.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
NMS 솔루션 도입 전 이 4가지는 꼭 체크하세요!
.webp)
안녕하세요! AI 네이티브 옵저버빌리티 플랫폼, 와탭랩스입니다.
최근 IT 인프라는 스위치와 라우터 중심의 단순한 구조를 넘어, NAC·IPS·WAF와 같은 보안 어플라이언스, 가상화 환경(VMware), HCI, 물리 서버가 혼재된 형태로 빠르게 복잡해지고 있습니다.
문제는 관리 대상은 급격히 증가하는 반면, 운영자가 전체 상황을 하나의 화면에서 구조적으로 파악할 수 있는 체계가 여전히 부족하다는 점입니다. 특히, AI 기반 서비스와 데이터 플랫폼이 확산되면서 인프라 가시성은 단순 모니터링이 아닌, 옵저버빌리티(Observability)를 지탱하는 핵심 기반 계층으로 재조명되고 있습니다.
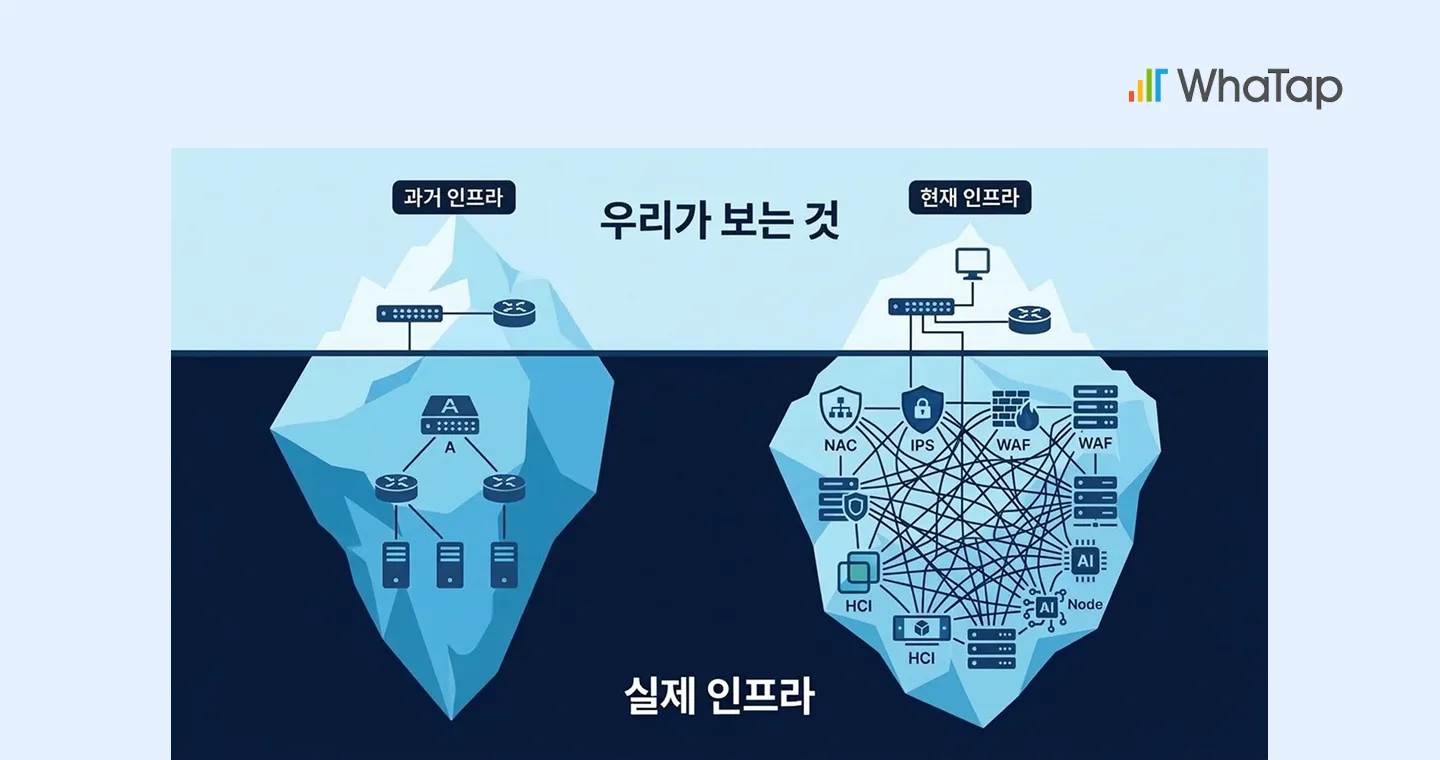
장애 대응이 지연되는 이유는 해결 방법을 몰라서가 아닙니다. 실제로 대부분의 시간은 다음과 같은 질문에 답을 찾는 데 소모됩니다.
- 어떤 장비, 어떤 네트워크 링크에서 이상이 발생했는가
- 단순 성능 저하인가, 이벤트 기반 장애인가
- 영향 범위가 특정 구간에 국한되는가, 서비스 전체로 확산되는가
결국, 문제 해결 이전에 ‘가시성을 확보하는 과정’ 자체가 병목이 되는 경우가 많습니다. 따라서 NMS 도입을 검토할 때는 기능의 많고 적음이 아니라, 실제 운영 환경에서 요구되는 기술적 기준을 중심으로 판단하는 것이 중요합니다.
이 글에서는 NMS 도입 또는 교체를 검토하는 과정에서 반복적으로 등장하는 네 가지 기술적 기준을 체크리스트 형태로 정리했습니다. 실제 운영에서 필요한 조건을 중심으로 구성한 만큼, NMS 도입 의사결정에 실질적인 도움이 되길 바랍니다.
🎯 NMS 도입 체크리스트 4가지
- 체크리스트 01. 표준 프로토콜 수집 체계와 지표 확장 구조
- 체크리스트 02. 인터페이스·링크·트래픽 기반의 실질적 네트워크 상태 분석
- 체크리스트 03. 계층형 그룹 기반 운영 체계
- 체크리스트 04. Polling 제어와 수집 부하 통제 구조
체크리스트 01. 표준 프로토콜 수집 체계와 지표 확장 구조
네트워크 장비 모니터링을 위한 기본 수집 체계
네트워크 장비 및 보안 어플라이언스(L2/L3 스위치, 라우터, 방화벽 등)는 대부분 폐쇄형 OS 기반으로 동작하거나, 벤더 정책 및 보안 요구사항에 따라 외부 소프트웨어 설치가 제한됩니다. 특히 금융, 공공, IDC 환경에서는 에이전트 설치가 원칙적으로 금지되는 경우가 일반적입니다.
따라서 NMS는 장비 내부에 별도의 실행 코드를 배포하지 않고, 장비가 기본 제공하는 관리 인터페이스를 통해 상태 및 성능 데이터를 수집하는 비침투형(Non-intrusive) 구조로 설계되어야 합니다.
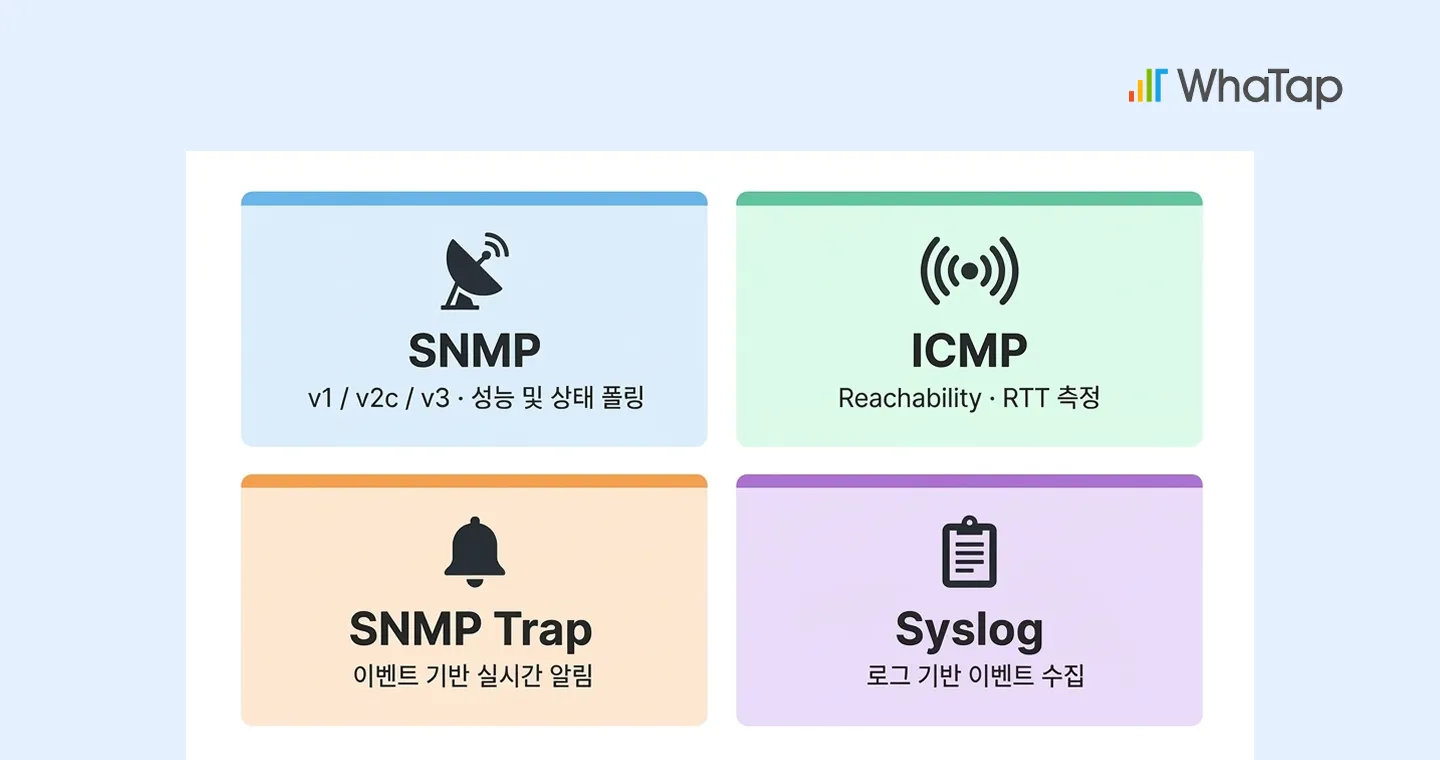
이를 위해 NMS가 갖춰야 할 표준 프로토콜 기반 수집 체계는 다음과 같습니다.
- SNMP (v1 / v2c / v3) - 장비 성능 및 상태 지표를 폴링 방식으로 수집하며, v3는 인증·암호화를 지원해 보안 요구사항이 높은 환경에서 필수적입니다.
- ICMP - Reachability 확인 및 RTT 측정에 활용되며, RTT 변동값을 기반으로 Jitter를 추정할 수 있습니다. 정밀한 Jitter 분석이 필요한 경우 IP SLA 연동을 별도로 고려해야 합니다.
- SNMP Trap - 장비에서 발생하는 이벤트 기반 알림을 수신하여 상태 변화를 실시간으로 감지합니다.
- Syslog - 보안 정책 이벤트, 인증 실패, 설정 변경 등 로그 기반 이벤트 수집에 활용됩니다.
이러한 수집 방식은 단일 프로토콜 의존이 아닌 상호 보완적인 구조로 설계되어야 하며, 특정 프로토콜이 제한되거나 비활성화된 환경에서도 모니터링 공백이 발생하지 않도록 다중 수집 경로를 확보하는 것이 중요합니다. 이 중 하나라도 제한되면 보안 장비나 네트워크 코어 구간이 모니터링 사각지대가 될 수 있습니다.
단순 수집이 아니라 ‘운영 가능한 수집’인가?
운영 환경에서는 단순한 CPU·메모리 조회만으로는 충분하지 않습니다. 실제 운영에 필요한 수집 범위는 다음과 같습니다.
- 인터페이스 In/Out Throughput
- Error / Discard / CRC Error 지표
- Link Up/Down 상태 변화
- 특정 벤더 MIB 기반 성능 지표 (세션 수, 정책 카운트 등)
- Trap 기반 실시간 상태 변화
- Syslog 기반 정책 및 보안 이벤트
핵심은 폴링(Polling)과 이벤트(Event) 수집이 결합된 구조를 갖추는 것입니다. 폴링만으로는 상태는 확인할 수 있지만 원인 파악이 지연되고, 이벤트만으로는 추세 분석이 어렵습니다.
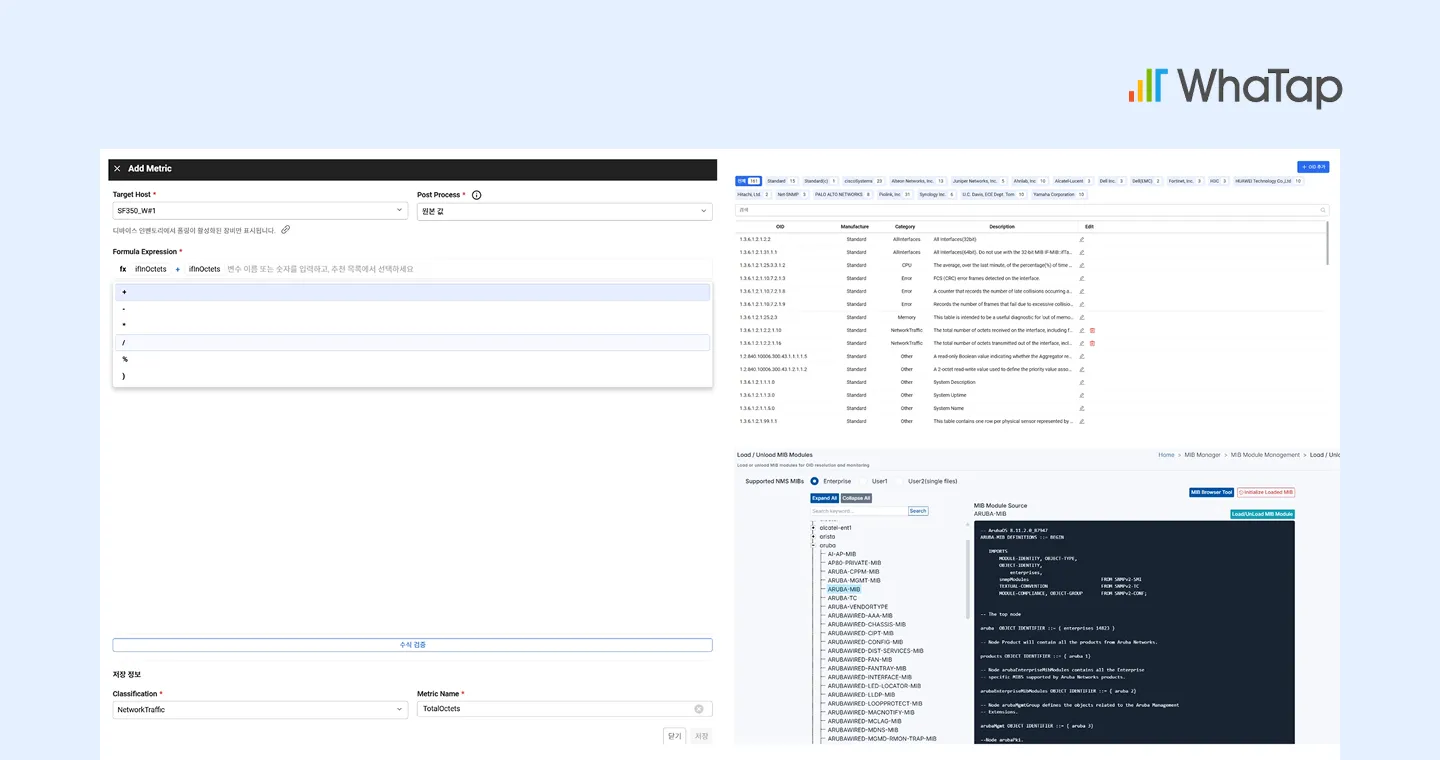
확장 가능한 구조인가: OID 등록 기반 지표 확장
“새로운 장비나 벤더 특화 지표가 필요해질 경우 어떻게 대응할 것인가?”
현실의 인프라는 지속적으로 변화합니다. 신규 벤더 장비 도입, HCI 환경의 특수 성능 지표, 내부 운영 기준에 따른 커스텀 지표 설정 등 새로운 수집 요구가 계속 발생합니다. NMS가 사전에 정의된 지표만 제공한다면, 운영 요구가 생길 때마다 제품 의존성이 높아질 수밖에 없습니다.
와탭에서는
와탭 NMS는 OID를 직접 등록하여 필요한 지표를 확장할 수 있는 구조를 제공합니다. 등록한 OID는 자동으로 수집되며, 그래프와 대시보드에 반영되고, 조건 설정을 통해 운영 기준에 맞게 활용할 수 있습니다.
제품 업데이트를 기다리지 않고 운영 환경에 맞춰 지표를 직접 정의할 수 있는 구조로, 벤더 종속성을 최소화하고 신규 장비 도입 시 유연하게 대응할 수 있습니다. 또한 환경 변화에 따라 지속적으로 확장 가능한 운영 기반을 제공합니다.
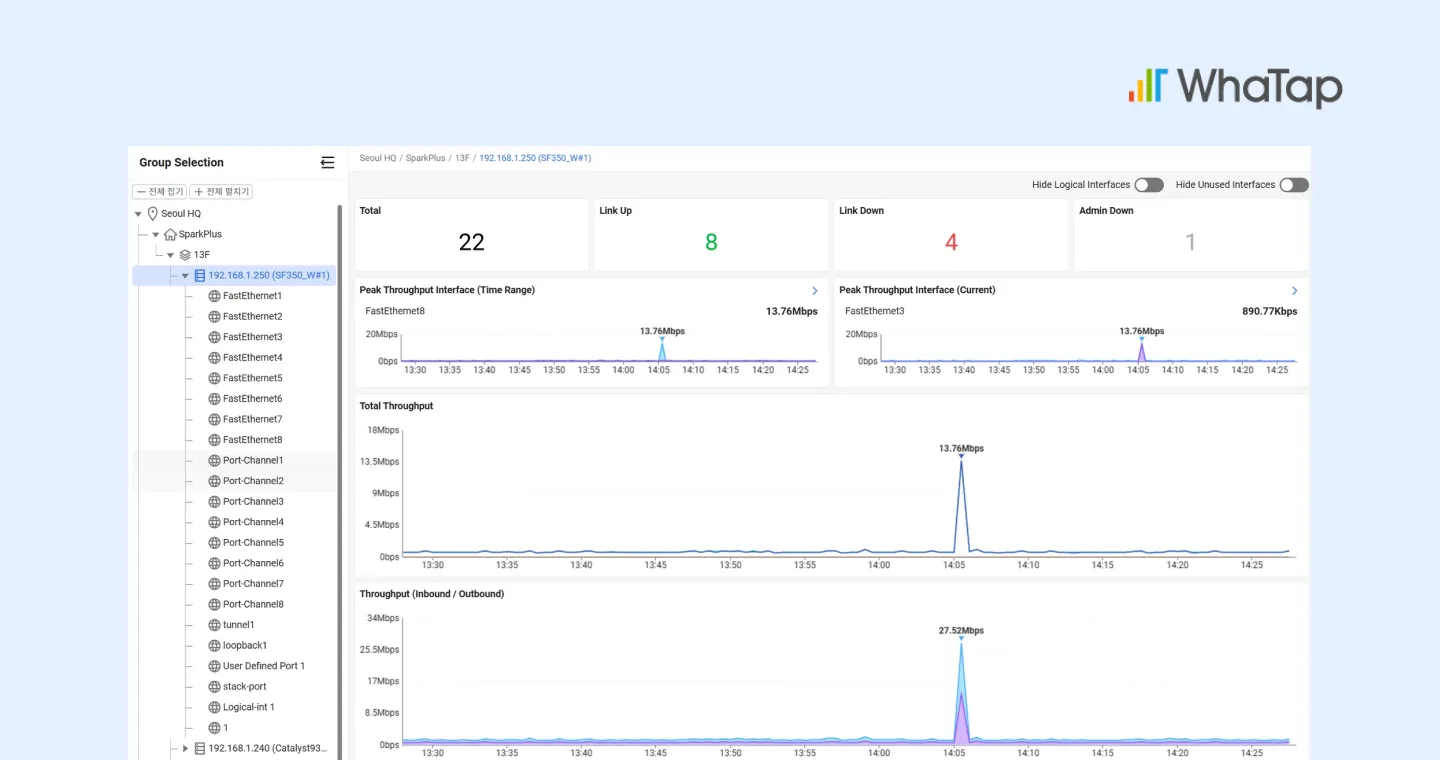
체크리스트 02. 인터페이스·링크·트래픽 기반의 실질적 네트워크 상태 분석
인터페이스 단위 가시성이 중요한 이유
현장에서 자주 발생하는 상황이 있습니다. 장비는 정상이고, Ping도 정상이며, CPU도 정상인데 특정 서비스만 느려지거나 끊기는 경우입니다. 이 경우 원인은 대부분 인터페이스 레벨에 있습니다.
- 특정 포트 트래픽 과부하
- Error / Discard 증가
- Link Flap(반복적 Up/Down) 발생
- 업링크 병목
장비 단위 모니터링만으로는 실제 네트워크 상태를 정확히 파악하기 어렵습니다.
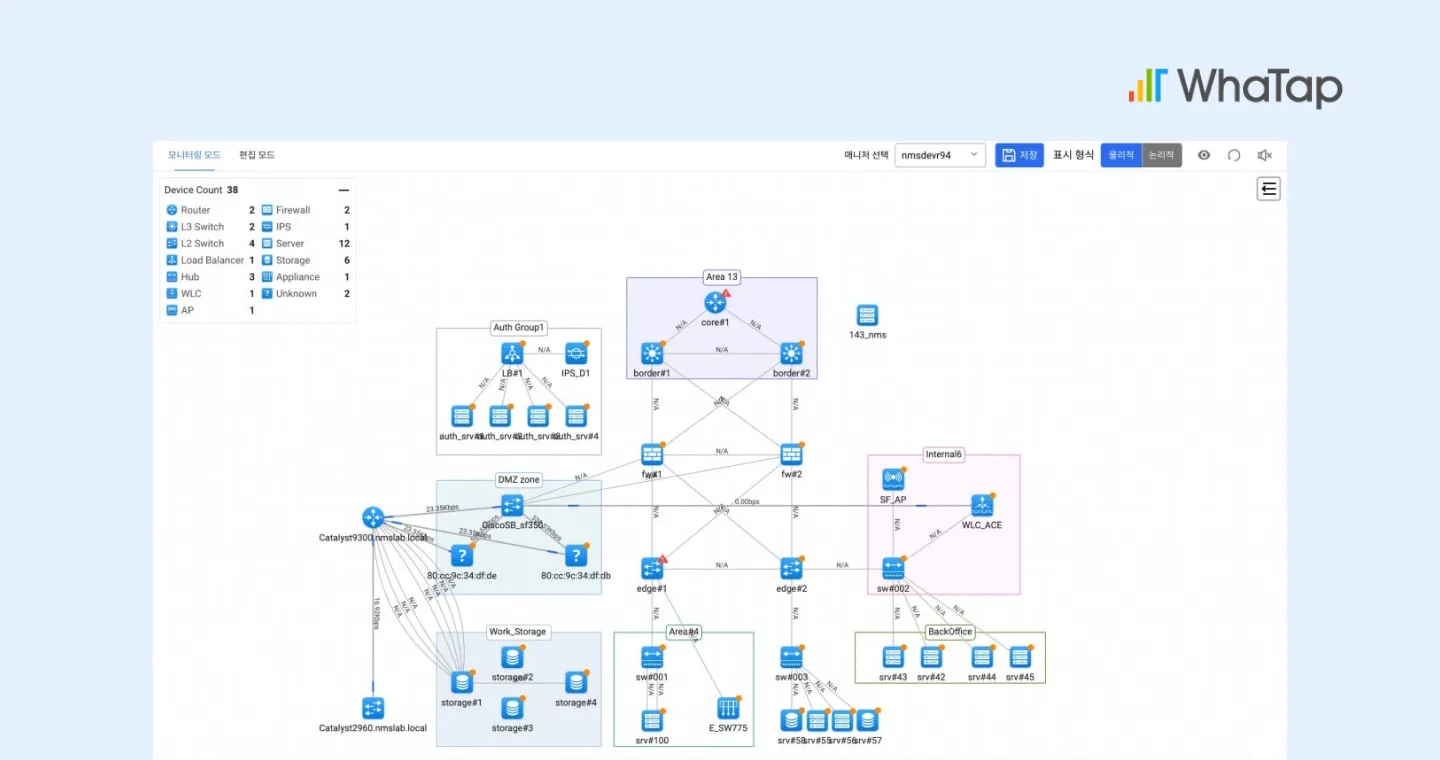
토폴로지 기반 연결 가시성
여기서 중요한 차이는 성능 지표가 토폴로지 맵과 연결되어 있는지 여부입니다. 예를 들어, 특정 코어 스위치의 업링크가 Down되면 해당 링크에 연결된 다수의 Access 스위치와 하위 서버 구간까지 영향이 확산됩니다.
토폴로지 맵에서 이러한 링크 상태 변화가 즉시 반영되면, 영향 범위를 직관적으로 파악할 수 있습니다.
네트워크 운영의 핵심은 단순한 “장비 상태 확인”이 아니라, 트래픽 흐름과 연결 구조를 함께 이해하는 것입니다. 인터페이스 단위 가시성과 토폴로지 연계가 없다면, 장애 분석은 여전히 수작업에 의존할 수밖에 없습니다.
와탭에서는
와탭 NMS는 장비별 인터페이스 단위의 In/Out Throughput, Error/Discard, Link 상태를 개별적으로 수집하고, 이를 토폴로지 맵과 연동합니다. 이를 통해 링크 상태 변화와 영향 범위를 시각적으로 파악할 수 있는 운영 환경을 제공합니다.
체크리스트 03. 계층형 그룹 기반 운영 체계
장비 수가 증가할수록 중요한 것은 기능이 아니라 ‘관리 구조’입니다.
장비가 많아질수록 무너지는 것은 ‘체계’
초기에는 장비 20~30대 수준이라면 목록 기반 관리로도 충분합니다. 그러나 3개 이상의 Site, 수백 대 장비, 코어·액세스·서버·보안 장비 혼재, 운영 조직 분리가 동시에 발생하면 단순 장비 리스트 기반 NMS는 구조를 유지하기 어렵습니다.
운영자는 다음과 같은 질문에 즉시 답할 수 있어야 합니다. 이 장비는 어느 Site에 속하는가, 어느 Building/Floor에 위치하는가, 어떤 역할(Core/Access/Firewall)을 수행하는가, 동일 그룹 내 다른 장비의 상태는 어떠한가.
계층형 그룹은 ‘보기 위한 기능’이 아니라 ‘운영 모델’
실제 인프라는 물리적·조직적 계층 구조를 기반으로 운영됩니다.
Site
└─ Building
└─ Floor
└─ Device이 구조가 NMS 안에서도 동일하게 표현되어야 운영과 관리가 일치합니다. 그렇지 않으면 장애 영향 범위 파악이 지연되고, 조직별 운영이 어려워지며, 보고 체계가 복잡해집니다. 계층형 그룹이 운영 모델로 기능하려면 상위 그룹 단위 상태 집계, 특정 그룹 기준 필터링, 위치 기반 관점의 장애 확인이 가능해야 합니다.
와탭에서는
와탭 NMS는 Site → Building → Floor → Device 형태의 계층형 그룹 구조를 지원하며, 상위 그룹 단위의 상태 집계와 필터링을 통해 대규모 환경에서도 운영 구조를 안정적으로 유지할 수 있도록 설계되었습니다.
체크리스트 04. Polling 제어와 수집 부하 통제 구조
NMS는 장비를 모니터링하지만, 설계가 잘못된 NMS는 오히려 네트워크에 부담을 줄 수 있습니다. 특히 대규모 인프라 환경에서는 장비 수 증가에 따른 폴링 트래픽 급증, 특정 시간대 폴링 집중으로 인한 응답 지연, 느린 장비로 인해 전체 수집 스케줄이 지연되는 문제가 발생합니다.
“이 NMS는 네트워크를 감시하면서도, 네트워크를 보호할 수 있는가?”
단순 수집이 아니라 ‘제어 가능한 수집’인가
운영 환경에서는 모든 장비를 동일한 주기로 폴링하는 방식이 적절하지 않습니다. 코어 스위치와 액세스 스위치는 중요도가 다르고, 핵심 방화벽과 테스트 장비는 요구되는 모니터링 밀도가 다르며, 일부 장비는 응답이 느리거나 리소스가 제한적일 수 있습니다.
장비 등급별 Polling 주기 설정 예시
대규모 환경에서 중요한 것은 얼마나 많이 수집하느냐가 아니라, 얼마나 안정적으로 통제하느냐입니다.
와탭에서는
와탭 NMS는 장비별 Polling 주기를 개별적으로 설정할 수 있으며, 장비 등급과 응답 특성에 따라 수집 밀도를 유연하게 조정할 수 있습니다. 이를 통해 모니터링 자체가 네트워크에 부하를 주는 상황을 방지할 수 있도록 설계되었습니다.
참고: 인증 및 라이선스 구조
공공기관 및 대기업 도입 검토 시 빈번하게 확인되는 항목을 정리합니다.
- GS인증 - 공공기관 SM 사업 및 조달 등록 시 요구되는 소프트웨어 품질 인증입니다. 와탭 NMS는 GS인증을 취득한 제품으로, 공공 부문 도입 요건을 충족합니다.
- 라이선스 체계 - NMS의 비용 구조는 관리 대상 장비 수 기반, 인터페이스 수 기반, 정액제 등 제품마다 상이합니다. 도입 검토 시 현재 관리 대상 규모와 향후 확장 계획을 함께 고려하여 비용 효율성을 판단하는 것이 중요합니다.
- HCI / VMware 지원 - HCI 및 가상화 환경에서는 vCenter 연동을 통한 ESXi 호스트 메트릭 수집, VM 단위 리소스 모니터링 지원 여부를 확인해야 합니다. 와탭은 물리 인프라와 가상화 계층을 통합적으로 모니터링할 수 있는 구조를 제공합니다.
결론: AI 시대에도 변하지 않는 NMS 선택 기준
AI 기반 서비스와 데이터 플랫폼은 빠르게 확산되고 있으며, Observability 역시 애플리케이션과 모델 중심으로 진화하고 있습니다.
그러나 AI 워크로드 역시 여전히 네트워크 장비, 보안 어플라이언스, 물리·가상 인프라 위에서 동작합니다. 이에 따라 트래픽 구조는 더욱 복잡해지고, 지연에 대한 허용 범위는 줄어들며, 인프라 안정성의 중요성은 오히려 더욱 커지고 있습니다.
이번에 살펴본 네 가지 기준은 단순한 기능 비교가 아니라, 대규모 환경에서도 지속적으로 운영 가능한 조건을 점검하기 위한 기준입니다.
- 표준 프로토콜 수집과 OID 등록을 통한 지표 확장 구조
- 인터페이스·링크 중심 분석과 토폴로지 연계
- 계층형 그룹 기반의 운영 관리 체계
- 장비 등급별 Polling 주기 제어와 수집 부하 통제
와탭 NMS는 이러한 원칙을 기반으로 안정적인 인프라 가시성을 제공하며, 상위 Observability 구조와의 연계를 고려해 지속적으로 고도화되고 있습니다.
Observability의 완성은 결국 보이지 않는 인프라 계층을 얼마나 정밀하게 이해하고 있는가에 달려 있습니다.
NMS 자주 묻는 질문 (FAQ)
Q1. 기존 NMS에서 와탭 NMS로 전환할 때 장비를 처음부터 다시 등록해야 하나요?
네. 일반적으로 기존 NMS에서 Whatap NMS로 전환할 때는 설정을 처음부터 다시 구성해야 합니다. 다만, 완전히 처음부터 모든 것을 새로 설계하는 것은 아닙니다. 기존 NMS에서 이미 해당 고객 환경에 맞춰 모니터링 대상 장비, 인터페이스, 그리고 필요한 OID 지표를 선정해 운영하고 있기 때문에 그 정보를 기준으로 Whatap NMS에 동일한 항목을 재구성하면 됩니다.
즉, 기존 NMS의 설정과 수집 항목을 확인한 뒤 Whatap NMS에서 같은 기준으로 모니터링 정책을 설정하면, 고객사 운영 환경에 맞는 형태로 이관을 마무리할 수 있습니다.
Q2. 토폴로지 맵은 자동으로 구성되나요, 아니면 수동으로 그려야 하나요?
와탭 NMS는 네트워크 토폴로지를 자동 탐색해 시각화하며, 장비 추가나 환경 변화에도 유연하게 대응합니다. 기본적으로 장비와 링크 구조가 자동으로 맵에 반영되며, 필요에 따라 편집 모드에서 세부 조정도 가능합니다.
편집 모드에서는 영역을 생성하거나 노드 속성을 수정해 화면 배치를 관리할 수 있으며, Drag & Drop으로 요소 위치를 변경할 수 있습니다. 또한 링크 다운 등 실시간으로 발생하는 이벤트가 즉시 반영되기 때문에 관리자가 네트워크 상태를 빠르게 파악할 수 있습니다.
Q3. 장애 발생 시 알림(Alert)은 어떤 조건과 채널로 받을 수 있나요?
와탭은 이벤트 설정 메뉴를 통해 임계치 기반 알림 조건 및 수신 설정을 제공합니다. CPU, 메모리, 트래픽 등 주요 지표에 대해 경고·위험 단계별 임계치를 설정할 수 있으며, SNMP Trap이나 Syslog 기반의 이벤트도 실시간으로 감지됩니다.
알림 수신 채널은 이메일, SMS, 모바일 앱 푸시 외에도 Slack, Telegram, Teams, Jandi, Webhook 등 다양한 3rd 파티 플러그인을 통해 경고 알림을 받을 수 있습니다. 요일별, 시간별 알림 수신 여부도 설정할 수 있어 운영 환경에 맞는 유연한 알림 체계를 구성할 수 있습니다.
Q4. 와탭 NMS는 APM, 서버 모니터링 등 다른 와탭 제품과 어떻게 연계되나요?
와탭 NMS는 애플리케이션 성능부터 네트워크 장비 상태까지 한 대시보드에서 관리할 수 있어, 장애 발생 시 전체 스택을 빠르게 분석하고 원인을 파악할 수 있습니다. 와탭은 단일 플랫폼에서 APM, 서버, 데이터베이스, 쿠버네티스, 로그, 네트워크(NMS) 등 다양한 모니터링 제품을 제공하며, 메트릭스·트레이스·로그 정보를 통합하여 문제 발생 시 빠른 원인 분석 및 조치가 가능한 옵저버빌리티 환경을 구현합니다.
예를 들어 특정 서비스에서 응답 지연이 발생했을 때 APM에서 트랜잭션 병목을 확인하고, NMS에서 해당 구간의 네트워크 상태를 동시에 점검함으로써 원인이 애플리케이션인지 네트워크인지 빠르게 판별할 수 있습니다.

.webp)



.png)





