.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
OpenTelemetry GenAI 시맨틱 컨벤션과 LLM 옵저버빌리티 표준
새로운 기술이 퍼질 때마다 그것을 관측하는 방식은 비슷한 단계를 거칩니다. 처음에는 팀마다 벤더마다 제 방식으로 데이터를 기록하다가, 제각각인 기록 탓에 운영이 번거로워지고 나서야 공통 어휘로 모입니다. HTTP가 그랬고, 분산 트레이싱이 그랬습니다. 3년 전 LLM 애플리케이션을 관측하던 상황도 똑같았습니다. 어떤 곳은 토큰 수를 prompt_tokens로 기록하고, 다른 곳은 input_token_count라고 불렀습니다. 응답 지연을 측정하는 속성명도 제각각이었습니다. 같은 현상을 보면서 서로 다른 이름을 붙이던 초기 인프라 모니터링 시대의 혼선이, AI 영역에서 다시 시작되고 있었습니다.
OpenTelemetry(이하 OTel)가 이 문제를 풀려고 GenAI(Generative AI) SIG(Special Interest Group)를 만든 것이 2024년 4월입니다. 그로부터 2년이 지난 지금, LLM 호출에 어떤 이름을 붙이고 무엇을 기록할지 정하는 공통 어휘가 빠르게 정리됐습니다. 이 글이 다루는 것은 그 표준 자체입니다. LLM 옵저버빌리티가 무엇이고 왜 필요한지는 LLM 옵저버빌리티란 무엇인가에서 다뤘습니다. 여기서는 OTel GenAI 시맨틱 컨벤션이 어디까지 왔는지, 실제로 어떤 식별자를 정의하는지, LLM을 운영하거나 도입을 검토하는 팀이 무엇을 짚어야 하는지 1차 출처를 기준으로 정리합니다.
OpenTelemetry GenAI 시맨틱 컨벤션은 어떻게 만들어졌나
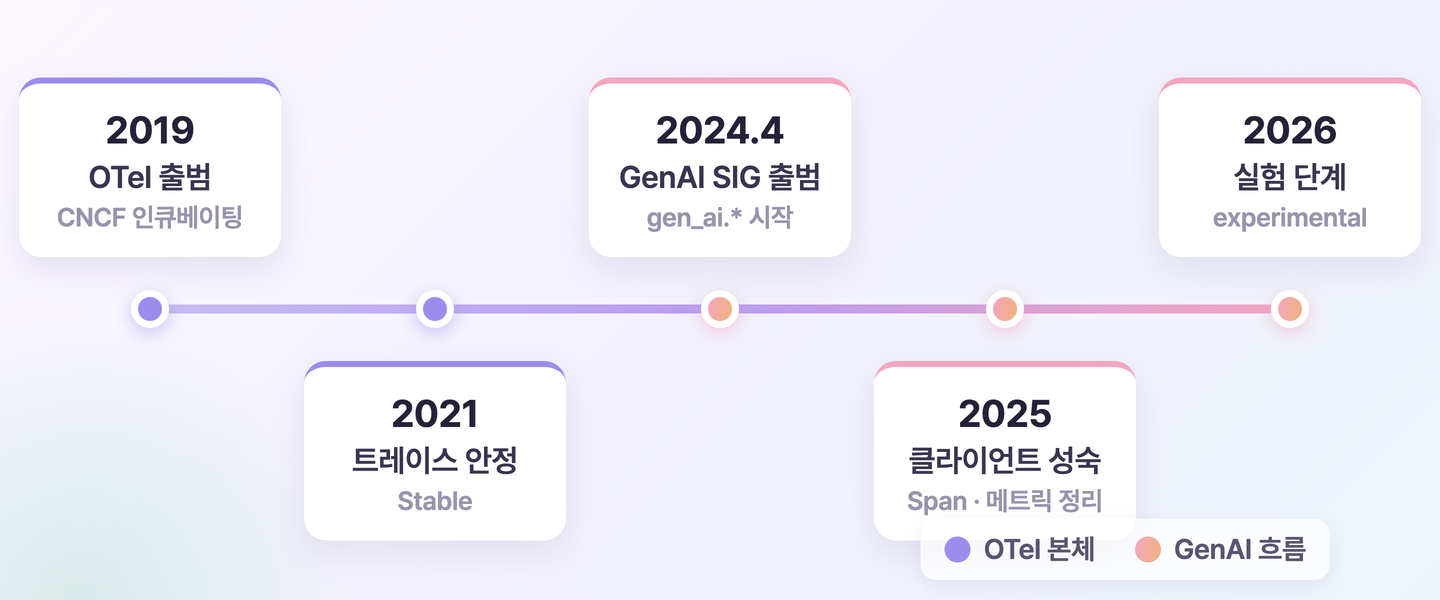
지금의 GenAI 표준이 앞으로 어떻게 굳어갈지 가늠하려면 OTel 본체가 걸어온 길을 먼저 보는 편이 빠릅니다. OTel은 분산 트레이싱의 파편화 문제를 풀려고 OpenTracing과 OpenCensus를 통합한 프로젝트입니다. 2019년 CNCF(Cloud Native Computing Foundation) 인큐베이팅 프로젝트로 출발해, 2021년 트레이스가 안정 단계(Stable)로 올라섰고, 이후 메트릭과 로그로 영역을 넓혀왔습니다. 그 과정에서 줄곧 지켜 온 설계 원칙이 하나 있습니다. 데이터를 어떻게 수집하느냐가 아니라, 무엇을 어떤 이름으로 기록하느냐를 표준으로 정한다는 것입니다.
이 "어떤 이름으로 기록할지"를 정한 규약이 시맨틱 컨벤션(Semantic Conventions)입니다. HTTP 호출이라면 http.request.method나 http.response.status_code 같은 키가 여기에 해당합니다. 어느 언어, 어느 라이브러리에서 계측하든 같은 의미는 같은 키에 담기로 한 약속입니다.
2023년 9월, LLM 호출용 시맨틱 컨벤션 제안이 커뮤니티에 처음 올라왔습니다. ChatGPT 출시 이후 LLM 애플리케이션이 급증하면서 "이걸 어떻게 관찰할 것인가"라는 질문이 실무에서 쏟아지던 시점과 겹칩니다. 2024년 4월 GenAI SIG가 공식 출범했고, 그해 말 Span과 Metric, Event 세 갈래에 걸친 GenAI 속성 체계의 윤곽이 잡혔습니다.
2025년을 지나면서 클라이언트 Span과 메트릭 정의가 빠르게 정리됐습니다. gen_ai.request.model, gen_ai.usage.input_tokens, gen_ai.client.operation.duration 같은 식별자가 사실상 업계의 공통 어휘로 굳었습니다. 이 속성을 쓰면 OpenAI든 Anthropic이든 자체 호스팅 모델이든 같은 형태의 관측 데이터로 들여다볼 수 있습니다.
아직 Stable은 아니다
도입을 판단할 때는 표준 상태를 먼저 분명히 해두는 편이 안전합니다. 2026년 6월 초 기준으로 GenAI 시맨틱 컨벤션은 OTel 시맨틱 컨벤션 문서 아래에 들어와 있고, 아직 실험 단계(experimental·Development)입니다. 안정 단계는 아닙니다. 키 이름이 바뀔 수 있고, 새 속성이 추가되거나 빠질 수도 있습니다.
여기서 판단은 둘로 나뉩니다. "공식 Stable이 아니니 안정 선언까지 기다린다"가 한쪽, "모여드는 표준을 지금 이해하되 키 변경 가능성은 감안한다"가 다른 쪽입니다. 어느 쪽이 맞는지는 환경에 따라 다르지만, 20년 가까이 관측 영역의 표준이 정착하는 과정을 지켜본 입장에서 보면 한 가지 패턴은 분명합니다. 관측 규약은 공식 안정 선언보다 시장이 먼저 움직이는 경우가 많습니다. 다음 절에서 보듯 주요 플랫폼과 프레임워크는 이미 이 컨벤션 위에서 제품을 만들고 있습니다. 그래서 실무에서는 후자, 곧 표준을 지금 익혀두되 변경 여지를 염두에 두는 쪽이 균형점에 가깝습니다.
이미 시장은 이 표준으로 모이고 있다
표준이 실제로 쓰이는지는 공식 Stable 지정 여부보다, 도구들이 이를 얼마나 받아들였는지에서 더 분명히 드러납니다.
Google Cloud, AWS, Azure 같은 클라우드 제공사가 GenAI 관측 데이터를 이 컨벤션 형식으로 받아들이고 있습니다. 주요 AI 에이전트 프레임워크도 2025년 하반기부터 OTel GenAI 형식으로 관측 데이터를 내보내는 기능을 기본으로 포함하기 시작했습니다.
서로 다른 진영이지만 계측 규약만큼은 같은 표준을 사용합니다. 계측 단계에서 특정 벤더의 독자 SDK에 종속되면 나중에 분석 도구를 바꿀 때 수집 코드를 다시 짜야 하지만, 공통 컨벤션 위에서는 그 비용이 들지 않기 때문입니다.
표준이 다루는 범위도 넓어지고 있습니다. 단순 LLM 호출 추적을 넘어, 에이전트가 도구를 부르고 메모리를 쓰는 멀티스텝 워크플로우용 컨벤션도 2025년 하반기부터 빠르게 정비되는 중입니다.
표준이 정착하면 무엇이 편해지나
운영자와 의사결정자 관점에서 표준이 주는 실익은 두 가지입니다.
- 도구 교체: OTel 표준 방식으로 LLM 애플리케이션을 계측해두면, 백엔드 옵저버빌리티 플랫폼을 나중에 바꾸거나 더해도 수집 코드를 다시 쓰지 않아도 됩니다.
- 데이터 병합: 직접 수집한 OTel 트레이스와 벤더 도구의 데이터를 같은 분석 축에서 합칠 수 있습니다.
무엇을 봐야 할지도 더 또렷해집니다. GenAI 시맨틱 컨벤션이 정의하는 관찰 영역은 크게 세 가지입니다.
- 성능: 첫 토큰까지 걸리는 시간(TTFT, Time To First Token), 응답 완료까지의 지연, 요청 지연 분포
- 비용: 입력·출력·캐시 토큰 수, 모델별·호출 유형별 누적
- 품질: 응답 종료 사유(
finish_reasons), 에러 유형, 도구 호출 성공 여부
이 세 축을 표준 식별자로 어떻게 표현하는지 이제 구체적으로 봅니다. 여기서부터가 도구를 비교하거나 계측을 직접 설계할 때 마주하는 부분입니다.
gen_ai.* 식별자, Span 속성 편
LLM 호출 한 건은 OTel에서 Span 하나로 표현됩니다. Span 이름 규약부터 봅니다.
Span에 붙는 속성을 표준에서는 네 단계로 나눕니다. Required(필수), Conditionally Required(조건부 필수), Recommended(권장), Opt-In(민감 데이터, 명시적 동의)입니다. 이 분류를 보면 도구가 무엇을 항상 보장하고 무엇을 선택적으로 다루는지 가늠할 수 있습니다.
Required, 모든 GenAI Span이 반드시 갖는 두 가지
gen_ai.operation.name의 표준 값은 chat, text_completion, embeddings, generate_content, create_agent, invoke_agent, invoke_workflow, retrieval, execute_tool입니다. 이름에서 읽히듯 단순 추론(chat)부터 에이전트 호출(invoke_agent), 도구 실행(execute_tool), RAG(Retrieval-Augmented Generation)의 검색 단계(retrieval)까지 한 표준 안에 들어와 있습니다.
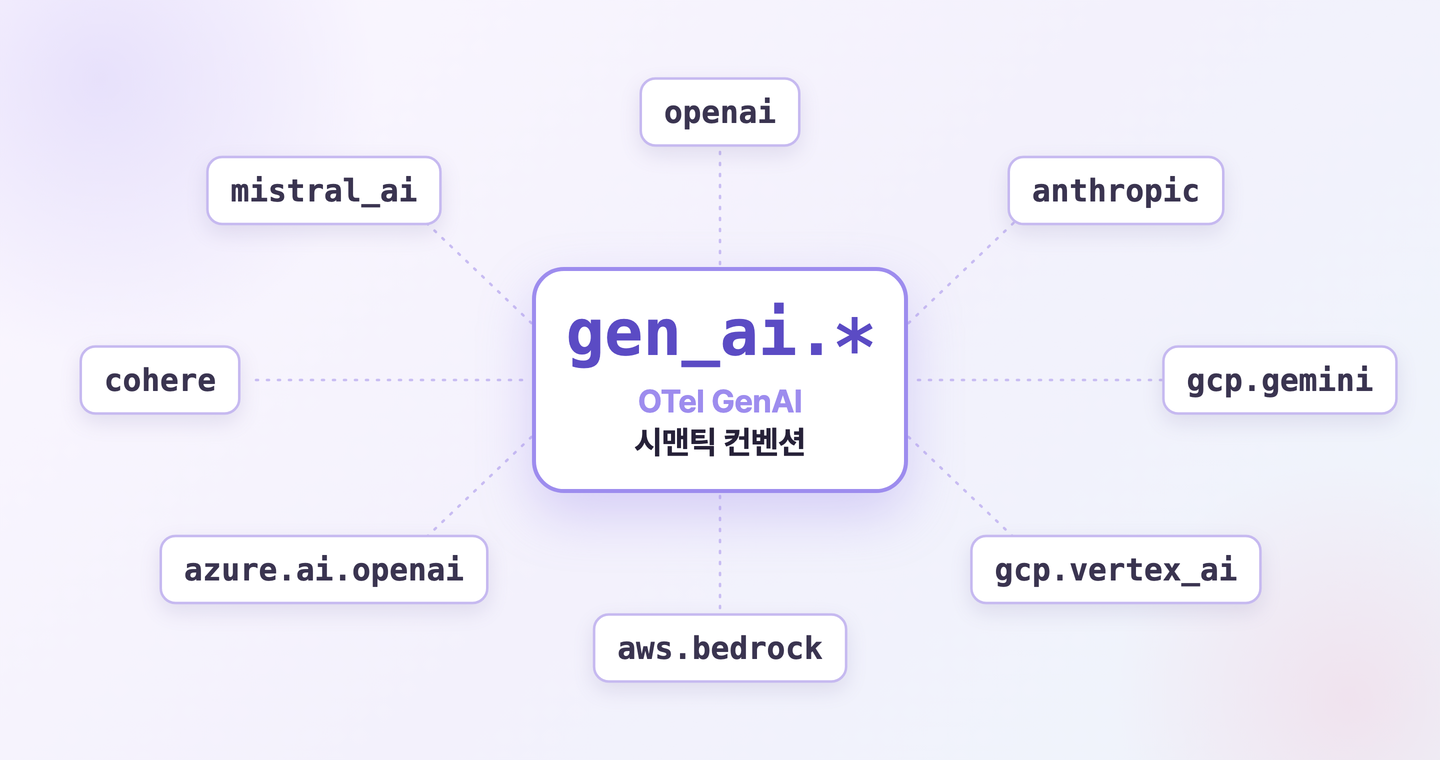
gen_ai.provider.name의 표준 값으로는 openai, anthropic, gcp.gemini, gcp.vertex_ai, aws.bedrock, azure.ai.openai, azure.ai.inference, cohere, mistral_ai 등을 정의합니다.
Conditionally Required, 상황에 따라 반드시
request.model과 response.model을 나눠 둔 이유는 둘이 종종 다르기 때문입니다. gpt-4o로 요청해도 응답에는 gpt-4o-2024-08-06처럼 구체 버전이 찍혀 돌아옵니다. 모델 라우팅이나 버전별 비교 분석에는 둘 다 필요합니다.
예를 들어 다음과 같은 Span이 기록될 수 있습니다.
{
"gen_ai.operation.name": "chat",
"gen_ai.provider.name": "openai",
"gen_ai.request.model": "gpt-4o",
"gen_ai.response.model": "gpt-4o-2024-08-06",
"gen_ai.usage.input_tokens": 120,
"gen_ai.usage.output_tokens": 45
}운영자는 이런 정보를 이용해 모델별 토큰 사용량, 응답 시간, 에러율을 비교할 수 있습니다.
Recommended, 넣어두면 디버깅이 편한 것
토큰 수가 Required가 아니라 Recommended에 있다는 점은 처음 보면 의외입니다. 프로바이더 응답에 토큰 수가 빠질 수도 있다는 사정을 표준이 반영한 결과입니다. 실무에서는 비용을 추적해야 하니 운영자가 거의 항상 함께 수집합니다.
Opt-In, 민감 데이터는 명시적 설정 필요
프롬프트와 응답 본문 자체는 기본 수집 대상이 아닙니다. 크기가 크고 민감 정보가 섞이기 쉬워, 운영자가 명시적으로 켤 때만 들어갑니다. 보안 검토 단계에서도 이 구분을 그대로 두는 편이 무난합니다.
gen_ai.* 식별자, 메트릭 편
같은 LLM 호출을 시계열로 집계하는 메트릭은 따로 정의합니다. 메트릭 키와 Span 속성 키는 들어가는 위치가 다르니 헷갈리지 않게 정리합니다.
여기서 client는 LLM을 호출하는 애플리케이션 쪽, server는 LLM을 서빙하는 프로바이더 쪽입니다. 자체 호스팅 모델이 아니면 보통 client 메트릭만 수집합니다.
gen_ai.client.token.usage 메트릭에는 gen_ai.token.type 속성이 붙어 input과 output을 구분합니다. 정리하면 토큰 수는 Span에서는 gen_ai.usage.input_tokens와 gen_ai.usage.output_tokens 두 속성으로 들어가고, 메트릭에서는 gen_ai.client.token.usage 한 곳에 token.type 라벨로 입출력을 나눕니다. 같은 데이터를 두 방식으로 표현한다는 점이 처음에 가장 헷갈립니다.

카디널리티, 도입 전에 확인할 한 가지
메트릭을 다룰 때 운영자가 미리 챙겨야 할 함정이 있습니다. gen_ai.request.model이나 gen_ai.response.model처럼 값이 자주 바뀌는 키를 메트릭 라벨로 그대로 쓰면 카디널리티(Cardinality, 라벨 조합의 수)가 빠르게 늘어납니다. 모델 버전이 매주 추가되는 환경에서는 이런 라벨 탓에 메트릭이 폭증하기 쉽습니다.
표준은 이렇게 자주 바뀌는 키를 옵션 속성으로 두지만, 수집 도구가 모델명을 메트릭 라벨에 실제로 어떻게 반영하는지는 제품마다 다릅니다. 도입 검토 단계에서 이 처리 방식을 확인해 두면, 운영 중 메트릭 비용이 예측을 벗어나는 일을 피할 수 있습니다.
운영 관점과 gen_ai.* 식별자 매핑
앞서 본 성능·비용·품질 세 축을 실제 운영에서 들여다볼 때 어떤 식별자를 보게 되는지 아래에 정리했습니다. 표준 식별자가 운영 화면의 어떤 항목으로 이어지는지 한눈에 보기 위한 매핑입니다.
마지막 줄이 특히 중요합니다. LLM 호출 한 건은 따로 있는 이벤트가 아닙니다. 그 호출을 부른 백엔드 API, 함께 일어난 DB 조회, RAG라면 벡터 스토어 검색이 같은 흐름 안에 있습니다. GenAI Span을 상위 트랜잭션 트레이스의 한 단계로 놓고 보면, LLM 응답이 느릴 때 그 원인이 모델 자체인지 앞단의 검색 단계인지 같은 화면에서 가려낼 수 있습니다. OTel 표준 식별자를 쓰는 가장 큰 실익이 여기에 있습니다.
도입 검토자를 위한 점검 질문 5개
LLM 옵저버빌리티 도구를 비교할 때, 다음 다섯 질문으로 OTel GenAI 호환 정도를 빠르게 가늠할 수 있습니다.
gen_ai.operation.name과gen_ai.provider.name을 표준 값으로 받아 그룹화·필터링이 되는가request.model과response.model을 분리해서 보여주는가- 토큰 데이터가 Span 속성과 메트릭 양쪽에 일관되게 들어가는가
- Opt-In 속성(시스템 프롬프트·입출력 본문)에 권한 분리가 적용되는가
- LLM Span이 백엔드·인프라 트레이스와 같은 트랜잭션 흐름으로 이어지는가
다섯 질문 모두 "예"가 나오는 도구는 생각보다 많지 않습니다. 그래서 표준을 받아들이는 정도와 풀스택 트레이스 통합 수준을 함께 보는 편이 좋습니다.
마치며
OTel이 분산 트레이싱을 하나의 표준으로 통합했던 궤적을 따라가 보면, GenAI 영역도 같은 길 위에 있습니다. 공식 Stable 선언보다 시장이 먼저 움직이고, 그 흐름이 굳은 뒤에야 표준 문서가 뒤따릅니다. 분산 트레이싱 때 일찍 공통 규약을 받아들인 팀과 자체 포맷을 고집하다 나중에 다시 계측한 팀의 비용 차이를 떠올려 보면, 지금 LLM 영역에서 같은 선택지가 다시 놓여 있는 셈입니다.
2026년 6월 초 현재 GenAI 시맨틱 컨벤션은 아직 실험 단계입니다. 그렇더라도 gen_ai.operation.name·provider.name·request.model·usage.input_tokens 같은 식별자는 도구를 비교할 때나 계측을 직접 설계할 때나 똑같이 마주합니다. 표준이 정착하기 전이라도 이 식별자에 익숙해 두는 것이, LLM 도입과 운영 결정의 폭을 넓히는 가장 적은 비용의 준비입니다. 그리고 그 실익은 LLM 호출 하나를 잘 보는 데서 끝나지 않습니다. 같은 트레이스 축 위에서 LLM 호출이 그것을 부른 백엔드 API, DB 조회, 인프라 단계와 한 흐름으로 이어질 때, 비로소 운영자가 원인을 한눈에 가려냅니다.
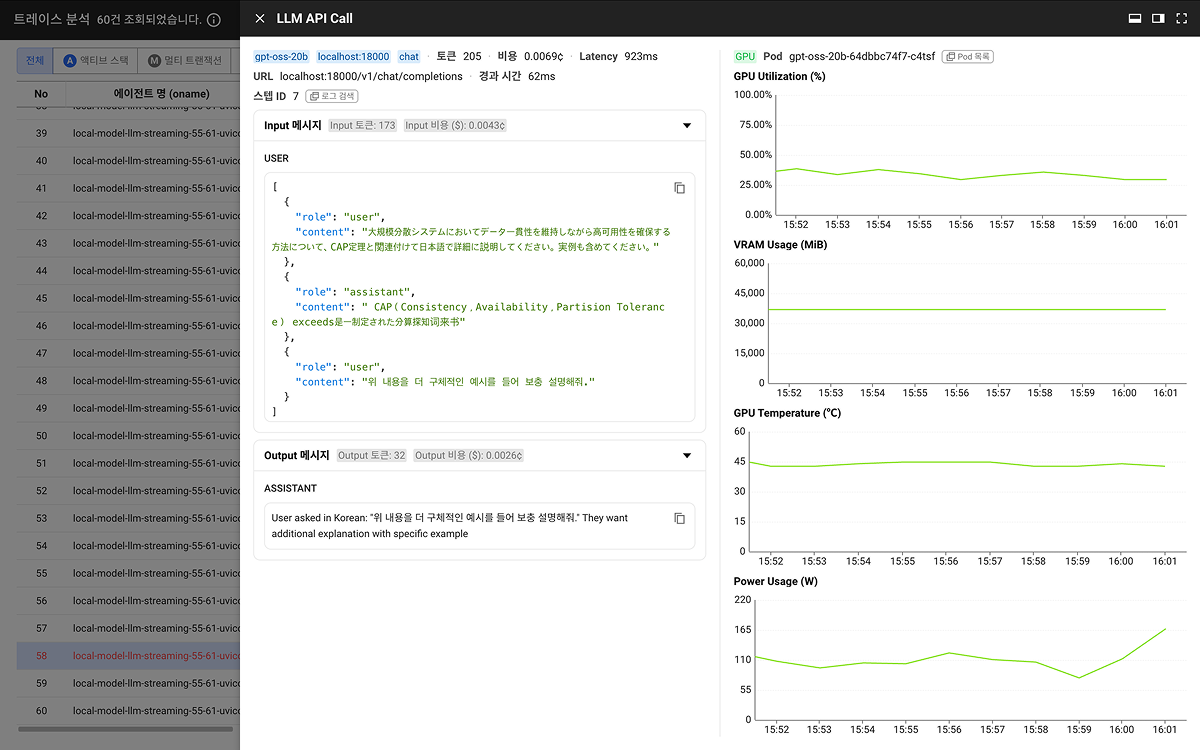
와탭 LLM Observability도 LLM 호출을 백엔드·인프라와 같은 풀스택 트랜잭션 트레이스에서 함께 봅니다. LLM 호출이 트랜잭션에 실제로 어떻게 이어지는지는 와탭 LLM Observability에서 확인할 수 있습니다.
더 읽을거리
- OpenTelemetry GenAI Semantic Conventions. 1차 출처. Span·Metric·Event 정의와 현재 상태
- GenAI Spans. Span 속성 전체 목록과 Required·Recommended 분류
- GenAI Metrics. Histogram 메트릭 정의와 라벨
- LLM 옵저버빌리티란 무엇인가. 개념·필요성. 이 글이 다루는 OTel 표준의 배경이 되는 입문 편
- 와탭 LLM Observability 소개