.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
CPU Steal Time, 내 서버가 CPU를 빼앗기고 있었다

서버 응답이 느려지고, 간헐적으로 타임아웃이 발생했습니다. 처음에는 애플리케이션 문제라고 생각했습니다. CPU 사용률이 40%대에 머물러 있어, 겉으로 보기에 서버 리소스가 부족해 보이지 않습니다. 코드를 다시 확인했고, DB 쿼리도 확인했습니다. 하지만 어디서도 뚜렷한 이상은 보이지 않았습니다.
그때 top 출력 한 줄이 눈에 들어왔습니다.
%Cpu(s): 28.9%us, 0.3%sy, 0.0%ni, 0.0%id, 0.0%wa, 0.0%hi, 0.8%si, 70.0%stst 값이 70%였습니다. CPU 시간의 70%를 내 프로세스가 아닌 다른 무언가가 가져가고 있었던 겁니다.
CPU Steal Time이란?
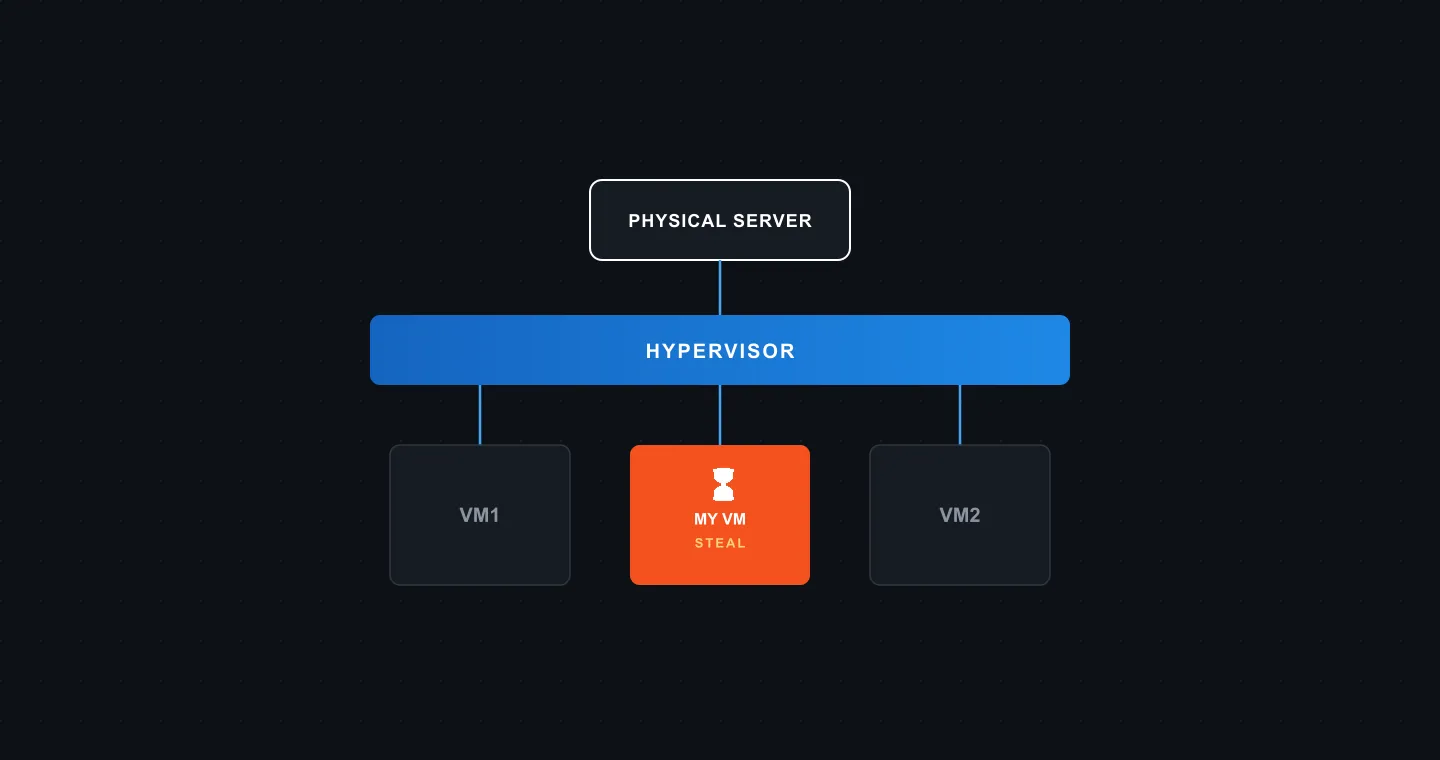
st(steal time)는 가상화 환경에서만 의미 있는 메트릭입니다. 하이퍼바이저가 같은 물리 호스트 위의 다른 VM을 처리하는 동안, 내 VM의 가상 CPU가 실제 물리 CPU를 기다리는 시간을 비율로 나타낸 값입니다.
쉽게 풀어보겠습니다. 내가 CPU를 쓰려고 손을 뻗는데, 하이퍼바이저가 그 자원을 옆 VM에 먼저 주고 있는 상황입니다. 내 프로세스는 실행할 준비가 됐는데 순서를 기다리는 것입니다. 이때 쌓이는 대기 시간이 st입니다. 물리 서버에서는 이 값이 보통 의미를 갖지 않습니다. 0에 가까운 값이 나와도 정상입니다. st가 문제가 되는 건 클라우드나 가상화 인프라 위에서 운영할 때입니다.
top 명령의 CPU 항목을 풀어 보면 다음과 같습니다.
왜 이런 일이 생기는가
CPU steal time이 높아지는 원인은 크게 두 가지로 볼 수 있습니다.
첫째, 물리 호스트 자원 자체가 부족한 경우입니다. 하나의 물리 서버 위에 VM을 너무 많이 올려놓으면, 각 VM이 CPU를 얻으려고 경쟁합니다. 호스팅 업체가 밀도 높게 VM을 채울수록 이 경합은 심해집니다.
둘째, VM에 할당된 CPU 자원이 제한된 경우입니다. 물리 호스트에 자원은 충분하더라도, 관리자가 VM별 자원 상한을 잘못 설정하면 특정 VM이 CPU를 독점하고 나머지가 피해를 봅니다.
둘 다 내 코드나 서비스 로직과는 무관합니다. 운영자 입장에서 답답한 지점도 여기에 있습니다. 애플리케이션을 아무리 살펴봐도 원인이 보이지 않기 때문입니다.
서비스에 어떤 영향을 주는가
배치 작업처럼 응답 시간이 중요하지 않은 작업은 크게 문제가 없습니다. 처리가 좀 더 오래 걸릴 뿐, 작업 자체가 실패하지는 않습니다. 하지만 웹 애플리케이션은 다릅니다. 클라이언트 요청에 즉시 응답해야 하는 상황에서 CPU 자원을 빼앗기면, 요청이 처리 큐에 쌓이기 시작합니다. 요청이 들어오는 속도보다 처리 속도가 느려지면 큐에 대기하는 요청이 쌓이고, 결국 타임아웃으로 이어질 수 있습니다.
앞서 본 상황이 정확히 이 경우입니다. us 값만 보면 약 29%로 여유가 있어 보입니다. 하지만 st가 70%라는 것은, 그 시간 동안 내 VM이 CPU를 사용하고 싶었지만 실제로는 할당받지 못한 시간이 70%에 달했다는 의미입니다. 결국 내 VM이 실제로 CPU를 받아 실행될 수 있었던 시간은 나머지 30% 남짓에 불과했습니다. 그래서 CPU 사용률만 보면 여유가 있어 보였지만, 서비스 입장에서는 요청을 처리할 실행 시간이 부족했고 응답 지연과 타임아웃으로 이어졌습니다.
현실적인 대응 방법
문제를 파악한 뒤에도 선택지는 제한적입니다. 클라우드나 호스팅 환경을 사용하는 입장에서 물리 호스트나 하이퍼바이저를 직접 조정할 수 없습니다.
CPU steal time 문제를 근본적으로 줄이려면 인프라 제공자의 조치가 필요합니다.
- VM별 CPU 할당 정책을 조정해 특정 VM의 과도한 점유를 제한한다
- 하이퍼바이저나 가상화 스택을 개선해 자원 분배 문제를 완화한다
- 물리 서버의 CPU를 업그레이드하거나 코어 수를 늘린다
- CPU 부하가 높은 VM을 다른 물리 호스트로 이전해 부하를 분산한다
업체에 문의해도 대부분 “계약에 맞게 정상 제공 중”이라는 답변이 돌아옵니다. 그래서 현실적으로 시도해볼 수 있는 방법은 보통 두 가지입니다. 더 높은 사양의 인스턴스로 업그레이드하거나, 다른 물리 호스트에 있는 인스턴스로 재배포하는 것입니다.
같은 인스턴스 타입이더라도 어떤 물리 호스트에 올라가 있느냐에 따라 st 값은 달라질 수 있습니다. 재배포 후 st 값이 크게 낮아지면서 문제가 완화되는 경우도 있습니다. 서버 사양은 같았지만, 물리 호스트가 바뀌자 CPU를 기다리는 시간이 거의 사라진 것입니다.
모니터링 없이는 원인을 못 찾는다
.webp)
top은 지금 이 순간의 값만 보여줍니다. 장애가 발생했을 때 이미 문제가 지나간 경우도 많습니다. “아까는 느렸는데 지금은 괜찮다”는 상황에서 top만으로 아무것도 확인할 수 없습니다. 이때 st 값을 시계열로 수집해두는 것이 중요합니다. CPU Steal 메트릭을 지속적으로 기록해두면, 장애 발생 시점 전후의 값을 나중에 다시 확인할 수 있습니다. 예를 들어 장애가 발생한 시간대에 st가 평소보다 크게 치솟았다가 내려간 패턴이 보인다면, CPU steal time이 응답 지연의 원인이었는지 판단하는 중요한 단서가 될 수 있습니다.
와탭 인프라 모니터링에서 CPU Steal 메트릭을 시계열로 확인할 수 있습니다. 순간적인 top 출력만으로는 놓치기 쉬운 값도 그래프로 남기 때문에, 장애 발생 시점 전후의 CPU 상태를 되짚어볼 수 있습니다. CPU 사용률만 보는 것과 st까지 함께 보는 것은 볼 수 있는 범위가 다릅니다. 클라우드 인프라를 운영한다면 CPU 사용률뿐 아니라 CPU Steal Time도 기본 모니터링 항목에 포함해두는 것이 좋습니다.
마치며
CPU Steal Time은 내 코드 문제가 아닙니다. 서버가 올라가 있는 실행 환경의 문제에 가깝습니다. 그래서 더 당황스럽습니다. us 값은 낮은데도 서비스가 느리다면, CPU 사용률만 볼 것이 아니라 st 값도 함께 확인해야 합니다. 클라우드 환경에서 서버 자체가 느린 것이 아니라 서버의 차례가 계속 밀리고 있을 수도 있습니다.
와탭 서버 모니터링은 CPU Steal을 포함한 인프라 지표를 시계열로 수집하고, 장애 발생 시점 전후의 이력을 확인할 수 있습니다. 같은 문제를 겪고 있다면 간단한 에이전트 설치 후 14일 무료 체험으로 직접 확인해보세요.
더 읽을거리