.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
리눅스 서버 모니터링 명령어 8가지 (top, vmstat, ss 등)

서버에 문제가 생겼을 때, 모니터링 대시보드를 보기 전에 먼저 SSH로 들어가서 상황을 훑어보는 경우가 많습니다. 거창한 도구 없이 기본 명령어 몇 개만으로도 1차 진단은 충분히 가능하기 때문입니다.이 글에서는 그런 상황에서 자주 쓰는 8개 명령어(uname, ip, top, free, vmstat, iostat, ss, df)를 용도별로 정리했습니다. 전부 리눅스에 기본 설치돼 있어서 별도 준비는 필요 없습니다.
uname: 시스템과 커널의 정보
uname으로 커널과 시스템 정보를 확인합니다. -a 옵션이 전체 정보를 한 번에 보여줍니다.

출력 필드:
- [Linux]: 커널 명
- [srv01]: 호스트 명
- [6.10.14-linuxkit]: 커널 릴리즈 (일반 서버에서는
6.8.0-45-generic같은 형태) - [#1 SMP Thu Oct 24 19:28:55 UTC 2024]: 커널 빌드 정보
- [aarch64]: 머신 하드웨어 이름 (x86 서버는
x86_64, ARM 서버는aarch64) - [aarch64]: 프로세서 종류
- [aarch64]: 하드웨어 플랫폼
- [GNU/Linux]: 운영체제
자주 쓰는 옵션:
$ uname --helpa, --all: 전체 출력s, --kernel-name: 커널 명n, --nodename: 호스트 명r, --kernel-release: 커널 릴리즈v, --kernel-version: 커널 버전m, --machine: 머신 하드웨어 이름p, --processor: 프로세서 종류 또는 ‘unknown’i, --hardware-platform: 하드웨어 플랫폼 또는 ‘unknown’o, --operating-system: 운영체제
배포판 정보까지 보려면 cat /etc/os-release 또는 lsb_release -a가 편합니다.
ip: 네트워크 인터페이스 확인
네트워크 인터페이스 상태 확인은 ip(iproute2) 명령어가 표준입니다. 과거 ifconfig가 하던 역할인데, Ubuntu 18.04부터 net-tools가 deprecated 처리돼 최신 배포판에는 기본 설치되지 않는 경우가 많습니다.
레거시 서버에서 ifconfig를 써야 한다면 글 끝의 “부록: 레거시 명령어 참고”를 보세요.
자주 쓰는 형태:
$ ip addr show # 전체 인터페이스 + IP (줄여서 ip a)
$ ip addr show eth0 # 특정 인터페이스만
$ ip link # 링크 상태
$ ip -s link # 송수신 통계 포함
$ ip route # 라우팅 테이블출력 필드:
- [eth0, ens3, enp0s3 등]: 유선 네트워크 인터페이스. 최근 배포판은
eth0대신ens3,enp0s3같은 “예측 가능한 이름(Predictable Network Interface Names)”을 씁니다. - [lo]: 루프백 인터페이스 (IP
127.0.0.1). IP 주소는 서버가 아니라 인터페이스에 할당되므로, 인터페이스마다 다른 IP를 가질 수 있습니다. - [link/ether]: 하드웨어 주소 (MAC Address)
- [inet]: IPv4 주소
- [inet6]: IPv6 주소
- [mtu]: 최대 전송 단위. 일반 이더넷은 1500, 루프백은 65536이며, 컨테이너·가상 네트워크는 다른 값이 나올 수 있습니다.
- [state UP/DOWN/UNKNOWN]: 활성 상태. 루프백처럼 물리적 링크가 없는 가상 인터페이스는
UNKNOWN으로 표시되기도 합니다.
bare-metal 서버나 일부 VPS처럼 공인 IP가 인터페이스에 직접 바인딩된 환경이라면 ip addr 출력에 그대로 공인 IP가 보입니다. 반면 AWS EC2, 가정 공유기 뒤의 PC처럼 NAT 환경에서는 인터페이스에는 사설 IP만 할당되고 외부에서 보이는 공인 IP는 따로 확인해야 합니다.
$ curl ifconfig.me
$ curl -s https://ipinfo.io/ip
top: 프로세스 실시간 모니터링
윈도우 작업 관리자의 리눅스 버전입니다. CPU, 메모리 사용률과 프로세스 목록을 실시간으로 보여줍니다.
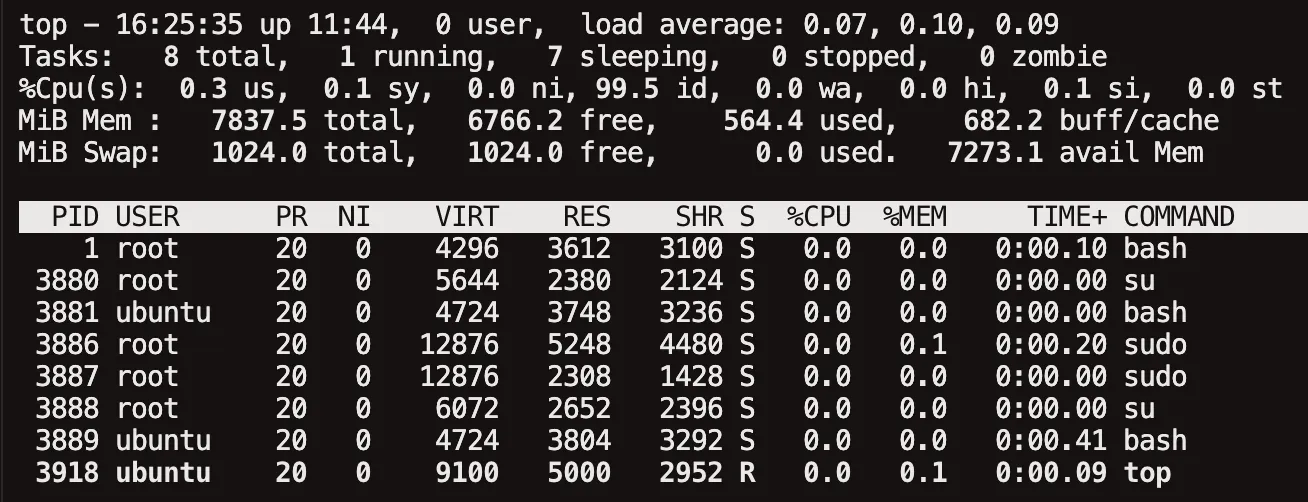
헤더 (요약 정보)
첫 줄에 시스템 요약이 나옵니다.
- [현재 시각]: 시스템 현재 시각
- [up]: 부팅 후 경과 시간 (uptime)
- [user]: 로그인 세션 수
- [load average]: 1분, 5분, 15분 동안의 평균 부하. 실행 중이거나 실행 대기(runnable) 중인 프로세스뿐 아니라, 디스크 I/O 등으로 인해 인터럽트가 불가능한 대기 상태(uninterruptible sleep, D 상태)에 있는 프로세스까지 포함해서 집계한다는 점이 중요합니다. CPU 코어 수보다 꾸준히 높으면 부하 신호지만, CPU 부족인지 I/O 병목인지는 이 값 하나로는 알 수 없고
vmstat의r/b컬럼이나iostat을 함께 봐야 판별됩니다.
Tasks
현재 프로세스 상태 요약입니다.
- [total]: 전체 프로세스 수
- [running]: 실행 중
- [sleeping]: 대기 중 (대부분 프로세스가 여기)
- [stopped]: 중지된 상태 (SIGSTOP 등)
- [zombie]: 종료됐지만 부모 프로세스가 아직 회수하지 않은 상태. 1~2개는 정상이지만 숫자가 계속 늘면 부모 프로세스에 문제가 있다는 신호입니다.
% Cpu(s)
- [us]: 사용자 공간 CPU 사용률
- [sy]: 커널 CPU 사용률
- [ni]: nice 값이 조정된 프로세스 사용률
- [id]: idle 비율
- [wa]: I/O 대기
- [hi]: 하드웨어 인터럽트
- [si]: 소프트웨어 인터럽트
- [st]: 가상화 환경에서 steal time
us가 높으면 애플리케이션 코드가 CPU를 태우는 중, sy가 높으면 커널/시스템 호출이 많다는 뜻입니다. id가 계속 0이면 100% 사용 상태이므로 원인 프로세스를 찾아야 합니다. 클라우드 VM에서는 st도 눈여겨봐야 합니다. 호스트가 바빠서 내 VM이 CPU를 뺏기고 있다는 신호입니다.
PROCESS
- [PID]: 프로세스 ID
- [USER]: 실행 사용자
- [PR]: 우선순위
- [NI]: NICE 값 (마이너스일수록 우선순위 높음)
- [VIRT]: 프로세스가 예약한 전체 가상 메모리. 상주 메모리와 스왑된 영역뿐 아니라 mmap으로 매핑만 해두고 아직 접근하지 않은 영역까지 포함되므로, 실제 물리 메모리 사용량과 크게 차이 날 수 있습니다.
- [RES]: 실제 메모리에 상주 중인 크기 (Resident Set Size). 실 사용량에 가까운 지표.
- [SHR]: 다른 프로세스와 공유 가능한 메모리 (공유 라이브러리 등)
- [S]: 상태 (R: 실행, S: 대기, D: 중단 불가 대기, Z: 좀비)
- [%CPU]: CPU 사용률
- [%MEM]: 메모리 사용률
- [TIME+]: 누적 CPU 시간
- [COMMAND]: 실행 명령어
정렬 단축키
top 실행 중 Shift + 영문자로 정렬 기준을 바꿉니다.
- [SHIFT + M]: 메모리
- [SHIFT + N]: PID
- [SHIFT + P]: CPU
- [SHIFT + T]: 실행 시간
- [SHIFT + R]: 오름/내림차순 토글
htop, btop 같은 개선판도 있지만 기본 설치돼 있는 건 top뿐입니다. 기본기부터 익히는 게 안전합니다.
free: 메모리 모니터링
메모리 상태를 확인합니다. -h 옵션은 GiB/MiB 단위로 보기 좋게 출력하고, -t 옵션은 메모리와 스왑 합계를 보여줍니다.

- [Mem]: 물리 메모리
- [Swap]: 스왑 (디스크 기반 가상 메모리)
- [shared]: 여러 프로세스가 공유하는 메모리 (대부분
tmpfs). 실제 여유 메모리 판단에는 크게 영향을 주지 않습니다. - [buff/cache]: I/O 캐시용 메모리. 필요하면 커널이 즉시 회수합니다.
- [available]: 새 프로세스가 스왑 없이 쓸 수 있는 메모리
여유 메모리를 볼 때는 available을 보면 됩니다. 예전에는 used - (buffers + cached) 식으로 수동 계산했는데, 최신 free의 available은 페이지 캐시와 회수 가능한 slab 영역까지 반영한 “스왑 없이 새 프로세스를 시작할 수 있는 추정치”입니다. 수동 계산보다 정확해서 used가 커 보여도 available이 충분하면 여유가 있다고 봐도 됩니다.
단위 옵션:
free -b: 바이트free -k: KBfree -m: MBfree -g: GBfree -h: 자동 단위free -s 2: 2초 간격 반복
vmstat: CPU, 메모리, I/O 종합
프로세스, 메모리, 스왑, 블록 I/O, CPU 상태를 한 화면에 요약해서 보여줍니다.

procs
- [r]: 실행 대기 중인 프로세스 수. CPU 코어 수의 2배를 넘으면 CPU 부족 신호.
- [b]: 인터럽트 불가능한 sleep 상태(I/O 블록)의 프로세스 수. 지속적으로 높으면 디스크 I/O 점검.
Swap (KB/s)
- [si]: swap in. 디스크 swap에서 메모리로 가져온 양.
- [so]: swap out. 메모리에서 디스크 swap으로 내보낸 양.
so가 지속적으로 0보다 크면 물리 메모리가 부족하다는 뜻입니다. 메모리 증설이나 프로세스 최적화가 필요합니다. 순간적으로 튀는 건 괜찮습니다.
memory (KB)
- [swpd]: 사용 중인 스왑 메모리
- [free]: 사용되지 않은 메모리
- [buff]: 버퍼 캐시
- [cache]: 페이지 캐시
io (blocks/s)
- [bi]: block in. 디스크에서 읽어온 블록 수.
- [bo]: block out. 디스크로 쓴 블록 수.
bi, bo가 지속적으로 높다면 디스크 I/O가 많다는 뜻입니다. 어느 장치가 그 부하를 받는지는 iostat에서 확인합니다.
system
- [in]: 초당 인터럽트 수 (시계 인터럽트 포함)
- [cs]: 초당 context switch 수. 비정상적으로 높으면 프로세스·스레드 경쟁이 심하다는 신호입니다.
cpu (%)
- [us]: 사용자 공간
- [sy]: 커널 공간
- [id]: idle
- [wa]: I/O 대기
- [st]: 가상화 환경의 steal time
- [gu]: guest time. 호스트가 KVM guest 코드를 실행하는 데 쓴 시간 (guest nice 포함).
s옵션은 메모리 통계를 요약해서 보여줍니다.

vmstat [delay [count]]로 실시간 추적:
$ vmstat 3 5 # 3초 간격으로 5번
$ vmstat 1 # 1초 간격 (Ctrl+C로 중지)더 세밀한 I/O 분석은 iostat, 커널 이벤트 추적은 perf나 bpftrace로 넘어갑니다.
iostat: CPU/디스크 I/O
CPU 사용률과 디스크 I/O 세부 내용을 확인합니다. sysstat 패키지에 있어서 별도 설치가 필요할 수 있습니다 (sudo apt install sysstat).

avg-cpu
시스템 전체 CPU 사용률 요약입니다. top의 %Cpu(s)와 같은 의미를 가지며, 디스크 I/O와 나란히 보기 위해 함께 출력됩니다.
- [%user]: 사용자 공간 CPU 사용률
- [%nice]: nice 값이 조정된 프로세스 사용률
- [%system]: 커널 공간 CPU 사용률
- [%iowait]: I/O 대기 중인 CPU 비율. 이 값이 높으면서 디스크 I/O가 많다면 디스크 병목입니다.
- [%steal]: 가상화 환경의 steal time
- [%idle]: idle 비율
Device
- [tps]: 초당 전송 요청 수
- [kB_read/s]: 초당 읽은 KB
- [kB_wrtn/s]: 초당 쓴 KB
- [kB_read]: 누적 읽기 KB
- [kB_wrtn]: 누적 쓰기 KB
x옵션을 붙이면 훨씬 상세한 지표를 볼 수 있습니다. 작업 종류별(read/write/discard/flush)로 컬럼이 분리되어 나옵니다.- [r/s, w/s, d/s, f/s]: 초당 각 작업(read/write/discard/flush) 요청 수
- [rkB/s, wkB/s, dkB/s]: 초당 각 작업의 KB
- [rrqm/s, wrqm/s, drqm/s]: 초당 merge된 요청 수 (커널이 인접 요청을 합친 것)
- [%rrqm, %wrqm, %drqm]: 전체 중 merge 비율
- [r_await, w_await, d_await, f_await]: 각 작업의 평균 응답 시간(ms). 레이턴시 병목을 판단할 때 제일 먼저 보는 지표입니다.
- [rareq-sz, wareq-sz, dareq-sz]: 각 작업의 평균 요청 크기 (KB)
- [aqu-sz]: 평균 I/O 큐 길이
- [%util]: 장치 사용률
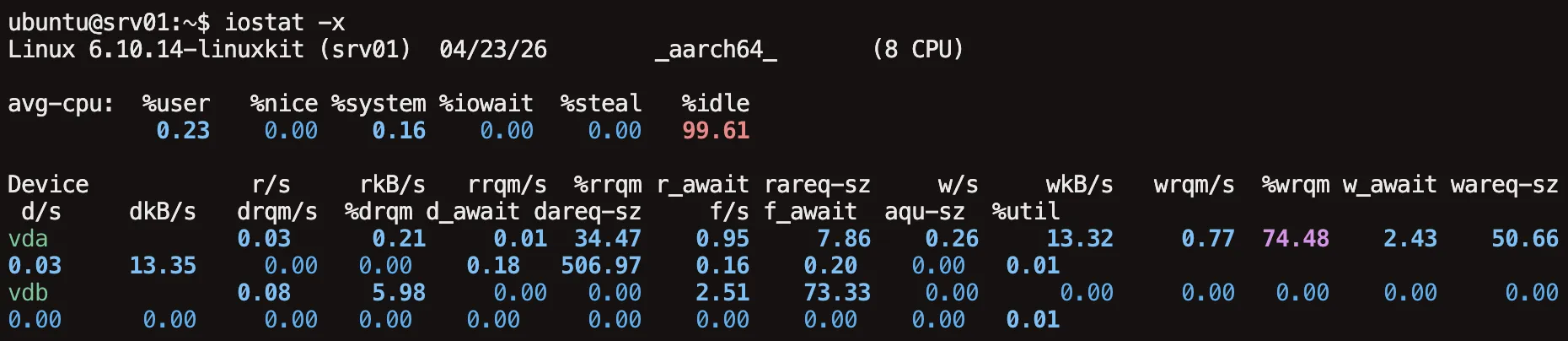
실시간 관찰:
$ iostat 3 5 # 3초 간격으로 5번
$ iostat -x 1 # 확장 정보를 1초 간격NVMe/SSD가 일반화되면서 %util 하나만으로 병목을 단정하긴 어려워졌습니다. 장치가 순차 요청 하나를 계속 처리하는 동안에도 %util은 100%에 가까워질 수 있지만, 내부적으로 처리할 여력은 남아 있을 수 있기 때문입니다. %util은 출발점으로만 보고, 실제 병목 여부는 await(평균 응답 시간), aqu-sz(평균 큐 길이), 처리량(kB/s)을 함께 놓고 판단하는 것이 안전합니다.
ss: 네트워크 연결 상태 확인
소켓 정보를 확인하는 표준 도구입니다. 과거에는 netstat을 썼지만, ss는 커널의 netlink 인터페이스를 직접 사용해서 빠릅니다. 연결이 많은 서버에서는 netstat보다 10배 이상 빠른 경우도 있습니다. 기본 단일 문자 플래그(-t, -u, -n, -l, -p 등)는 netstat과 호환되어 적응이 쉽지만, 상태·주소 필터 같은 고급 문법은 ss 고유입니다.
레거시 서버에서 netstat을 써야 한다면 글 끝의 “부록: 레거시 명령어 참고”를 보세요.
출력 컬럼
- [Netid]: 프로토콜 (tcp, udp, unix 등)
- State: 소켓 상태 (아래 “소켓 상태” 참고)
- [Recv-Q]: 수신 큐에서 대기 중인 바이트 수. LISTEN 소켓에서는 “현재 대기 중인 연결 요청 수”를 뜻합니다.
- [Send-Q]: 송신 큐에서 대기 중인 바이트 수. LISTEN 소켓에서는 “백로그 최대치”(accept 대기열 한도)를 뜻합니다.
- [Local Address:Port]: 로컬 주소와 포트
- [Peer Address:Port]: 상대 주소와 포트 (LISTEN 소켓은
0.0.0.0:*로 표시) - Process: 소켓을 사용하는 프로세스 정보 (
p옵션 필요, root 권한)
자주 쓰는 옵션:
t: TCP만u: UDP만n: 호스트명/포트명 조회 생략 (빠름)l: LISTEN 상태만p: 소켓을 쓰는 프로세스 표시 (root 필요)a: 모든 상태s: 프로토콜별 요약m: 소켓 메모리 사용량
자주 쓰는 조합:
$ ss -tunlp # TCP/UDP LISTEN 소켓 + 프로세스
$ ss -s # 프로토콜별 요약
$ ss -nat # 모든 TCP 소켓
$ ss -nap '( sport = :80 or dport = :80 )' # 80포트 관련 연결 (양방향)
$ ss -ntp state established '( dport = :443 or sport = :443 )' # HTTPS 활성 연결소켓 상태 (State)
- [LISTEN]: 연결 요청 대기
- [SYN-SENT]: 연결 요청 보냄
- [SYN-RECV]: 요청 받고 확인 대기
- [ESTABLISHED]: 연결 완료
- [FIN-WAIT-1]: 소켓 닫고 종료 진행
- [FIN-WAIT-2]: 상대의 종료 요구 대기
- [CLOSE-WAIT]: 상대가 종료 요청한 상태
- [CLOSING]: 종료 중
- [TIME-WAIT]: 종료 직후 잠시 유지 (기본 60초)
- [CLOSED]: 완전 종료
df: 디스크 용량 확인
디스크 전체 용량과 남은 용량을 보여줍니다. 파일 시스템 타입은 환경에 따라 다릅니다. 일반 서버에서는 ext4, xfs가 흔하고, 컨테이너에서는 overlay가, RAM에 직접 마운트되는 영역에는 tmpfs가 보입니다. 아래 예시는 컨테이너 환경에서 실행한 결과입니다.

옵션:
h: 읽기 좋은 단위(KB/MB/GB)T: 파일 시스템 종류(ext4, xfs, btrfs) 함께 표시i: inode 사용량 (용량은 남는데 파일이 안 만들어지면 inode 고갈일 확률이 높음)
디렉토리별로 누가 용량을 먹는지 보려면 du -sh *, 더 편하게는 ncdu를 씁니다. 컨테이너 환경에서는 df -h /var/lib/docker처럼 경로를 콕 찍어서 보는 게 디버깅에 유리합니다.
한계와 다음 단계
소개한 명령어들은 “지금 이 서버에서 뭐가 돌아가는지”를 확인하는 데는 빠르고 정확합니다. 다만 대상이 서버 한 대에서 수십 대로 늘어나거나, 조사해야 할 시점이 과거로 가거나, 담당자 없을 때 알림이 필요해지는 순간 금방 한계가 옵니다.
- 서버가 수십, 수백 대라 SSH로 일일이 들어가기 어려울 때
- 어젯밤 3시 CPU 스파이크 원인을 지금 찾아야 할 때
- 임계치 초과 시 Slack이나 모바일 앱으로 알림이 필요할 때
- SSH 권한이 없는 팀원도 상태를 확인해야 할 때
이때부터 서버 모니터링 도구의 영역입니다. 와탭 서버 모니터링은 이런 운영 상황을 전제로 만들어져, 원격에서 과거 지표까지 조회하고 이상 상황에는 자동으로 알림을 보냅니다. 일단 명령어로 기본기를 잡아두고, 운영 규모가 커질 때 도구를 얹는 쪽이 현실적입니다.
부록: 레거시 명령어 참고
ifconfig, netstat은 공식적으로 deprecated이지만 기존 서버, 오래된 스크립트, 옛날 매뉴얼에는 계속 등장합니다. 여기서는 이걸 마주쳤을 때 참고할 수 있도록 원문 그대로 정리했습니다. 신규 시스템이라면 본문의 ip, ss 섹션만 봐도 됩니다.
두 명령어 다 net-tools 패키지에 들어있고, 최신 배포판에는 기본 설치돼 있지 않습니다.
$ sudo apt install net-tools # Debian/Ubuntu
$ sudo dnf install net-tools # RHEL/Fedora
ifconfig: 네트워크 기본 모니터링 (레거시)
시스템 네트워크 인터페이스의 상태를 확인하거나 변경합니다.

주요 필드:
- [eth0, eth1]: 흔히 랜 카드라고 불리는 유선 네트워크 인터페이스입니다. 최근 배포판은
eth0대신ens3,enp0s3같은 예측 가능한 이름을 씁니다. - [lo]: 루프백 인터페이스 (IP
127.0.0.1). 자기 자신과 통신하는 가상 장치입니다. IP는 서버가 아니라 인터페이스에 할당되기 때문에, 인터페이스마다 다른 IP를 갖습니다. - [HWaddr / ether]: 하드웨어 주소 (MAC Address)
- [inet addr / inet]: 할당된 IP 주소
- [Bcast / broadcast]: 브로드캐스트 주소
- [Mask / netmask]: 넷마스크
- [MTU]: 최대 전송 단위
- [RX packets]: 받은 패킷 정보
- [TX packets]: 보낸 패킷 정보
- [collisions]: 충돌된 패킷 수
net-tools 2.x 버전부터 출력 포맷이 바뀌어서 필드 이름이 일부 달라졌습니다 (HWaddr → ether, inet addr: → inet, Mask: → netmask). 의미는 같습니다.
NAT 환경(클라우드 EC2, 공유기 뒤 PC 등)에서는 인터페이스에 사설 IP만 할당되어 있어, 외부에서 보이는 공인 IP는 ifconfig 출력에 나타나지 않습니다. 이런 경우 외부 서비스에 질의하면 됩니다. (bare-metal 서버처럼 공인 IP가 인터페이스에 직접 바인딩된 환경에서는 그대로 보입니다.)
$ curl ifconfig.meip 명령어와의 매핑
netstat: 네트워크 상태 모니터링 (레거시)
연결된 네트워크 상태, 라우팅 테이블, 인터페이스 상태를 확인합니다.
.webp)
출력은 두 영역으로 나뉩니다.
- [Active Internet connections]: TCP, UDP, raw 소켓 연결 목록
- [Active UNIX domain sockets]: 유닉스 도메인 소켓 연결 목록
Internet connections 영역의 컬럼:
- [Proto]: 프로토콜 (tcp, udp 등)
- [Recv-Q]: 수신 큐에서 대기 중인 바이트
- [Send-Q]: 송신 큐에서 대기 중인 바이트
- [Local Address]: 로컬 주소와 포트
- [Foreign Address]: 원격 주소와 포트
- State: 소켓 상태 (아래 State 참고)
UNIX domain sockets 영역의 컬럼:
- [Proto]: 항상
unix - [RefCnt]: 이 소켓을 참조하는 프로세스 수
- [Flags]: 플래그 (대부분
[ ]로 비어 있음) - [Type]: 소켓 타입 (
STREAM,DGRAM,SEQPACKET등) - State: 상태 (
CONNECTED,LISTENING등) - [I-Node]: inode 번호
- [Path]: 유닉스 도메인 소켓의 파일 경로 (예:
/var/run/...)
옵션
n: 호스트명/포트명 lookup 생략, IP/포트 번호로 표시a: 모든 상태t: TCP만u: UDP만p: 해당 포트를 쓰는 프로그램과 PIDr: 라우팅 테이블s: 프로토콜별(IP, ICMP, TCP, UDP 등) 통계c: 연속 출력l: LISTEN 소켓만
State
- [공백]: 연결 없음
- [FREE]: 소켓은 있지만 할당 안 됨
- [LISTENING]: 연결 요청 응답 준비 완료
- [CONNECTING]: 연결 막 시작
- [DISCONNECTING]: 연결 해제 중
- [UNKNOWN]: 알 수 없는 상태
- [LISTEN]: daemon 떠 있고 연결 가능
- [SYN_SENT]: 연결 요청한 상태
- [SYN_RECEIVED]: 요청 응답 후 확인 메시지 대기
- [ESTABLISHED]: 연결 완료
- [FIN_WAIT1]: 소켓 닫히고 연결 종료 진행
- [FIN_WAIT2]: 원격의 종료 요구 대기
- [CLOSE_WAIT]: 종료 대기
- [CLOSING]: 전송 메시지 유실
- [TIME_WAIT]: 연결 종료 직후 잠시 유지
- [CLOSED]: 완전 종료
자주 쓰는 예
$ netstat -r # 라우팅 테이블
$ netstat -na # TCP/UDP 세션 목록
$ netstat -na | grep ESTABLISHED | wc -l # 활성 세션 수
$ netstat -nap | grep :80 | grep ESTABLISHED | wc -l # 80포트 동시 접속자
$ netstat -nltp # LISTEN 포트 + 프로세스ss 명령어와의 매핑
와탭 서버 모니터링은 멀티테넌트로 팀원 누구나 원격에서 지표와 알림을 받을 수 있습니다. → 와탭 무료로 시작하기








