬프트입니다.
- LLM 고유의 보안: 프롬프트 인젝션, PII 유출, 시스템 프롬프트 노출은 SQL Injection이나 XSS와 다른 차원의 위협입니다.
- GPU 성능: 기존 애플리케이션에서는 수집하지 않던 GPU 지표가 핵심이 됩니다.
구조는 같지만 관측해야 할 속성이 다르다면, 구체적으로 무엇을 어떻게 관측해야 할까요?
LLM 옵저버빌리티의 5가지 관측 대상
LLM 애플리케이션은 단순한 API 호출이 아니라 여러 컴포넌트가 유기적으로 결합된 시스템이기 때문에 관측 대상도 다층적입니다.

- LLM API 호출: 지연 시간, 토큰 사용량, 비용, 에러율, 모델명, TTFT(Time to First Token) 등을 추적합니다. 가장 기본적인 관측 대상입니다.
- RAG 파이프라인: 인덱싱(청킹 → 임베딩 → 벡터 DB 저장)과 쿼리 처리(질문 → 벡터 검색 → 컨텍스트 조립 → LLM 생성) 단계로 구성됩니다. 검색 지연 시간, 관련도 점수, 컨텍스트 윈도우 사용률 등이 핵심 지표입니다.
- AI Agent 실행: 전체 실행 단계, Tool 호출 순서와 성공·실패 여부, LLM 호출 횟수, 무한 루프 발생 여부, 목표 달성 여부 등을 추적합니다. 실행 경로가 매번 동적으로 결정되기 때문에, 트레이싱 없이는 디버깅이 사실상 어렵습니다.
- MCP 연동: MCP(Model Context Protocol)로 연결된 외부 시스템의 연결 상태, 응답 시간, Tool 호출 성공률 등을 관측합니다.
- 프롬프트: 템플릿 버전, 주입 변수, 시스템 프롬프트 변경이 응답 품질에 미치는 영향을 추적합니다. 프롬프트 버전별 성능 비교 역시 중요합니다.
그렇다면 LLM 옵저버빌리티를 도입하면 실제로 무엇이 달라질까요?
기존 도구만으로는 대응하기 어려웠던 문제들을 어떻게 해결할 수 있을까요? 그 답은 다음 다섯 가지 핵심 가치로 정리할 수 있습니다.
LLM 옵저버빌리티의 핵심 가치
1. 전 과정 추적 - 성능 병목을 찾습니다
“챗봇 응답이 느려요”라는 보고가 들어왔을 때 기존 도구로는 서버 CPU 사용률이나 네트워크 지연 정도만 확인할 수 있습니다. 하지만 LLM 애플리케이션에서의 병목 원인은 벡터 검색일 수도 있고, LLM API 자체일 수도 있으며, Agent의 불필요한 반복 실행일 수도 있습니다.
LLM 옵저버빌리티는 사용자 요청이 들어온 순간부터 응답이 반환되는 순간까지의 전체 과정을 Trace 단위로 기록합니다. 예를 들어, 쿼리 전처리에 35ms, 벡터 검색에 120ms, LLM 호출에 850ms가 소요되었다는 식으로 단계별 시간을 확인할 수 있습니다.
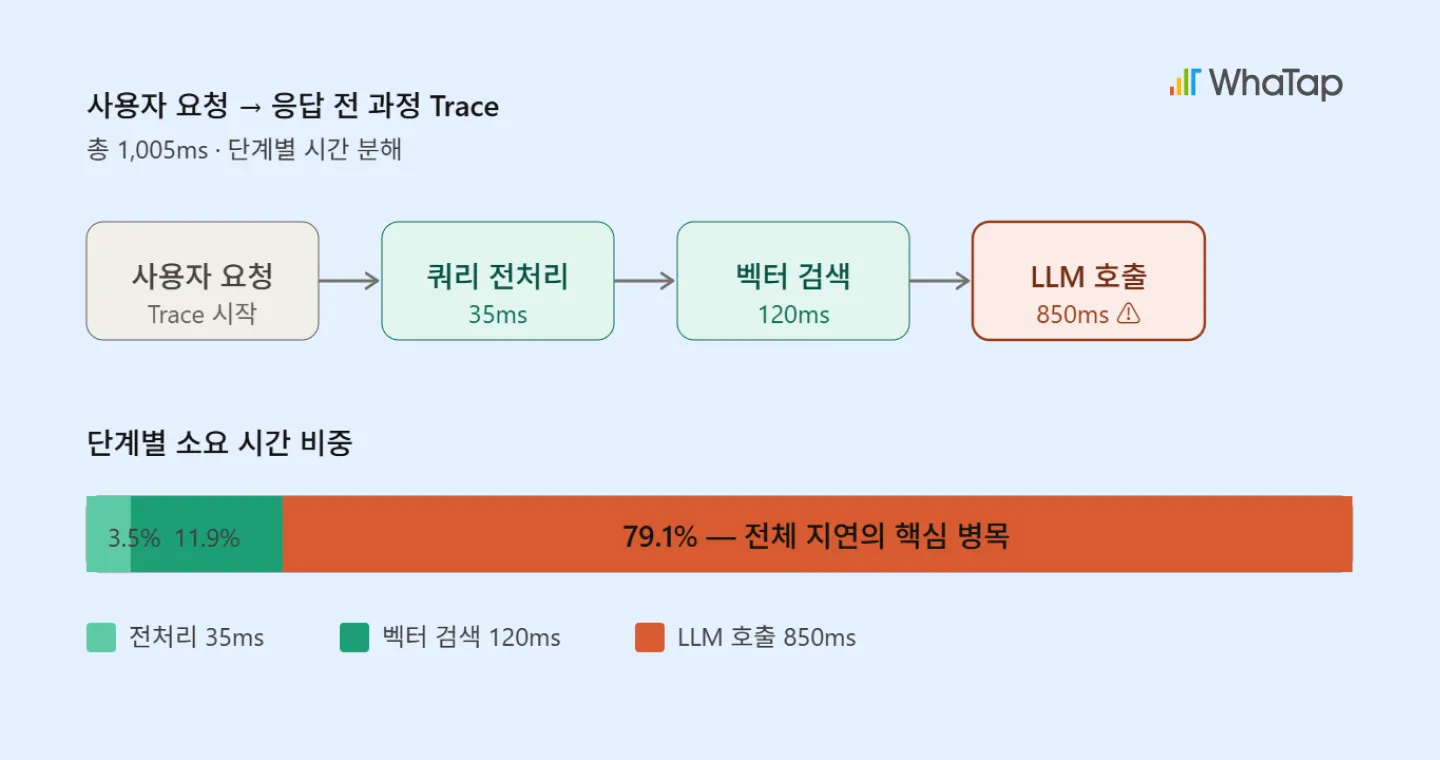
이렇게 되면 “LLM 호출이 전체 지연의 79%를 차지하므로 프롬프트 캐싱을 적용하거나 더 빠른 모델로 교체하자”와 같은 판단이 가능해집니다. TTFT(Time to First Token), 벡터 검색 지연 시간, Agent 반복 횟수 같은 LLM 고유의 성능 지표도 여기에 포함됩니다.
2. 토큰·비용 가시성 - 비용이 어디서 새는지 봅니다
LLM 비용은 예측하기 어렵습니다. 프롬프트를 조금만 변경해도 토큰 사용량이 두 배로 늘어날 수 있고, 특정 사용자의 질문 패턴 때문에 Agent가 동일 작업을 10번 이상 반복 호출하는 경우도 발생합니다. Provider API 환경에서는 이것이 청구 금액으로 나타나고, 로컬 모델 환경에서는 GPU 리소스 소비로 이어집니다.
토큰·비용 모니터링은 모든 LLM 호출의 입력·출력 토큰을 요청 단위, 기능 단위, 모델 단위로 추적하고 집계합니다. 예를 들어 “고객 상담 기능이 전체 비용의 60%를 차지하고 있으며, 그중 절반은 불필요하게 긴 시스템 프롬프트에서 발생한다”는 식의 인사이트를 얻을 수 있어야 실제 최적화가 가능합니다.
3. 답변 품질 평가 - 환각을 고객보다 먼저 발견합니다
LLM의 가장 위험한 실패는 조용하게 발생합니다. 에러 로그도 없고 상태 코드도 200이지만, 답변 내용은 완전히 틀려 있는 경우입니다. 이는 기존 모니터링 체계에는 존재하지 않았던 새로운 관측 영역입니다.
품질 평가는 LLM 응답을 자동으로 채점합니다. 제공된 문서나 컨텍스트를 얼마나 충실하게 반영했는지(Faithfulness), 질문에 적절하게 답했는지(Relevance), 실제 근거에 기반한 답변인지(Groundedness) 같은 지표를 요청 단위 혹은 샘플링 기반으로 평가하면, “오늘 오후부터 Faithfulness 점수가 15% 하락했다”는 신호를 즉시 감지할 수 있습니다.

4. 가드레일 - 나가면 안 되는 것을 막습니다
프롬프트 인젝션으로 시스템 프롬프트가 노출되거나, 사용자가 입력한 개인정보(주민등록번호, 카드번호 등)가 LLM API로 전달되거나, 부적절한 응답이 고객에게 노출되는 상황은 실제 운영 환경에서 충분히 발생할 수 있습니다. 이 영역에서는 에러율이나 재시도율뿐 아니라, 환각 발생률, 프롬프트 인젝션 시도, PII 유출, 유해 콘텐츠 생성 같은 LLM 고유의 보안 위협까지 함께 관측해야 합니다.
가드레일은 LLM 입력과 출력 양쪽에서 동작하는 안전장치입니다. 중요한 점은 가드레일 자체의 동작 상태 역시 관측 대상이라는 것입니다. 필터링된 요청 비율, 위협 유형별 분포, False Positive 비율 등을 지속적으로 추적해야 가드레일의 정확도를 개선할 수 있습니다.
5. 피드백 루프 - 운영 데이터가 개선으로 이어집니다
LLM 애플리케이션은 배포로 끝나지 않습니다. 모델은 지속적으로 업데이트되고, 사용자 질문 패턴은 변화하며, 데이터는 시간이 지나며 낡아갑니다. 한 번 잘 동작했다고 해서 앞으로도 계속 잘 동작한다는 보장은 없습니다.
사용자 피드백(좋아요·싫어요), 품질 평가 점수 변화, 비용 변동 패턴, 에러 발생 빈도 같은 데이터는 프롬프트 개선, 모델 교체, RAG 파이프라인 튜닝의 근거가 됩니다. 예를 들어 “지난주 품질 저하의 원인이 검색 관련도 하락으로 확인되었다 → 리랭킹 모델 추가 → Faithfulness 12% 상승”과 같은 개선 사이클이, 감이 아니라 실제 운영 데이터에 기반해 반복되어야 합니다.
그런데 로컬 LLM을 직접 운영하는 환경이라면 관측해야 하는 범위는 훨씬 더 넓어집니다.
로컬 LLM - 모델 서빙 인프라, GPU 리소스, 버전 관리까지 관측해야 합니다
Provider API(OpenAI, Claude, Gemini 등)를 사용하는 경우에는 모델 서빙을 Provider가 대신 처리해주기 때문에 애플리케이션 레이어 중심으로 관측하면 됩니다. 하지만, 로컬 환경에 모델을 직접 배포하는 경우에는 Provider가 담당하던 영역까지 직접 운영해야 하므로, 관측 범위 역시 크게 확장됩니다.
- 모델 서빙 인프라 - vLLM, TGI(Text Generation Inference) 같은 서빙 엔진의 상태 자체가 곧 LLM 성능에 영향을 미칩니다. 요청 큐 길이, 배치 처리 상태, KV Cache 사용률, 모델 로딩 상태 같은 항목들이 새로운 관측 대상에 포함됩니다.
- GPU 리소스 - VRAM 사용률, GPU 연산 활용률, 전력 소비량, 온도 등은 응답 속도와 동시 처리 성능에 직접적인 영향을 줍니다. 예를 들어 “오후 3시부터 LLM 응답이 느려졌다”는 문제가 발생했다면, VRAM 부족으로 모델이 사용하는 캐시가 충분히 활용되지 못한 것인지, 다른 워크로드가 GPU 리소스를 점유한 것인지까지 함께 확인해야 합니다.
- 모델 버전 관리 - 모델 파일 자체와 양자화(Quantization) 설정, 이전 버전 대비 품질 유지 여부까지 직접 추적해야 합니다. 예를 들어 “INT4 양자화를 적용해 속도는 2배 빨라졌지만 Faithfulness는 8% 하락했다”와 같은 트레이드오프 역시 데이터 기반으로 판단되어야 합니다.

여기까지 살펴보면, 로컬 LLM 환경에서는 관측 대상이 인프라 레벨까지 확장된다는 점을 알 수 있습니다. 하지만 사실 이것은 로컬 환경에만 해당하는 이야기가 아닙니다. Provider API를 사용하는 경우에도, LLM 관측은 결국 풀스택 관점 위에서만 제대로 동작합니다.
LLM 옵저버빌리티, 왜 풀스택 통합이어야 하는가
Provider API를 사용하더라도, LLM 애플리케이션은 단독으로 동작하지 않습니다. API Gateway 뒤에서 트래픽을 처리하고, Kubernetes Pod 위에서 실행되며, 벡터 DB와 일반 DB에 연결되고, MCP를 통해 외부 시스템과 통신합니다. 장애는 이 레이어들을 넘나들며 발생합니다.
LLM만 따로 보면 근본 원인을 찾을 수 없습니다
“고객 상담 챗봇 응답이 5초 이상으로 늘어났다”는 알림이 발생했다고 가정해보겠습니다. LLM 전용 도구만으로는 “LLM 호출이 느리다”는 수준까지만 확인할 수 있습니다.
하지만, 실제 원인은 훨씬 다양할 수 있습니다. 벡터 DB 노드의 디스크 I/O 병목일 수도 있고, Pod 메모리 부족으로 OOM Kill이 반복되고 있는 상황일 수도 있으며, API Gateway의 Rate Limiting 문제일 수도 있습니다.
반대의 경우도 있습니다. 인프라 지표는 모두 정상인데 고객 불만이 증가하는 상황입니다. 품질 평가 지표를 확인해보니 Faithfulness 점수가 어제부터 20% 하락해 있었습니다. 원인은 Provider 측 모델 업데이트였습니다. 이런 문제는 인프라 모니터링만으로는 절대 발견할 수 없습니다.
하나의 Trace로 연결되어야 합니다
사용자의 한 건 요청은 결국 인프라(서버, Kubernetes, GPU) → 애플리케이션(APM) → LLM(RAG, Agent, 품질 평가) 을 모두 관통합니다. 이 전체 흐름이 하나의 Trace로 연결되어야만 “벡터 검색이 느린 원인은 Pod 메모리 부족 때문이다”와 같은 판단이 가능해집니다.

도구가 각각 분리되어 있으면 운영자는 세 개 이상의 대시보드를 번갈아 확인하며 머릿속으로 상관관계를 추론해야 합니다. 결국 장애 대응 시간은 길어질 수밖에 없습니다. 반면 통합 플랫폼에서는 “LLM 호출 지연 → 벡터 DB 쿼리 지연 → Pod CPU Throttling → 노드 리소스 부족”까지 하나의 화면에서 드릴다운 방식으로 확인할 수 있습니다.
이런 흐름은 특정 현장의 실무진만 체감하는 변화가 아닙니다. 업계 전반 역시 같은 방향으로 빠르게 움직이고 있습니다.
빠르게 성장하는 LLM 옵저버빌리티 시장
LLM 옵저버빌리티는 아직 초기 시장이지만, 성장 속도는 매우 빠릅니다.
Gartner는 2026년 3월, 2028년까지 GenAI를 도입한 기업의 50%가 LLM 옵저버빌리티에 투자할 것이라고 전망했습니다. 현재 비율이 약 15% 수준이라는 점을 고려하면 3배 이상 확대되는 수치입니다. Gartner의 Pankaj Prasad는 “기업이 GenAI를 확장할수록 신뢰에 대한 요구는 기술 자체보다 더 빠르게 증가한다”고 설명했습니다.

기존 APM 강자들도 빠르게 움직이고 있습니다. Dynatrace는 2025년 1월 AI Observability를 출시했고, Datadog은 2025년 6월 Agent AI 모니터링과 LLM 실험 기능을 공개했습니다. 또한 Arize AI는 2025년 3월 LLM 옵저버빌리티 전문 기업 Velvet을 인수했습니다.
이러한 성장을 이끄는 핵심 기술 흐름은 크게 두 가지입니다.
1) OpenTelemetry 표준화 - 데이터 수집 방식이 통일되고 있습니다
옵저버빌리티 데이터 수집 방식 역시 빠르게 표준화되고 있습니다. OpenTelemetry(OTel)는 이미 분산 트레이싱의 사실상 표준으로 자리 잡았고, 여기에 LLM 관련 Semantic Convention이 추가되면서 모델명, 토큰 수, 프롬프트, 비용 같은 LLM 속성까지 표준화된 방식으로 기록할 수 있게 되고 있습니다. OTel v1.37부터는 gen_ai.request.model, gen_ai.usage.input_tokens, gen_ai.provider.name 같은 GenAI 전용 속성이 공식 스펙에 포함되었습니다.
이 흐름이 중요한 이유는 벤더 종속성을 줄일 수 있기 때문입니다. 예를 들어 LangSmith는 LangChain 중심 환경에 최적화되어 있고, LlamaTrace는 LlamaIndex 기반 환경과의 연동성이 높습니다. 반면 OpenTelemetry 기반에서는 어떤 프레임워크를 사용하든, 어떤 모니터링 플랫폼을 사용하든 동일한 방식으로 데이터를 수집하고 분석할 수 있습니다. 시장 초기에 표준이 형성되고 있다는 것은, 지금 도입을 시작하더라도 이후 기술 부채로 이어질 가능성이 낮다는 의미이기도 합니다.
2) AI Agent 확산 - 관측 없이는 운영이 불가능한 시대입니다
LLM 옵저버빌리티의 필요성을 가장 강하게 끌어올리는 흐름은 AI Agent의 확산입니다.
초기의 LLM 애플리케이션은 비교적 단순했습니다. 프롬프트를 보내고 응답을 받는 것이 전부였습니다. 사용자 요청 한 건당 LLM 호출 한 번. 관측해야 할 대상도 많지 않았습니다.
하지만 지금은 다릅니다. RAG를 통해 문서를 검색하고, Agent가 적절한 Tool을 선택해 실행하며, 그 결과를 기반으로 다시 판단하고, 필요하면 다른 Agent에게 작업을 위임합니다. MCP로 외부 시스템과 연결되고, 가드레일을 통해 입력과 출력을 검증합니다. 하나의 사용자 요청이 내부적으로 수십 번의 LLM 호출과 Tool 실행으로 이어지는 구조입니다.
이런 시스템에서 문제가 발생하면 — Agent가 잘못된 Tool을 선택했거나, 무한 루프에 빠졌거나, 비용이 급증했거나 — 관측 체계 없이는 원인을 찾기 어렵습니다. Agent의 실행 경로는 매번 동적으로 결정되기 때문에, 로그만으로는 “왜 이런 동작이 발생했는가”를 재구성하기 어렵습니다. 전체 실행 흐름을 Trace 기반으로 기록하고 있어야만 실제 디버깅이 가능합니다.
AI Agent가 확산될수록, LLM 옵저버빌리티는 “있으면 좋은 기능”이 아니라 “없으면 운영이 어려운 필수 요소”로 바뀌고 있습니다.
관측 체계를 도입해야 한다는 점은 이제 분명해졌습니다. 그렇다면 어디서부터, 어떻게 시작하면 좋을까요? 와탭랩스와 함께라면 보다 자연스럽게 시작할 수 있습니다.
LLM 옵저버빌리티의 시작, 와탭랩스
이 글의 핵심 메시지는 하나입니다. LLM 옵저버빌리티는 완전히 새로운 카테고리가 아니라, 기존 옵저버빌리티의 자연스러운 확장이라는 점입니다. 그리고 이 확장은 결국 풀스택 통합 위에서만 제대로 동작합니다.
와탭은 이러한 관점 위에서 LLM 옵저버빌리티를 만들어가고 있습니다.
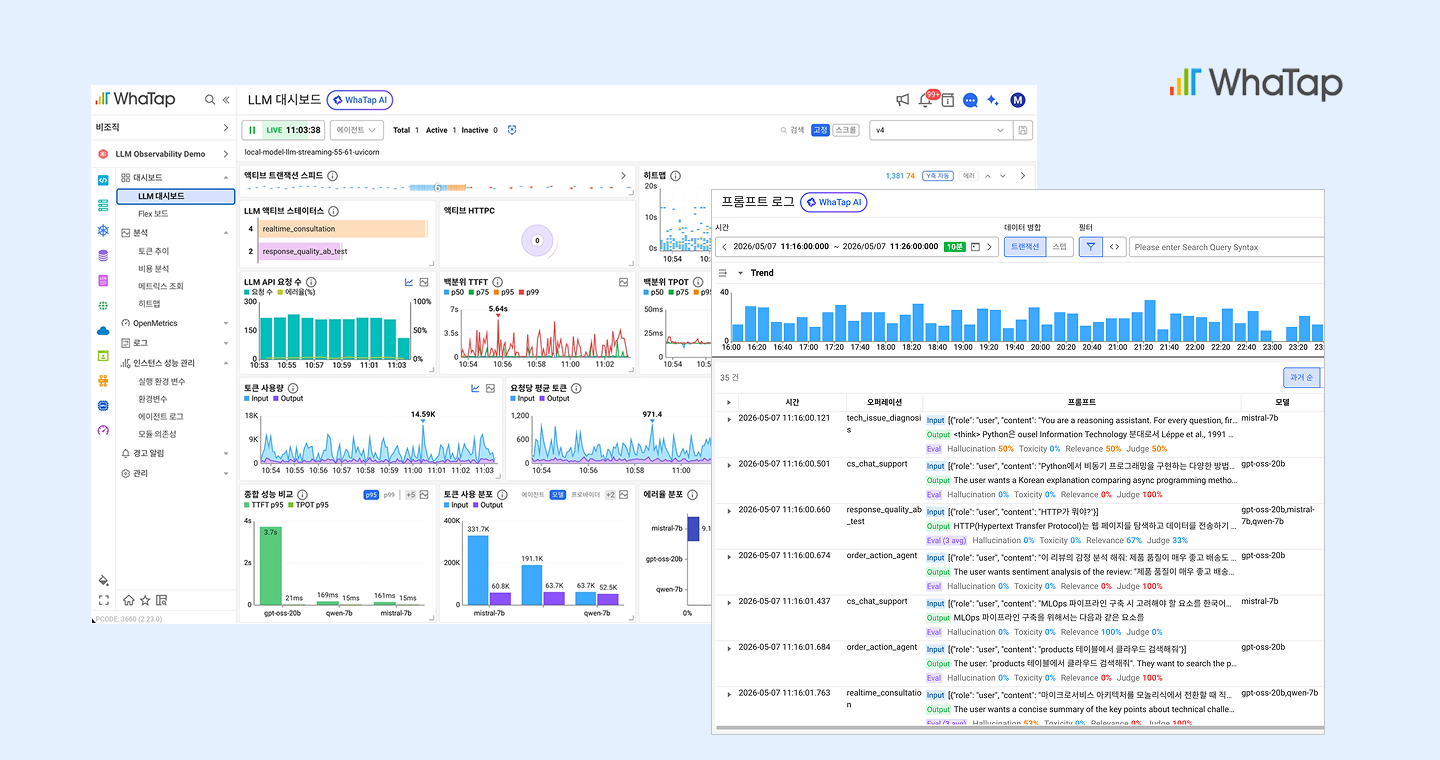
풀스택 위에 LLM을 연결합니다. 와탭은 이미 APM, Kubernetes, 서버, 데이터베이스, GPU까지 하나의 플랫폼에서 통합 모니터링하고 있습니다. LLM 옵저버빌리티는 여기에 자연스럽게 추가되는 레이어입니다. LLM 호출 지연의 원인을 LLM 레이어에서 시작해 APM, Kubernetes, 인프라 영역까지 하나의 화면에서 드릴다운 방식으로 분석할 수 있습니다. 별도의 도구를 추가로 연결할 필요가 없습니다.
기존 와탭 환경에서 바로 시작할 수 있습니다. 이미 와탭을 사용 중이라면, 새로운 도구를 추가로 도입하거나 별도 학습 비용을 들이지 않고도 LLM 관측을 시작할 수 있습니다. 동일한 대시보드, 동일한 알림 체계, 동일한 운영 팀이 LLM 환경까지 함께 커버할 수 있습니다.




.png)





