.svg)
%201.svg)

담당자가 프로모션 코드를 발송해 드립니다.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
와탭을 경험해 보세요.
WhaTap AI를 경험해 보세요.
Apache 모니터링, 와탭으로 Worker 가시성 확보

Apache HTTP Server는 30년 가까이 웹 인프라의 한 축을 지켜왔습니다. 풍부한 모듈 생태계, 검증된 안정성, 그리고 mod_php나 mod_wsgi처럼 애플리케이션을 직접 임베드할 수 있는 유연성까지 갖추고 있어 지금도 수많은 프로덕션 환경에서 현역으로 동작하고 있습니다.
이 글은 특히 다음과 같은 분들을 위해 작성했습니다.
mod_php·mod_wsgi또는mod_proxy_fcgi+ PHP-FPM 조합으로 애플리케이션을 운영 중인 팀- 레거시 Apache 환경을 안정적으로 유지·운영해야 하는 인프라 담당자
scoreboard is full같은 Worker 관련 에러를 한 번이라도 마주친 적 있는 운영자
Apache 운영자가 마주치는 모니터링의 풍경은 다른 웹 서버와 본질적으로 다릅니다. Nginx 같은 이벤트 기반 서버에서는 "활성 커넥션 수"만 봐도 대략적인 부하를 짐작할 수 있지만, Apache는 Worker(프로세스/스레드)라는 명확한 운영 단위가 존재하기 때문입니다.
Apache 운영자가 새벽에 가장 자주 마주치는 에러 메시지를 떠올려봅시다.
[mpm_event:error] AH00485: scoreboard is full, not at MaxRequestWorkers이 메시지를 본 적이 있다면, Apache 모니터링이 왜 다른 차원의 문제인지 이미 알고 있는 셈입니다. 이는 단순한 트래픽 폭증이 아니라 Worker 상태 분포의 문제입니다. Worker가 어떤 상태로 분포되어 있는지 알 수 없다면 이 에러를 제대로 진단하기 어렵습니다.
이번 글에서는 Apache 모니터링이 왜 Worker 가시성 중심으로 이루어져야 하는지, 그리고 와탭(WhaTap)의 OpenMetrics Apache 템플릿이 이 문제를 어떻게 한 화면에서 시각화하는지 살펴봅니다.
Apache 모니터링이 까다로운 이유
1. Apache의 본질은 Worker, 단순 RPS만 봐서는 안 됩니다
Apache는 MPM(Multi-Processing Module) 아키텍처를 기반으로 동작합니다. prefork, worker, event 세 가지 모드 중 하나를 선택하게 되며, 각 모드마다 프로세스와 스레드의 조합이 다릅니다.
- prefork: 프로세스만 사용하는 방식입니다. 1개 프로세스가 1개 요청을 처리합니다. thread-safe하지 않은 라이브러리와의 호환성, 그리고 한 요청의 크래시가 다른 요청에 영향을 주지 않는 프로세스 격리가 장점입니다.
- worker: 프로세스와 스레드를 함께 사용하는 하이브리드 방식입니다. 1개 프로세스가 여러 스레드를 통해 요청을 처리하며, 메모리 효율성과 동시성을 모두 확보할 수 있습니다.
- event: worker 기반에 비동기 처리를 더한 모드입니다. keep-alive 커넥션을 별도 리스너 스레드가 처리해, idle keep-alive가 Worker를 점유하지 않도록 합니다. Apache 2.4 이상의 기본 MPM입니다.
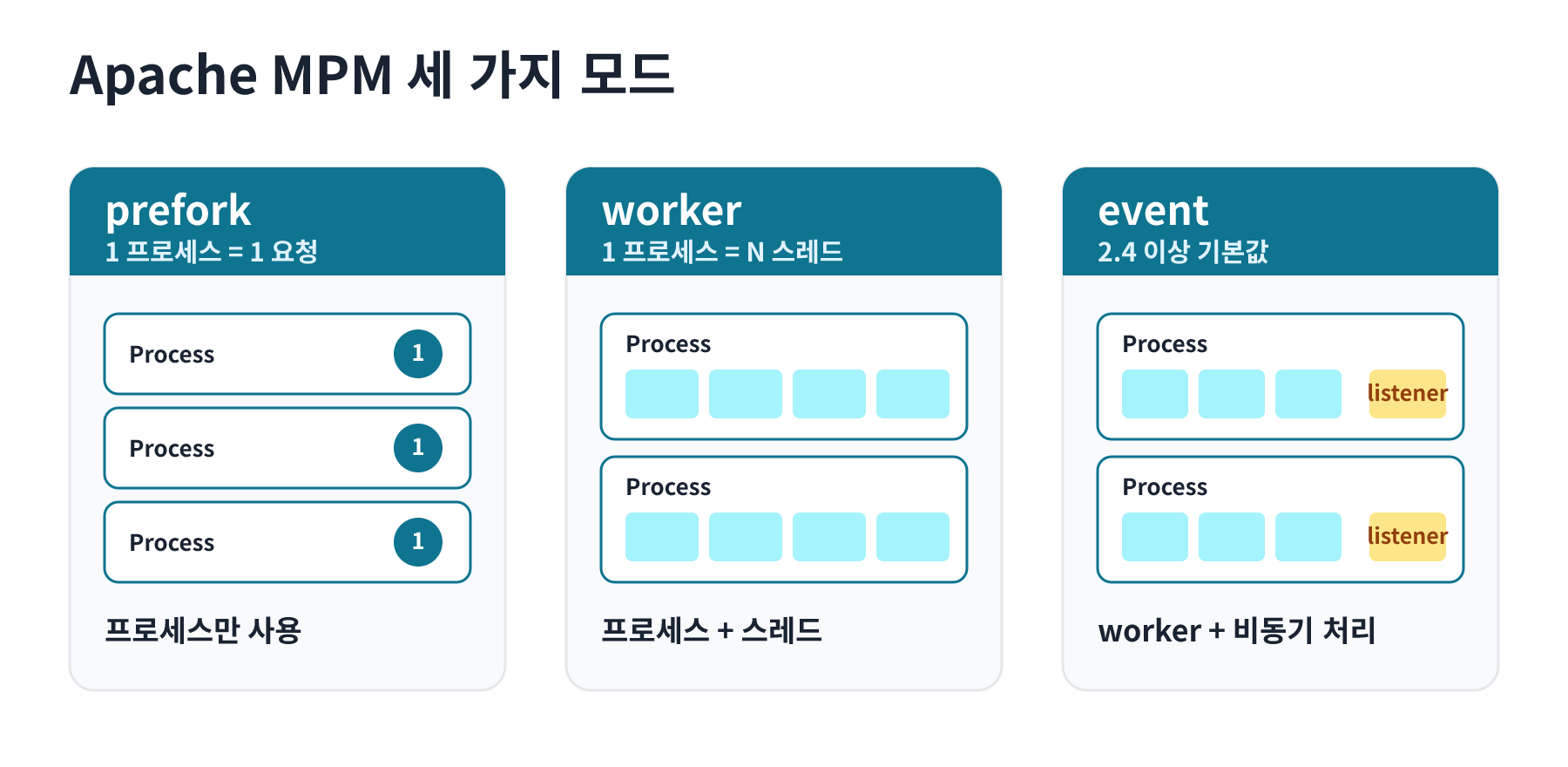
동시 처리 한도는 prefork에서는 MaxRequestWorkers = 프로세스 수로, worker/event에서는 MaxRequestWorkers = ServerLimit × ThreadsPerChild로 계산됩니다. 이 한도를 기준으로 Worker 풀의 여유와 상태 분포를 추적해야 한다는 점이 Nginx 같은 이벤트 기반 서버와 본질적으로 다른 지점입니다.
이 구조 때문에 Apache는 MaxRequestWorkers라는 명확한 동시 처리 한도를 갖습니다. 트래픽이 이 한도를 초과하면 요청이 큐에 쌓이거나 거부됩니다. 따라서 Apache를 안정적으로 운영하려면 "지금 Worker 풀이 얼마나 차 있는가", "각 Worker가 어떤 상태인가"를 실시간으로 추적해야 합니다. 이는 이벤트 기반 서버에는 없는 차원의 가시성 요구입니다.
2. Scoreboard, 강력하지만 텍스트 한 줄로는 부족합니다
Apache의 mod_status는 운영자에게 매우 풍부한 정보를 제공합니다. 그중 가장 독특한 것이 Scoreboard입니다. 각 Worker의 현재 상태를 한 글자 코드로 노출하는 방식입니다.
_RRR_RRRRRKR_WR___R_KWW_RRR_RR_RWRWR_R_RWRR_RK__K_RRRRRR__RRRWRR
_RRR__W_K__RR___WR___RW_RRR_WRR__WK_R_RKR__R_RRR_KRWWWRR_RRRW___각 글자의 의미는 다음과 같습니다. (아래 표는 table1-scoreboard-codes.html 파일로 별도 제공합니다.)
위 비중은 일반적인 웹 트래픽 환경을 기준으로 한 참고치이며, 실제 운영 환경에 따라 달라질 수 있습니다. 중요한 것은 자기 환경의 평상시 분포를 베이스라인으로 파악하고 있는 것입니다.
문제는 이 정보가 운영 도구 관점에서는 그대로 활용하기 어렵다는 점입니다. 텍스트 그리드를 사람이 직접 세어야 하고, 시간축에 따른 추이는 더더욱 파악하기 어렵습니다. "지금 K 상태가 너무 많은가?", "어제와 비교하면 어떤가?" 같은 질문에는 답하기 어려운 형태입니다.
3. "scoreboard is full" 진단은 상태 분포 추이가 핵심입니다
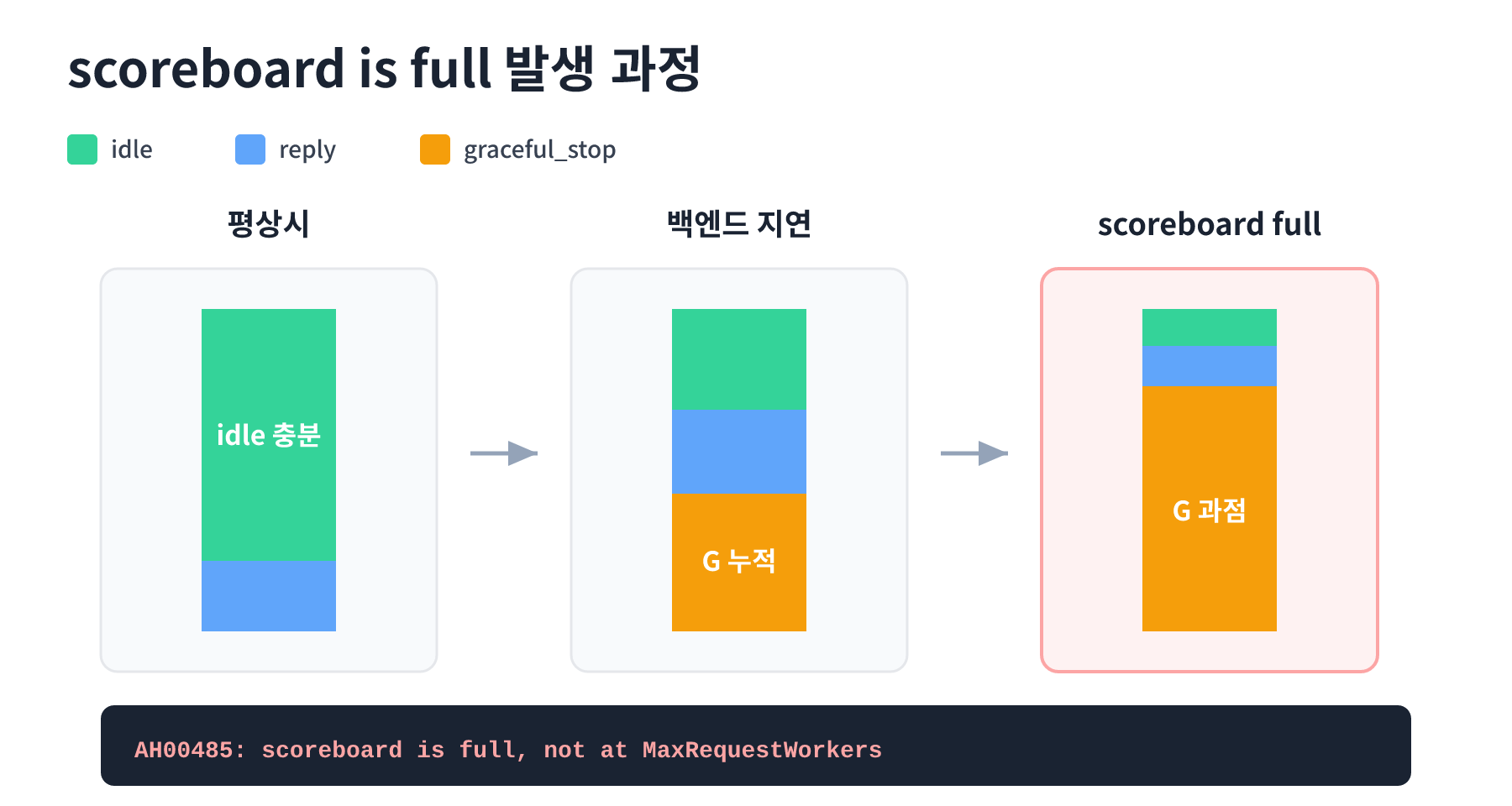
앞서 언급한 scoreboard is full, not at MaxRequestWorkers 에러를 들여다보면 Apache 모니터링의 본질이 드러납니다.
Apache 공식 문서(mpm_event)는 이 상황을 다음과 같이 설명합니다. scoreboard가 가득 찼지만, 즉 모든 스레드가 idle 상태가 아니지만, 실제로 처리 중인 활성 요청 수는 MaxRequestWorkers에 도달하지 않은 경우 일부 스레드가 새 요청 처리를 막고 있다는 의미입니다. 이때 막혀 있는 스레드는 ListenBacklog 한도 안에서 큐에 대기하게 됩니다. 또한 공식 문서는 mpm_event가 graceful 종료 과정에서 keep-alive 커넥션을 안전하게 닫기 위해 스레드를 유지하며, scoreboard가 가득 찬 상황에서는 추가 프로세스의 graceful 종료를 억제하도록 동작한다고 설명합니다.
즉, 이 에러를 진단하려면 단순한 카운터가 아니라 "각 상태별 Worker 수가 시간축에서 어떻게 변하는가"를 봐야 합니다. G(graceful finishing) 상태가 점점 누적되고 있다면 keep-alive 튜닝이나 백엔드 응답 시간 개선이 필요할 수 있고, K 상태가 비정상적으로 많다면 keep-alive 타임아웃 조정이 필요할 수 있습니다. 이런 진단을 텍스트 Scoreboard만 보고 수행하기는 거의 불가능합니다.
4. 직접 구축은 결국 Apache Exporter와 패널 설계의 반복입니다
Apache를 Prometheus 생태계에 연결하는 표준 도구는 apache_exporter입니다. mod_status의 ?auto 엔드포인트를 파싱해 OpenMetrics 호환 메트릭을 노출합니다. 이렇게 수집된 메트릭으로 Grafana 대시보드를 만들 수 있습니다.
문제는 그 "만들 수 있습니다"가 만만치 않다는 점입니다. Worker 상태별 분포를 의미 있게 시각화하려면 다음과 같은 작업이 필요합니다.
- 각 상태(
_ R W K D C L G I)별 PromQL 작성 - 시계열 막대그래프 패널 구성
- Busy/Idle 합계 별도 추출
MaxRequestWorkers한도와 함께 표시
이 패널 설계만으로도 며칠의 작업이 필요할 수 있고, 어떤 상태를 같은 차트에 묶을 것인가에 대한 판단에도 운영 경험이 필요합니다. 결국 운영팀이 본업 대신 Grafana 대시보드를 설계하고 다듬는 시간이 누적됩니다.
와탭 OpenMetrics Apache 템플릿, Worker 가시성을 메인으로
와탭 OpenMetrics Apache 템플릿은 위 복잡성을 운영자가 진짜 봐야 할 4개 영역으로 정리해 한 화면에 제공합니다. 특히 다른 웹 서버 템플릿에는 없는 Worker Status 영역이 핵심입니다.
1. Overview, 4대 핵심 카드 메트릭

대시보드 최상단에는 운영자가 가장 먼저 확인해야 할 4개 카드가 배치됩니다. 아래 표는 table2-overview-cards.html 파일로 별도 제공합니다.
특히 Process Count가 카드 메트릭의 가장 앞에 배치된 점이 인상적입니다. 다른 웹 서버 템플릿에는 거의 등장하지 않는 지표지만, Apache에서는 가장 기본적인 헬스 체크 항목입니다. MPM 모드에 따라 적정 프로세스 수가 정해져 있고, 이 값이 비정상이면 즉시 의심해야 하기 때문입니다.
2. CPU Performance, Apache 자체의 CPU 점유율 분리

서버 전체의 CPU 사용률은 시스템 모니터링에서 확인할 수 있지만, Apache 프로세스가 그중 얼마를 차지하는지는 별도의 시야가 필요합니다. mod_php·mod_wsgi 같은 임베드 구성이든, mod_proxy_fcgi + PHP-FPM이나 mod_proxy_uwsgi 같은 분리 구성이든, "Apache 자체의 부하"와 "애플리케이션 런타임의 부하"는 항상 분리해서 봐야 합니다.
- CPU Load: 시스템 전체 부하
- Apache CPU Utilization(%): Apache 워커들이 점유하는 CPU 비율
이 둘을 분리해서 보면 "전체 CPU는 높은데 Apache 점유율은 낮다"는 패턴을 즉시 식별할 수 있습니다. 이런 경우 실제 부하의 원인은 백엔드 애플리케이션이거나, 같은 호스트의 다른 프로세스일 가능성이 높습니다.
3. Request & Response, 트래픽과 응답의 다각도 분석
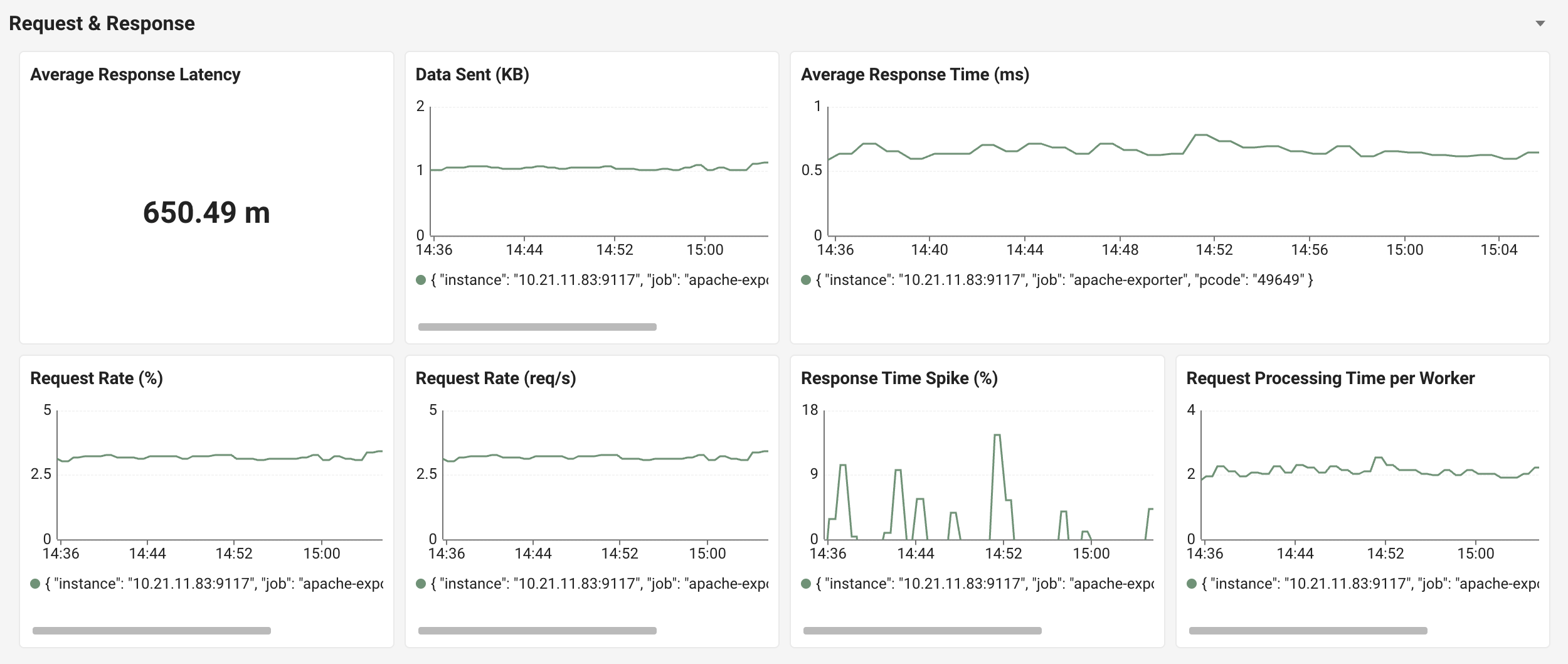
요청과 응답의 흐름을 7개 패널로 입체적으로 보여줍니다.
- Average Response Latency: 응답 지연 요약 카드
- Average Response Time(ms): 응답 시간 시계열
- Data Sent(KB): 전송 데이터량
- Request Rate(req/s): 초당 요청 수 시계열
- Request Rate(%): 전체 처리량 대비 비율
- Response Time Spike(%): 응답 시간 스파이크 패턴
- Request Processing Time per Worker: Worker당 평균 처리 시간
마지막 Request Processing Time per Worker는 Apache 운영의 핵심 진단 지표입니다. Worker 1개가 평균적으로 요청 하나를 얼마나 오래 잡고 있는지를 보여주는데, 이 값이 늘어나면 Worker 풀이 빠르게 소진되어 결국 scoreboard is full 에러로 이어질 수 있습니다.
4. Worker Status, 이 템플릿의 진짜 가치
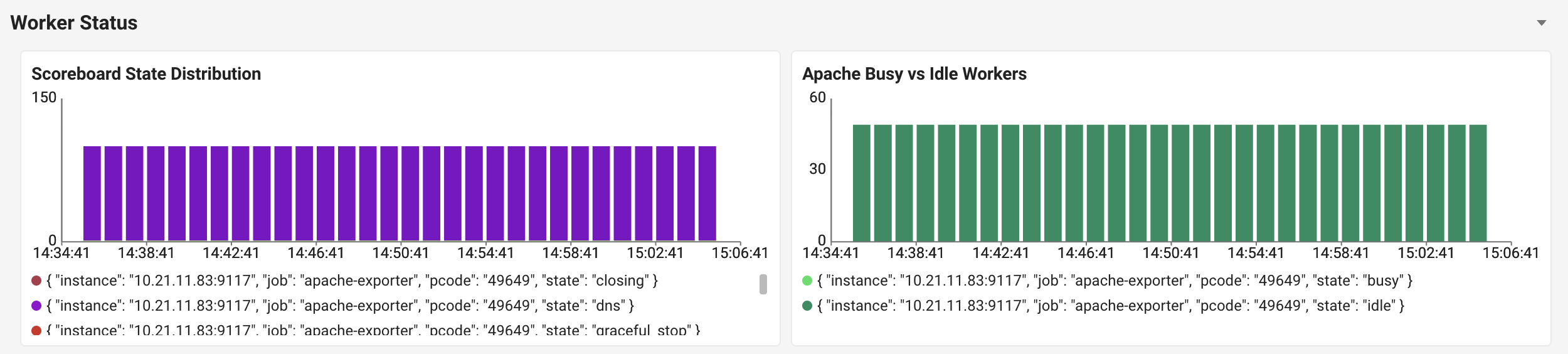
여기서 와탭 Apache 템플릿은 단순 메트릭 대시보드를 넘어선 가치를 발휘합니다.
Scoreboard State Distribution
이 패널 한 장으로 답할 수 있는 운영 질문
G(graceful_stop)상태가 누적되고 있는가? → keep-alive 또는 장시간 요청 문제 의심K(keepalive)상태가 비정상적으로 많은가? →KeepAliveTimeout튜닝 필요D(dns)상태가 자주 등장하는가? → DNS 캐시 또는HostnameLookups설정 점검C(closing)상태가 시간이 갈수록 늘어나는가? → 클라이언트 연결 종료 패턴 이상_(idle/waiting)비중이 베이스라인 대비 급감했는가? → Worker 풀 소진 임박 신호
텍스트 Scoreboard를 매번 새로고침하며 직접 글자를 세는 방식과 비교하면, 운영 효율성의 차원이 다릅니다.
Apache Busy vs Idle Workers
scoreboard에서 파생된 apache_workers{state="busy"} / apache_workers{state="idle"} 메트릭을 가장 직관적인 두 카테고리로 보여주는 패널입니다. "Worker 풀이 얼마나 여유가 있는가"를 한눈에 확인할 수 있습니다.
운영자의 시선 동선을 고려하면 잘 설계된 구조입니다. 먼저 Busy vs Idle로 전체 상황을 파악하고, 이상 신호가 보이면 Scoreboard State Distribution으로 들어가 어떤 상태가 문제인지 확인하는 흐름입니다.

전 시나리오, "scoreboard is full" 에러 진단 5분
위 4개 영역이 한 화면에 통합되었을 때, Apache 운영자가 가장 두려워하는 에러를 어떻게 빠르게 진단할 수 있는지 따라가보겠습니다.
사전 정보, 평상시 베이스라인
이 환경의 평상시 Scoreboard 분포는 _ 65%, W 15%, K 10%, R 5%, 기타 5% 수준이었습니다. Request Processing Time per Worker는 평균 200ms 내외입니다.
T+0초, 알람 수신: "Apache: scoreboard is full, requests being queued."
T+30초, Overview 카드 확인: Process Count는 정상이고, Total Requests도 평소 수준입니다. 트래픽 폭증이 원인은 아니라는 1차 결론을 내릴 수 있습니다.
T+1분, Apache Busy vs Idle Workers 확인: Busy Worker가 MaxRequestWorkers 한도에 거의 도달했고, Idle Worker는 거의 0에 가깝습니다. Worker 풀이 소진된 것은 확인됐지만 왜 소진됐는지가 남아 있습니다.
T+1분 30초, Scoreboard State Distribution 분석: 시계열 누적 막대를 확인합니다. 평소 65%였던 _(idle/waiting)이 10% 수준으로 급감했고, 반대로 G(graceful_stop) 상태가 50%를 점유하고 있습니다.
T+2분, 패턴 인지: 이는 Apache 공식 문서가 설명하는 전형적인 패턴입니다. 장시간 실행되는 요청이나 느린 클라이언트로 인해 Worker가 graceful close 단계에서 멈춰 있는 상태입니다. 트래픽 자체가 아니라 백엔드 응답 지연이 실제 원인일 가능성이 높습니다.
T+3분, Request Processing Time per Worker로 검증: 이 패널의 값이 평소 200ms 대비 1초 이상으로 약 5배 증가해 있습니다. 가설이 맞습니다.
T+5분, 조치 결정 및 실행: 1차 조치로 KeepAliveTimeout을 15초에서 5초로 단축합니다. 동시에 백엔드(PHP-FPM 풀)의 슬로우 쿼리 로그를 확인해 장시간 실행 쿼리를 식별합니다.
T+15분, 회복 확인: 동일한 Scoreboard State Distribution 패널에서 G 비중이 10% 미만으로 떨어지고, _가 60%대로 회복됩니다. Busy/Idle 비율도 정상화됩니다. 근본 원인인 백엔드 쿼리는 튜닝으로 후속 처리합니다.
직접 구축한 환경에서 같은 진단을 했다면, mod_status 페이지를 새로고침해가며 텍스트 글자를 세고, Grafana에서 Busy/Idle만 보다가 실제 원인을 놓치는 경우가 흔합니다. 와탭 템플릿은 "상태 분포의 시계열 추이"를 메인 패널로 두기 때문에 진단 동선이 본질을 향하게 됩니다.
와탭 OpenMetrics Apache 템플릿을 써야 하는 5가지 이유
1. Worker Status 시각화, Apache 모니터링의 본질을 놓치지 않습니다
Apache는 다른 웹 서버와 달리 Worker가 운영의 본질입니다. 와탭 템플릿은 이 사실을 정확히 반영해 Worker Status 영역을 1급 지표로 다룹니다. mod_status의 텍스트 Scoreboard를 시계열 막대그래프로 풀어낸 시각화는 Apache 운영 경험이 있는 사람이라면 즉시 공감할 수 있는 화면입니다. 텍스트 글자를 세는 방식에서, 상태 분포의 추이를 한눈에 보는 방식으로 넘어갑니다.
2. Process Count를 첫 번째 카드로, Apache의 헬스 정의를 정확히 반영합니다
다른 웹 서버 모니터링 도구가 RPS나 응답 시간을 첫 카드로 두는 반면, 와탭 Apache 템플릿은 Process Count를 가장 앞에 배치합니다. 이는 단순한 UI 결정이 아니라 "Apache의 헬스란 무엇인가"에 대한 명확한 답입니다. MPM 모드별 적정 프로세스 수가 정해져 있고, 이 값이 비정상이면 다른 어떤 메트릭보다 먼저 확인해야 한다는 운영 노하우가 반영된 설계입니다.
3. Apache CPU와 시스템 CPU의 분리 시각화
mod_php·mod_wsgi처럼 애플리케이션을 임베드해서 운영하는 Apache 환경에서는 "CPU 부하의 진짜 주인이 누구인가"를 구분하는 것이 중요합니다. 와탭 템플릿은 시스템 CPU Load와 Apache CPU Utilization을 별도 패널로 나란히 배치해, 부하의 출처를 시각적으로 즉시 분리할 수 있게 합니다. 이를 PromQL로 직접 추출해 패널을 만들려면 까다로운 쿼리 작성이 필요한데, 템플릿은 이를 기본 제공합니다.
4. 7개 Request & Response 패널, 응답 지연의 다각도 진단
응답 지연을 진단할 때 단일 평균값만으로는 부족합니다. 와탭 템플릿은 7개 패널로 트래픽과 응답의 여러 측면을 동시에 보여줍니다. 특히 Request Processing Time per Worker는 Apache 환경에서 자주 활용되는 진단 지표로, Worker 풀 소진의 선행 지표 역할을 합니다. 이 패널이 기본 제공된다는 것은 운영자가 Apache 모니터링의 베스트 프랙티스를 자연스럽게 따르게 된다는 의미입니다.
5. apache_exporter 표준 메트릭을 즉시 활용
와탭 OpenMetrics Apache 템플릿은 표준 apache_exporter의 메트릭을 그대로 활용합니다. 기본 포트는 9117입니다. Prometheus 생태계에서 이미 검증된 Exporter를 그대로 쓸 수 있다는 의미입니다. 이미 Apache + apache_exporter 조합으로 메트릭을 노출하고 있다면, 와탭 OpenAgent에 엔드포인트만 등록해 위 4개 영역의 대시보드를 즉시 활용할 수 있습니다. 별도 마이그레이션이나 복잡한 재설정이 필요 없습니다.
직접 구축 vs 와탭 OpenMetrics Apache 템플릿
아래 비교 표는 table3-build-vs-whatap.html 파일로 별도 제공합니다.
결론: Apache 모니터링은 Worker로 시작해서 Worker로 끝납니다
Apache는 30년 가까이 검증된 안정성을 갖췄지만, 그 안정성은 Worker라는 명확한 운영 단위에 대한 가시성을 전제로 합니다. Worker가 어떤 상태로 분포되어 있는지, 풀이 얼마나 차 있는지, 어떤 상태가 누적되고 있는지를 모르면 Apache 운영은 추측에 의존하게 됩니다.
와탭 OpenMetrics Apache 템플릿은 mod_status의 텍스트 Scoreboard라는 강력하지만 다루기 어려운 데이터를, 운영자가 즉시 활용할 수 있는 시각화로 풀어냅니다. scoreboard is full 같은 까다로운 에러도 5분 안에 진단할 수 있는 환경을 별도 구축 공수 없이 제공합니다. Apache 모니터링은 결국 "Worker가 지금 어떤 상태에 있는가"라는 한 질문으로 수렴합니다.
15일 무료 체험으로 Apache 템플릿을 직접 확인해보세요. 와탭 OpenMetrics 도입 문의하기
함께 보면 좋은 자료
각주
- Apache HTTP Server 2.4 공식 문서, mpm_event 모듈: https://httpd.apache.org/docs/2.4/mod/event.html
- apache_exporter(Lusitaniae) 메트릭 정의: https://github.com/Lusitaniae/apache_exporter